We distribute pre-trained word vectors for 157 languages, trained on [*Common Crawl*](http://commoncrawl.org/) and [*Wikipedia*](https://www.wikipedia.org) using fastText.
where the file oov_words.txt contains out-of-vocabulary words.
In the text format, each line contain a word followed by its vector.
其中 oov_words.txt 文件包含了词汇表之外的单词
Each value is space separated, and words are sorted by frequency in descending order.
These text models can easily be loaded in Python using the following code:
在文本格式下,每一行包含一个单词,并且它的向量紧随其后
每个值都被空格分开,并且单词按照出现次数降序排列
只需要使用如下的代码,这些文本模型能在Python中轻松的下载:
```python
```python
importio
importio
...
@@ -33,21 +36,24 @@ def load_vectors(fname):
...
@@ -33,21 +36,24 @@ def load_vectors(fname):
returndata
returndata
```
```
### Tokenization
### 分词
我们使用 [*Stanford word segmenter*](https://nlp.stanford.edu/software/segmenter.html) 对汉语分词,使用 [*Mecab*](http://taku910.github.io/mecab/) 对日语分词,使用 [*UETsegmenter*](https://github.com/phongnt570/UETsegmenter) 对越南语分词
We used the [*Stanford word segmenter*](https://nlp.stanford.edu/software/segmenter.html) for Chinese, [*Mecab*](http://taku910.github.io/mecab/) for Japanese and [*UETsegmenter*](https://github.com/phongnt570/UETsegmenter) for Vietnamese.
For languages using the Latin, Cyrillic, Hebrew or Greek scripts, we used the tokenizer from the [*Europarl*](http://www.statmt.org/europarl/) preprocessing tools.
For the remaining languages, we used the ICU tokenizer.
More information about the training of these models can be found in the article [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893).
剩下的语言,我们用 ICU 进行分词
### License
想要了解更多关于这些模型训练的信息,可以查看这篇文章 [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893).
The word vectors are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
If you use these word vectors, please cite the following paper:
### 参考资料
如果你使用这些词向量,请引用下面这些文章:
E. Grave\*, P. Bojanowski\*, P. Gupta, A. Joulin, T. Mikolov, [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893)
E. Grave\*, P. Bojanowski\*, P. Gupta, A. Joulin, T. Mikolov, [*Learning Word Vectors for 157 Languages*](https://arxiv.org/abs/1802.06893)
...
@@ -60,66 +66,66 @@ E. Grave\*, P. Bojanowski\*, P. Gupta, A. Joulin, T. Mikolov, [*Learning Word Ve
...
@@ -60,66 +66,66 @@ E. Grave\*, P. Bojanowski\*, P. Gupta, A. Joulin, T. Mikolov, [*Learning Word Ve
}
}
```
```
### Evaluation datasets
### 评估数据集
The analogy evaluation datasets described in the paper are available here: [French](https://s3-us-west-1.amazonaws.com/fasttext-vectors/word-analogies/questions-words-fr.txt), [Hindi](https://s3-us-west-1.amazonaws.com/fasttext-vectors/word-analogies/questions-words-hi.txt), [Polish](https://s3-us-west-1.amazonaws.com/fasttext-vectors/word-analogies/questions-words-pl.txt).
This page gathers several pre-trained word vectors trained using fastText.
这一篇整合了一些之前用 fasttext 训练的词向量。
### Download pre-trained word vectors
### 下载经过训练的词向量
Pre-trained word vectors learned on different sources can be downloaded below:
你可以从下面下载单词向量,他们基于学习不同的数据来源,并且被预先训练过:
1.[wiki-news-300d-1M.vec.zip](https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki-news-300d-1M.vec.zip): 1 million word vectors trained on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens).
2.[wiki-news-300d-1M-subword.vec.zip](https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki-news-300d-1M-subword.vec.zip): 1 million word vectors trained with subword infomation on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens).
3.[crawl-300d-2M.vec.zip](https://s3-us-west-1.amazonaws.com/fasttext-vectors/crawl-300d-2M.vec.zip): 2 million word vectors trained on Common Crawl (600B tokens).
### Format
3.[crawl-300d-2M.vec.zip](https://s3-us-west-1.amazonaws.com/fasttext-vectors/crawl-300d-2M.vec.zip) : 两百万的词向量,这些词向量是在 Common Crawl 上训练得到的。(600B)
The first line of the file contains the number of words in the vocabulary and the size of the vectors.
### 格式
Each line contains a word followed by its vectors, like in the default fastText text format.
Each value is space separated. Words are ordered by descending frequency.
### License
文件的第一行包含了词汇表中单词的数量以及向量的大小。
每一行包含了一个单词和它的向量,就像是 fasttext 文本格式默认的那种样子。
每个值都是由空格隔开。
单词是按照频数降序排列的。
These word vectors are distributed under the [*Creative Commons Attribution-Share-Alike License 3.0*](https://creativecommons.org/licenses/by-sa/3.0/).
