diff --git a/README.md b/README.md
index f5849c664f793b5224906add6feddc3d0b64c8a0..7a3a193579f1af1a1c821ee8938cb4da5ac69500 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,9 @@
-# sharding-jdbc
+# sharding-jdbc 使用教程和模型结构
+
+作者:小傅哥
+
博客:[https://bugstack.cn](https://bugstack.cn)
+
+> 沉淀、分享、成长,让自己和他人都能有所收获!😄
本文的宗旨在于通过简单干净实践的方式教会读者,快速 Easy 的使用上 sharding-jdbc 这个笨重的大家伙!
@@ -14,7 +19,7 @@
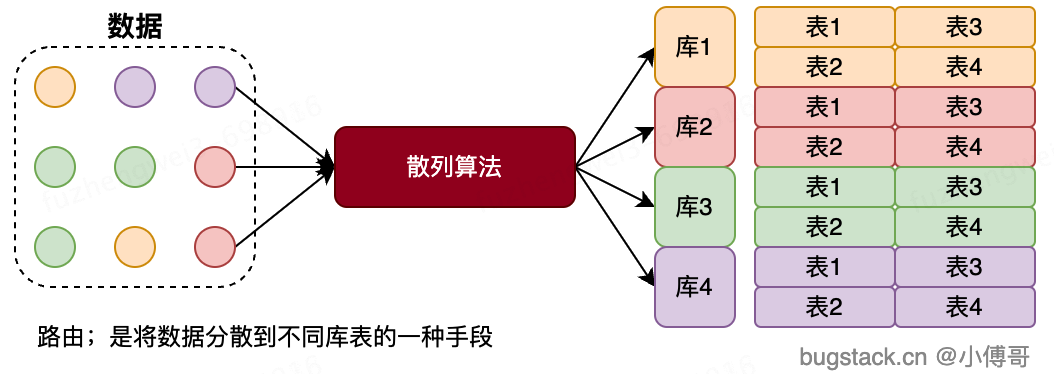
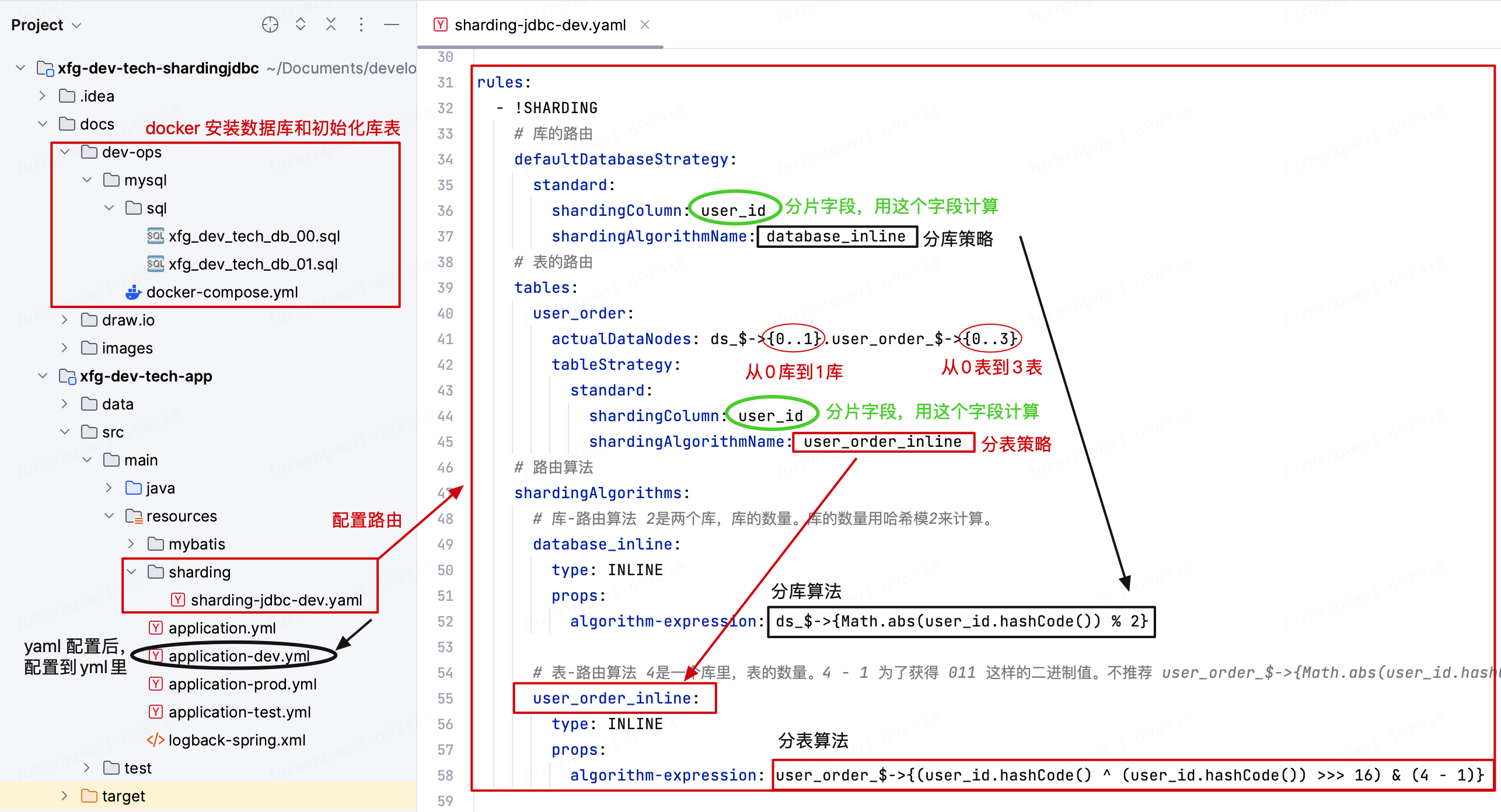
分库分表的本质是数据的散列,分摊数据库资源压力。如把原本在一台机器上的数据库存放1000万数据,分摊到n台机上,拆分这1000万的数据和后续的增量。让每个数据库资源来分摊原本需要一台数据库所提供的服务。
-

+
-

+
-

+