If you use these word vectors, please cite the following paper:
### 参考资料
如果你使用了这些词向量,请引用下面的文章:
T. Mikolov, E. Grave, P. Bojanowski, C. Puhrsch, A. Joulin. [*Advances in Pre-Training Distributed Word Representations*](https://arxiv.org/abs/1712.09405)
T. Mikolov, E. Grave, P. Bojanowski, C. Puhrsch, A. Joulin. [*Advances in Pre-Training Distributed Word Representations*](https://arxiv.org/abs/1712.09405)
FastText is a library for text classification and representation. It transforms text into continuous vectors that can later be used on any language related task. A few tutorials are available.
fastText uses a hashtable for either word or character ngrams. The size of the hashtable directly impacts the size of a model. To reduce the size of the model, it is possible to reduce the size of this table with the option '-hash'. For example a good value is 20000. Another option that greatly impacts the size of a model is the size of the vectors (-dim). This dimension can be reduced to save space but this can significantly impact performance. If that still produce a model that is too big, one can further reduce the size of a trained model with the quantization option.
## What would be the best way to represent word phrases rather than words?
## 表示单词短语而不是单词的最佳方法是什么?
Currently the best approach to represent word phrases or sentence is to take a bag of words of word vectors. Additionally, for phrases like “New York”, preprocessing the data so that it becomes a single token “New_York” can greatly help.
## Why does fastText produce vectors even for unknown words?
## 为什么 fastText 对未知词也产生向量?
One of the key features of fastText word representation is its ability to produce vectors for any words, even made-up ones.
FastText 词表示的一个关键特征就是它能对任何词产生词向量, 即使是自制词.
Indeed, fastText word vectors are built from vectors of substrings of characters contained in it.
事实上, fastText 词向量是由包含在其中的字符字串构成的.
This allows to build vectors even for misspelled words or concatenation of words.
这甚至允许为拼写错误的单词或拼接单词创建词向量.
## Why is the hierarchical softmax slightly worse in performance than the full softmax?
## 为什么分层 softmax 的效果比完全 softmax 效果要略差一些?
The hierachical softmax is an approximation of the full softmax loss that allows to train on large number of class efficiently. This is often at the cost of a few percent of accuracy.
Note also that this loss is thought for classes that are unbalanced, that is some classes are more frequent than others. If your dataset has a balanced number of examples per class, it is worth trying the negative sampling loss (-loss ns -neg 100).
## Can I use fastText with python? Or other languages?
## 我能用 python 语言使用 fastText 吗? 或者其他语言?
There are few unofficial wrappers for python or lua available on github.
Github 上几乎没有非官方的 python 或者 lua 包装器.
## Can I use fastText with continuous data?
## 我能用 fastText 处理连续数据吗?
FastText works on discrete tokens and thus cannot be directly used on continuous tokens. However, one can discretize continuous tokens to use fastText on them, for example by rounding values to a specific digit ("12.3" becomes "12").
## There are misspellings in the dictionary. Should we improve text normalization?
## 词典中一些错误拼写的词. 我们应该提升文本规范化吗?
If the words are infrequent, there is no need to worry.
如果这些词出现频率不高, 无须理会.
## I'm encountering a NaN, why could this be?
## 我遇到了 NaN, 为什么会这样呢?
You'll likely see this behavior because your learning rate is too high. Try reducing it until you don't see this error anymore.
你出现这个情况可能是因为学习率太高. 尝试减小学习率直到看不到这个错误.
## My compiler / architecture can't build fastText. What should I do?
## 我的编译器 / 体系结构无法构建 fastText. 我该怎么办?
Try a newer version of your compiler. We try to maintain compatibility with older versions of gcc and many platforms, however sometimes maintaining backwards compatibility becomes very hard. In general, compilers and tool chains that ship with LTS versions of major linux distributions should be fair game. In any case, create an issue with your compiler version and architecture and we'll try to implement compatibility.
We distribute two models for language identification, which can recognize 176 languages (see the list of ISO codes below). These models were trained on data from [Wikipedia](https://www.wikipedia.org/), [Tatoeba](https://tatoeba.org/eng/) and [SETimes](http://nlp.ffzg.hr/resources/corpora/setimes/), used under [CC-BY-SA](http://creativecommons.org/licenses/by-sa/3.0/).
*[lid.176.bin](https://s3-us-west-1.amazonaws.com/fasttext-vectors/supervised_models/lid.176.bin), which is faster and slightly more accurate, but has a file size of 126MB ;
*[lid.176.ftz](https://s3-us-west-1.amazonaws.com/fasttext-vectors/supervised_models/lid.176.ftz), which is the compressed version of the model, with a file size of 917kB.
af als am an ar arz as ast av az azb ba bar bcl be bg bh bn bo bpy br bs bxr ca cbk ce ceb ckb co cs cv cy da de diq dsb dty dv el eml en eo es et eu fa fi fr frr fy ga gd gl gn gom gu gv he hi hif hr hsb ht hu hy ia id ie ilo io is it ja jbo jv ka kk km kn ko krc ku kv kw ky la lb lez li lmo lo lrc lt lv mai mg mhr min mk ml mn mr mrj ms mt mwl my myv mzn nah nap nds ne new nl nn no oc or os pa pam pfl pl pms pnb ps pt qu rm ro ru rue sa sah sc scn sco sd sh si sk sl so sq sr su sv sw ta te tg th tk tl tr tt tyv ug uk ur uz vec vep vi vls vo wa war wuu xal xmf yi yo yue zh
af als am ar ar as as ast av az azb ba bar bcl be bg bh bn bo bpy br bs bxr ca cbk ce ceb ckb co cs cv c cy cy de deqq dsb dty dv el eml en eo es et eu faf fr fr fyy ga gd gl gn gom gu gv he hi hif hr hsb ht hu hyia id ie ieo io is it ja jbo jv ka kk km kn ko krc ku kv kw ky la lb lez li lmo lo lrc lt lv mai mg mhr min mk ml mn mr mrj ms mt mwl my mym mzn nah nap nds ne new nl nn no oc or os pa pam pfl pl pms pnb ps pt qu rm ro ru rue sa sah scn sco sd sh si sl sl so sq sr su sv sw ta te tg th t t t tr t t tyv ug uk ur uz vec vep vi vls vo wa war wuu xal xmf yi yo yue zh
```
```
### References
### 参考
If you use these models, please cite the following papers:
如果您使用这些模型,请引用以下论文:
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
These vectors in dimension 300 were obtained using the skip-gram model described in [*Bojanowski et al. (2016)*](https://arxiv.org/abs/1607.04606) with default parameters.
Please note that a newer version of multi-lingual word vectors are available at: [https://fasttext.cc/docs/en/crawl-vectors.html].
Please cite [1](#enriching-word-vectors-with-subword-information) if using this code for learning word representations or [2](#bag-of-tricks-for-efficient-text-classification) if using for text classification.
[1] P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
[1] P. Bojanowski\*, E. Grave\*, A. Joulin, T. Mikolov, [*Enriching Word Vectors with Subword Information*](https://arxiv.org/abs/1607.04606)
...
@@ -27,7 +24,7 @@ Please cite [1](#enriching-word-vectors-with-subword-information) if using this
...
@@ -27,7 +24,7 @@ Please cite [1](#enriching-word-vectors-with-subword-information) if using this
}
}
```
```
[3] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models*](https://arxiv.org/abs/1612.03651)
[3] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: 压缩文本分类模型*](https://arxiv.org/abs/1612.03651)
```markup
```markup
@article{joulin2016fasttext,
@article{joulin2016fasttext,
...
@@ -38,4 +35,4 @@ Please cite [1](#enriching-word-vectors-with-subword-information) if using this
...
@@ -38,4 +35,4 @@ Please cite [1](#enriching-word-vectors-with-subword-information) if using this
This page gathers several pre-trained supervised models on several datasets.
这个页面收集了几个预先训练好的监督模型,其训练数据来自于几个不同的数据集。
### Description
### Description(描述)
The regular models are trained using the procedure described in [1]. They can be reproduced using the classification-results.sh script within our github repository. The quantized models are build by using the respective supervised settings and adding the following flags to the quantize subcommand.
If you use these models, please cite the following paper:
如果您使用这些模型, 请引用以下文章:
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
[1] A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, [*Bag of Tricks for Efficient Text Classification*](https://arxiv.org/abs/1607.01759)
...
@@ -42,7 +39,7 @@ If you use these models, please cite the following paper:
...
@@ -42,7 +39,7 @@ If you use these models, please cite the following paper:
}
}
```
```
[2] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: Compressing text classification models*](https://arxiv.org/abs/1612.03651)
[2] A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, [*FastText.zip: 压缩文本分类模型*](https://arxiv.org/abs/1612.03651)
Text classification is a core problem to many applications, like spam detection, sentiment analysis or smart replies. In this tutorial, we describe how to build a text classifier with the fastText tool.
The goal of text classification is to assign documents (such as emails, posts, text messages, product reviews, etc...) to one or multiple categories. Such categories can be review scores, spam v.s. non-spam, or the language in which the document was typed. Nowadays, the dominant approach to build such classifiers is machine learning, that is learning classification rules from examples. In order to build such classifiers, we need labeled data, which consists of documents and their corresponding categories (or tags, or labels).
As an example, we build a classifier which automatically classifies stackexchange questions about cooking into one of several possible tags, such as `pot`, `bowl` or `baking`.
quantize quantize a model to reduce the memory usage
quantize 量化模型以减少内存使用量
test evaluate a supervised classifier
test 评估一个监督分类器
predict predict most likely labels
predict 预测最有可能的标签
predict-prob predict most likely labels with probabilities
predict-prob 用概率预测最可能的标签
skipgram train a skipgram model
skipgram 训练一个 skipgram 模型
cbow train a cbow model
cbow 训练一个 cbow 模型
print-word-vectors print word vectors given a trained model
print-word-vectors 给定一个训练好的模型,打印出所有的单词向量
print-sentence-vectors print sentence vectors given a trained model
print-sentence-vectors 给定一个训练好的模型,打印出所有的句子向量
nn query for nearest neighbors
nn 查询最近邻居
analogies query for analogies
analogies 查找所有同类词
```
```
In this tutorial, we mainly use the `supervised`, `test` and `predict` subcommands, which corresponds to learning (and using) text classifier. For an introduction to the other functionalities of fastText, please see the [tutorial about learning word vectors](https://fasttext.cc/docs/en/unsupervised-tutorial.html).
As mentioned in the introduction, we need labeled data to train our supervised classifier. In this tutorial, we are interested in building a classifier to automatically recognize the topic of a stackexchange question about cooking. Let's download examples of questions from [the cooking section of Stackexchange](http://cooking.stackexchange.com/), and their associated tags:
Each line of the text file contains a list of labels, followed by the corresponding document. All the labels start by the `__label__` prefix, which is how fastText recognize what is a label or what is a word. The model is then trained to predict the labels given the word in the document.
Before training our first classifier, we need to split the data into train and validation. We will use the validation set to evaluate how good the learned classifier is on new data.
The `-input` command line option indicates the file containing the training examples, while the `-output` option indicates where to save the model. At the end of training, a file `model_cooking.bin`, containing the trained classifier, is created in the current directory.
It is possible to directly test our classifier interactively, by running the command:
可以通过命令行直接交互式地测试分类器:
```bash
```bash
>> ./fasttext predict model_cooking.bin -
>> ./fasttext predict model_cooking.bin -
```
```
and then typing a sentence. Let's first try the sentence:
然后输入一个句子。我们来试一下:
*Which baking dish is best to bake a banana bread ?*
*Which baking dish is best to bake a banana bread ?*
The predicted tag is `baking` which fits well to this question. Let us now try a second example:
其预测的标签是 `baking`,非常贴切。 现在让我们尝试第二个例子:
*Why not put knives in the dishwasher?*
*Why not put knives in the dishwasher?*
The label predicted by the model is `food-safety`, which is not relevant. Somehow, the model seems to fail on simple examples. To get a better sense of its quality, let's test it on the validation data by running:
>> ./fasttext test model_cooking.bin cooking.valid
>> ./fasttext test model_cooking.bin cooking.valid
...
@@ -116,7 +113,7 @@ R@1 0.0541
...
@@ -116,7 +113,7 @@ R@1 0.0541
Number of examples: 3000
Number of examples: 3000
```
```
The output of fastText are the precision at one (`P@1`) and the recall at one (`R@1`). We can also compute the precision at five and recall at five with:
>> ./fasttext test model_cooking.bin cooking.valid 5
>> ./fasttext test model_cooking.bin cooking.valid 5
...
@@ -126,31 +123,31 @@ R@5 0.146
...
@@ -126,31 +123,31 @@ R@5 0.146
Number of examples: 3000
Number of examples: 3000
```
```
## Advanced readers: precision and recall
## 高级读者:精确度和召回率
The precision is the number of correct labels among the labels predicted by fastText. The recall is the number of labels that successfully were predicted, among all the real labels. Let's take an example to make this more clear:
On Stack Exchange, this sentence is labeled with three tags: `equipment`, `cleaning` and `knives`. The top five labels predicted by the model can be obtained with:
are`food-safety`, `baking`, `equipment`, `substitutions` and `bread`.
前五名是`food-safety`, `baking`, `equipment`, `substitutions` and `bread`.
Thus, one out of five labels predicted by the model is correct, giving a precision of 0.20. Out of the three real labels, only one is predicted by the model, giving a recall of 0.33.
The model obtained by running fastText with the default arguments is pretty bad at classifying new questions. Let's try to improve the performance, by changing the default parameters.
Looking at the data, we observe that some words contain uppercase letter or punctuation. One of the first step to improve the performance of our model is to apply some simple pre-processing. A crude normalization can be obtained using command line tools such as `sed` and `tr`:
We observe that thanks to the pre-processing, the vocabulary is smaller (from 14k words to 9k). The precision is also starting to go up by 4%!
我们观察到,由于预处理,词汇量变得更小了(从 14k 到 9k)。精确度也开始提高了4%!
### more epochs and larger learning rate
### 更多的迭代和更快的学习速率
By default, fastText sees each training example only five times during training, which is pretty small, given that our training set only have 12k training examples. The number of times each examples is seen (also known as the number of epochs), can be increased using the `-epoch` option:
>> ./fasttext test model_cooking.bin cooking.valid
>> ./fasttext test model_cooking.bin cooking.valid
...
@@ -198,7 +195,7 @@ R@1 0.218
...
@@ -198,7 +195,7 @@ R@1 0.218
Number of examples: 3000
Number of examples: 3000
```
```
This is much better! Another way to change the learning speed of our model is to increase (or decrease) the learning rate of the algorithm. This corresponds to how much the model changes after processing each example. A learning rate of 0 would means that the model does not change at all, and thus, does not learn anything. Good values of the learning rate are in the range `0.1 - 1.0`.
Let us now add a few more features to improve even further our performance!
现在让我们多添加一些功能来进一步提高我们的性能!
### word n-grams
### word n-grams
Finally, we can improve the performance of a model by using word bigrams, instead of just unigrams. This is especially important for classification problems where word order is important, such as sentiment analysis.
最后,我们可以通过使用 word bigrams 而不是 unigrams 来提高模型的性能。 这对于词序重要的分类问题尤其重要,例如情感分析。
With a few steps, we were able to go from a precision at one of 12.4% to 59.9%. Important steps included:
只需几个步骤,我们就可以从 12.4% 到达 59.9% 的精度。 重要步骤包括:
*preprocessing the data ;
*预处理数据 ;
*changing the number of epochs (using the option `-epoch`, standard range`[5 - 50]`) ;
*改变迭代次数 (使用选项 `-epoch`, 标准范围`[5 - 50]`) ;
*changing the learning rate (using the option `-lr`, standard range`[0.1 - 1.0]`) ;
*改变学习速率 (使用选项 `-lr`, 标准范围`[0.1 - 1.0]`) ;
*using word n-grams (using the option `-wordNgrams`, standard range`[1 - 5]`).
*使用 word n-grams (使用选项 `-wordNgrams`, 标准范围`[1 - 5]`).
## Advanced readers: What is a Bigram?
## 高级读者: 什么是 Bigram?
A 'unigram' refers to a single undividing unit, or token, usually used as an input to a model. For example a unigram can a word or a letter depending on the model. In fastText, we work at the word level and thus unigrams are words.
Similarly we denote by 'bigram' the concatenation of 2 consecutive tokens or words. Similarly we often talk about n-gram to refer to the concatenation any n consecutive tokens.
类似地,我们用 'bigram' 表示2个连续标记或单词的连接。 类似地,我们经常谈论 n-gram 来引用任意 n 个连续标记或单词的级联。
For example, in the sentence, 'Last donut of the night', the unigrams are 'last', 'donut', 'of', 'the' and 'night'. The bigrams are: 'Last donut', 'donut of', 'of the' and 'the night'.
例如,在 'Last donut of the night' 这个句子中,unigrams是 'last','donut','of','the' 和 'night'。 bigrams 是 'Last donut', 'donut of', 'of the' 和 'the night'。
Bigrams are particularly interesting because, for most sentences, you can reconstruct the order of the words just by looking at a bag of n-grams.
Let us illustrate this by a simple exercise, given the following bigrams, try to reconstruct the original sentence: 'all out', 'I am', 'of bubblegum', 'out of' and 'am all'.
Since we are training our model on a few thousands of examples, the training only takes a few seconds. But training models on larger datasets, with more labels can start to be too slow. A potential solution to make the training faster is to use the hierarchical softmax, instead of the regular softmax [Add a quick explanation of the hierarchical softmax]. This can be done with the option `-loss hs`:
In this tutorial, we gave a brief overview of how to use fastText to train powerful text classifiers. We had a light overview of some of the most important options to tune.
A popular idea in modern machine learning is to represent words by vectors. These vectors capture hidden information about a language, like word analogies or semantic. It is also used to improve performance of text classifiers.
In this tutorial, we show how to build these word vectors with the fastText tool. To download and install fastText, follow the first steps of [the tutorial on text classification](https://fasttext.cc/docs/en/supervised-tutorial.html).
In order to compute word vectors, you need a large text corpus. Depending on the corpus, the word vectors will capture different information. In this tutorial, we focus on Wikipedia's articles but other sources could be considered, like news or Webcrawl (more examples [here](http://statmt.org/)). To download a raw dump of Wikipedia, run the following command:
Downloading the Wikipedia corpus takes some time. Instead, lets restrict our study to the first 1 billion bytes of English Wikipedia. They can be found on Matt Mahoney's [website](http://mattmahoney.net/):
下载维基百科语料库需要一些时间。有一种替代方案就是我们只研究英语维基百科的前 10 亿字节(大概 1G 不到)。可以在 Matt Mahoney 的[网站](http://mattmahoney.net/)上找到:
```bash
```bash
$ mkdir data
$ mkdir data
...
@@ -22,33 +20,33 @@ $ wget -c http://mattmahoney.net/dc/enwik9.zip -P data
...
@@ -22,33 +20,33 @@ $ wget -c http://mattmahoney.net/dc/enwik9.zip -P data
$ unzip data/enwik9.zip -d data
$ unzip data/enwik9.zip -d data
```
```
A raw Wikipedia dump contains a lot of HTML / XML data. We pre-process it with the wikifil.pl script bundled with fastText (this script was originally developed by Matt Mahoney, and can be found on his [website](http://mattmahoney.net/) )
原始维基百科转储包含大量的 HTML/XML 数据。我们使用与 fastText 一起打包的 `wikifil.pl` 脚本对其进行预处理(该脚本最初由 Matt Mahoney 开发,可以在他的[网站](http://mattmahoney.net/)上找到)
```bash
```bash
$ perl wikifil.pl data/enwik9 > data/fil9
$ perl wikifil.pl data/enwik9 > data/fil9
```
```
We can check the file by running the following command:
我们可以通过运行下面的命令来检查文件:
```bash
```bash
$ head-c 80 data/fil9
$ head-c 80 data/fil9
anarchism originated as a term of abuse first used against early working class
anarchism originated as a term of abuse first used against early working class
```
```
The text is nicely pre-processed and can be used to learn our word vectors.
这个文本经过了很好地预处理,可以用来学习我们的词向量。
## Training word vectors
## 训练词向量
Learning word vectors on this data can now be achieved with a single command:
To decompose this command line: ./fastext calls the binary fastText executable (see how to install fastText here) with the 'skipgram' model (it can also be 'cbow'). We then specify the requires options '-input' for the location of the data and '-output' for the location where the word representations will be saved.
While fastText is running, the progress and estimated time to completion is shown on your screen. Once the program finishes, there should be two files in the result directory:
-rw-r-r-- 1 bojanowski 1876110778 190004182 Dec 20 11:01 fil9.vec
-rw-r-r-- 1 bojanowski 1876110778 190004182 Dec 20 11:01 fil9.vec
```
```
The `fil9.bin` file is a binary file that stores the whole fastText model and can be subsequently loaded. The `fil9.vec` file is a text file that contains the word vectors, one per line for each word in the vocabulary:
The first line is a header containing the number of words and the dimensionality of the vectors. The subsequent lines are the word vectors for all words in the vocabulary, sorted by decreasing frequency.
第一行说明了单词数量和向量维数。随后的行是词汇表中所有单词的词向量,按降序排列。
## Advanced readers: skipgram versus cbow
## 高级读者:skipgram 与 cbow 两种模型
fastText provides two models for computing word representations: skipgram and cbow ('**c**ontinuous-**b**ag-**o**f-**w**ords').
The skipgram model learns to predict a target word thanks to a nearby word. On the other hand, the cbow model predicts the target word according to its context. The context is represented as a bag of the words contained in a fixed size window around the target word.
Let us illustrate this difference with an example: given the sentence *'Poets have been mysteriously silent on the subject of cheese'* and the target word '*silent*', a skipgram model tries to predict the target using a random close-by word, like '*subject' *or* '*mysteriously*'**. *The cbow model takes all the words in a surrounding window, like {*been, *mysteriously*, on, the*}, and uses the sum of their vectors to predict the target. The figure below summarizes this difference with another example.
让我们用一个例子来说明这种差异:给出句子 *'Poets have been mysteriously silent on the subject of cheese'* 和目标单词 '*silent*',skipgram 模型随机取近邻词尝试预测目标词,如 '*subject*'或'*mysteriously*'。cbow 模型使用目标单词固定数量的左边和右边单词,,如 {*been*, *mysteriously*, *on*, *the*},并使用它们的向量和来预测目标单词。下图用另一个例子总结了这种差异。
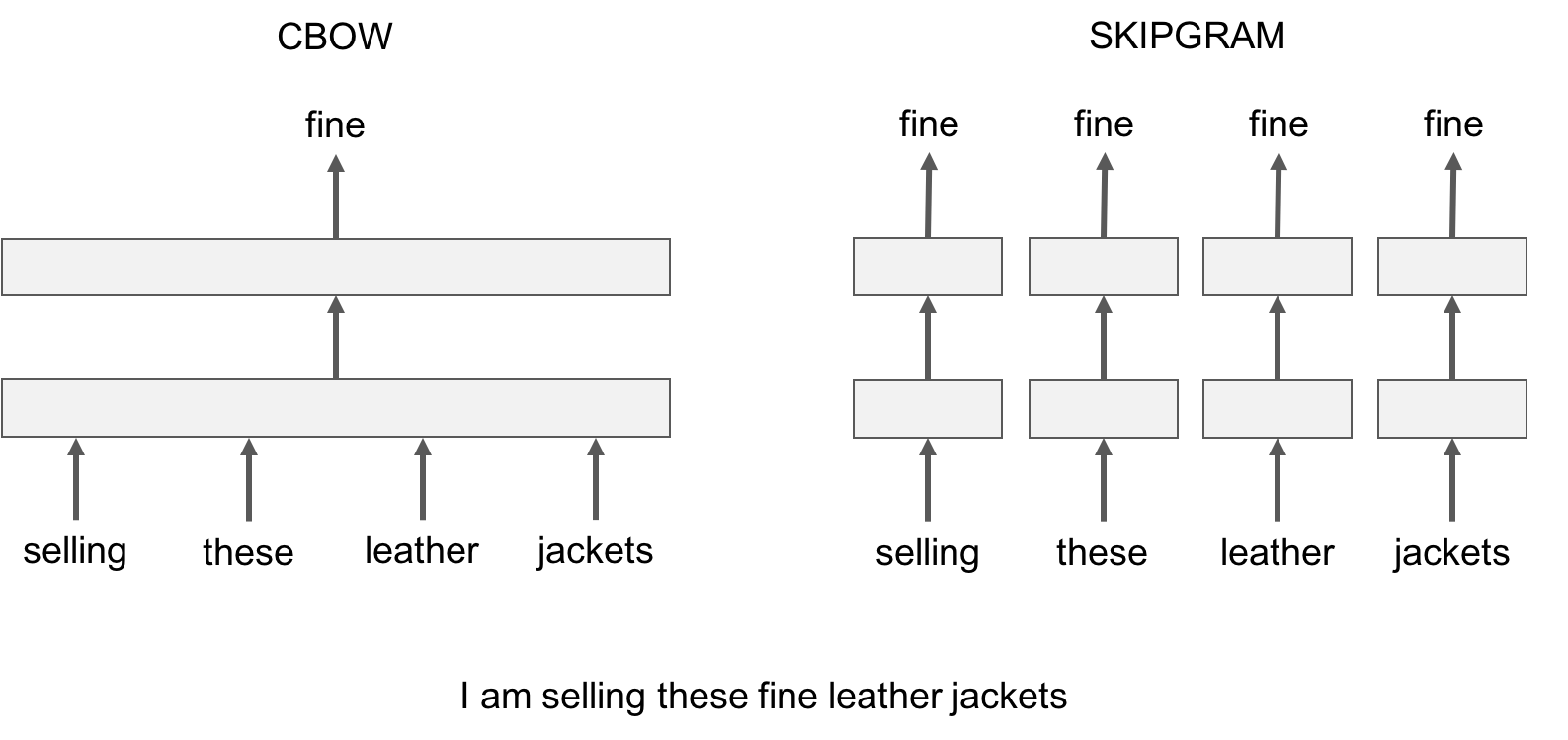

To train a cbow model with fastText, you run the following command:
通过这个练习,我们观察到 skipgram 模型会比 cbow 模型在 subword information 上效果更好
在实践中,我们观察到 skipgram 模型比 cbow 在子词信息方面效果更好。
In practice, we observe that skipgram models works better with subword information than cbow.
## 高级读者:调整参数
## Advanced readers: playing with the parameters
So far, we run fastText with the default parameters, but depending on the data, these parameters may not be optimal. Let us give an introduction to some of the key parameters for word vectors.
The most important parameters of the model are its dimension and the range of size for the subwords. The dimension (*dim*) controls the size of the vectors, the larger they are the more information they can capture but requires more data to be learned. But, if they are too large, they are harder and slower to train. By default, we use 100 dimensions, but any value in the 100-300 range is as popular. The subwords are all the substrings contained in a word between the minimum size (*minn*) and the maximal size (*maxn*). By default, we take all the subword between 3 and 6 characters, but other range could be more appropriate to different languages:
Depending on the quantity of data you have, you may want to change the parameters of the training. The *epoch* parameter controls how many time will loop over your data. By default, we loop over the dataset 5 times. If you dataset is extremely massive, you may want to loop over it less often. Another important parameter is the learning rate -*lr*). The higher the learning rate is, the faster the model converge to a solution but at the risk of overfitting to the dataset. The default value is 0.05 which is a good compromise. If you want to play with it we suggest to stay in the range of [0.01, 1]:
Finally , fastText is multi-threaded and uses 12 threads by default. If you have less CPU cores (say 4), you can easily set the number of threads using the *thread* flag:
Searching and printing word vectors directly from the `fil9.vec` file is cumbersome. Fortunately, there is a `print-word-vectors` functionality in fastText.
For examples, we can print the word vectors of words *asparagus,**pidgey* and *yellow* with the following command:
A nice feature is that you can also query for words that did not appear in your data! Indeed words are represented by the sum of its substrings. As long as the unknown word is made of known substrings, there is a representation of it!
You still get a word vector for it! But how good it is? Let s find out in the next sections!
你仍然得到一个单词向量! 但它有多棒? 让我们在下一节中揭晓!
## 最近邻查询
## Nearest neighbor queries
查看最近邻是检查词向量效果的一种简单方法。 这给出了向量能够获取的语义信息类型的直觉。
A simple way to check the quality of a word vector is to look at its nearest neighbors. This give an intuition of the type of semantic information the vectors are able to capture.
这可以通过 *nn* 功能来实现。 例如,我们可以通过运行以下命令来查询单词的最近邻:
This can be achieve with the *nn *functionality. For example, we can query the 10 nearest neighbors of a word by running the following command:
```bash
```bash
$ ./fasttext nn result/fil9.bin
$ ./fasttext nn result/fil9.bin
Pre-computing word vectors... done.
Pre-computing word vectors... done.
```
```
然后我们会提示输入我们的查询词,让我们试试 *asparagus*:
Then we are prompted to type our query word, let us try *asparagus* :
```bash
```bash
Query word? asparagus
Query word? asparagus
...
@@ -162,7 +157,7 @@ celery 0.774529
...
@@ -162,7 +157,7 @@ celery 0.774529
beets 0.773984
beets 0.773984
```
```
Nice! It seems that vegetable vectors are similar. Note that the nearest neighbor is the word *asparagus* itself, this means that this word appeared in the dataset. What about pokemons?
Different evolution of the same Pokemon have close-by vectors! But what about our misspelled word, is its vector close to anything reasonable? Let s find out:
Thanks to the information contained within the word, the vector of our misspelled word matches to reasonable words! It is not perfect but the main information has been captured.
In order to find nearest neighbors, we need to compute a similarity score between words. Our words are represented by continuous word vectors and we can thus apply simple similarities to them. In particular we use the cosine of the angles between two vectors. This similarity is computed for all words in the vocabulary, and the 10 most similar words are shown. Of course, if the word appears in the vocabulary, it will appear on top, with a similarity of 1.
In a similar spirit, one can play around with word analogies. For example, we can see if our model can guess what is to France, what Berlin is to Germany.
The answer provides by our model is *Paris*, which is correct. Let's have a look at a less obvious example:
我们的模型提供了正确的答案 *Paris*。 让我们来看一个不太明显的例子:
```bash
```bash
Query triplet (A - B + C)? psx sony nintendo
Query triplet (A - B + C)? psx sony nintendo
...
@@ -238,12 +233,11 @@ dreamcast 0.74907
...
@@ -238,12 +233,11 @@ dreamcast 0.74907
famicom 0.745298
famicom 0.745298
```
```
Our model considers that the *nintendo* analogy of a *psx* is the *gamecube*, which seems reasonable. Of course the quality of the analogies depend on the dataset used to train the model and one can only hope to cover fields only in the dataset.
Using subword-level information is particularly interesting to build vectors for unknown words. For example, the word *gearshift* does not exist on Wikipedia but we can still query its closest existing words:
Most of the retrieved words share substantial substrings but a few are actually quite different, like *cogwheel*. You can try other words like *sunbathe* or *grandnieces*.
Now that we have seen the interest of subword information for unknown words, let s check how it compares to a model that do not use subword information. To train a model without no subwords, just run the following command:
To illustrate the difference, let us take an uncommon word in Wikipedia, like *accomodation* which is a misspelling of *accommodation**.* Here is the nearest neighbors obtained without no subwords:
The result does not make much sense, most of these words are unrelated. On the other hand, using subword information gives the following list of nearest neighbors:
结果没有多大意义,大部分这些词都是无关的。 另一方面,使用子字信息给出以下最近邻列表:
```bash
```bash
Query word? accomodation
Query word? accomodation
...
@@ -302,8 +296,8 @@ accomodate 0.703177
...
@@ -302,8 +296,8 @@ accomodate 0.703177
hospitality 0.701426
hospitality 0.701426
```
```
The nearest neighbors capture different variation around the word *accommodation*. We also get semantically related words such as *amenities* or *lodging*.
In this tutorial, we show how to obtain word vectors from Wikipedia. This can be done for any language and you we provide [pre-trained models](https://fasttext.cc/docs/en/pretrained-vectors.html) with the default setting for 294 of them.