diff --git "a/\346\212\200\346\234\257/linuxshell.md" "b/\346\212\200\346\234\257/linuxshell.md"
index 6bc634d660d3257c55d53b22547d96852142478b..9a489e88badc8e42e8b9988f193bad19002072d1 100644
--- "a/\346\212\200\346\234\257/linuxshell.md"
+++ "b/\346\212\200\346\234\257/linuxshell.md"
@@ -1,16 +1,21 @@
# 关于 Linux shell 你必须知道的技巧
+
+
+
 +
+
 -
-

-
+
+
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
**-----------**
@@ -53,7 +58,7 @@ $ rm $(where connect.sh)
**标准输入就是编程语言中诸如`scanf`或者`readline`这种命令;而参数是指程序的`main`函数传入的`args`字符数组**。
-前文「Linux文件描述符」说过,管道符和重定向符是将数据作为程序的标准输入,而`$(cmd)`是读取`cmd`命令输出的数据作为参数。
+前文 [Linux文件描述符](https://labuladong.github.io/article/fname.html?fname=linux进程) 说过,管道符和重定向符是将数据作为程序的标准输入,而`$(cmd)`是读取`cmd`命令输出的数据作为参数。
用刚才的例子说,`rm`命令源代码中肯定不接受标准输入,而是接收命令行参数,删除相应的文件。作为对比,`cat`命令是既接受标准输入,又接受命令行参数:
@@ -104,7 +109,7 @@ $ logout
$ nohup some_cmd &
```
-`nohup`命令也是类似的原理,不过通过我的测试,还是`(cmd &)`这种形式更加稳定。
+`nohub`命令也是类似的原理,不过通过我的测试,还是`(cmd &)`这种形式更加稳定。
### 三、单引号和双引号的区别
@@ -112,7 +117,7 @@ $ nohup some_cmd &
shell 的行为可以测试,使用`set -x`命令,会开启 shell 的命令回显,你可以通过回显观察 shell 到底在执行什么命令:
-
+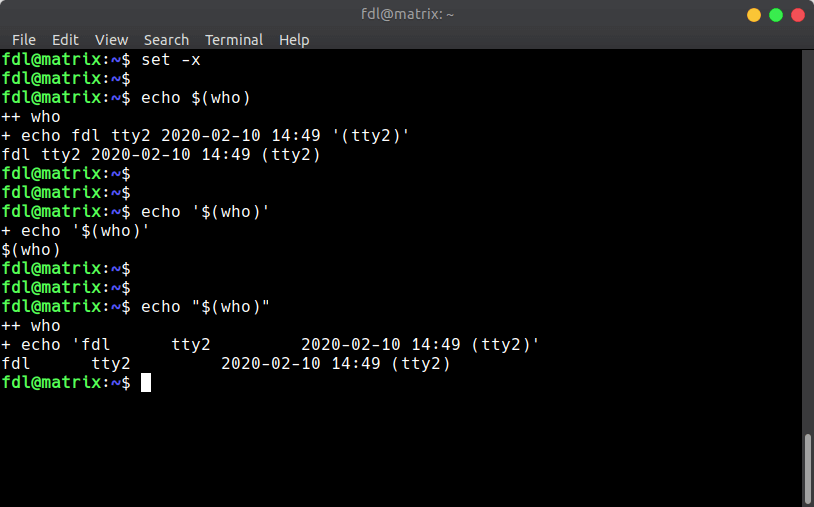
可见 `echo $(cmd)` 和 `echo "$(cmd)"`,结果差不多,但是仍然有区别。注意观察,双引号转义完成的结果会自动增加单引号,而前者不会。
@@ -147,12 +152,9 @@ $ sudo /home/fdl/bin/connect.sh
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
- -
-
======其他语言代码======
diff --git "a/\346\212\200\346\234\257/\345\257\206\347\240\201\346\212\200\346\234\257.md" "b/\346\212\200\346\234\257/\345\257\206\347\240\201\346\212\200\346\234\257.md"
index e64148d2086d7b2deb9ac0d6b0da5527b9f001c6..3c14ee24fbcd43daf6446777d7e172546eae0b20 100644
--- "a/\346\212\200\346\234\257/\345\257\206\347\240\201\346\212\200\346\234\257.md"
+++ "b/\346\212\200\346\234\257/\345\257\206\347\240\201\346\212\200\346\234\257.md"
@@ -200,5 +200,4 @@ HTTPS 协议中的 SSL/TLS 安全层会组合使用以上几种加密方式,**
-======其他语言代码======
-[test ad](https://labuladong.gitee.io/algo/)
\ No newline at end of file
+======其他语言代码======
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\344\272\214\345\217\211\345\240\206\350\257\246\350\247\243\345\256\236\347\216\260\344\274\230\345\205\210\347\272\247\351\230\237\345\210\227.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\344\272\214\345\217\211\345\240\206\350\257\246\350\247\243\345\256\236\347\216\260\344\274\230\345\205\210\347\272\247\351\230\237\345\210\227.md"
index 7a247ef83b86c67d3a958efeeeefd74dbf8bc2b5..366852c71e4d48485970740f381d1616a0e7d323 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\344\272\214\345\217\211\345\240\206\350\257\246\350\247\243\345\256\236\347\216\260\344\274\230\345\205\210\347\272\247\351\230\237\345\210\227.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\344\272\214\345\217\211\345\240\206\350\257\246\350\247\243\345\256\236\347\216\260\344\274\230\345\205\210\347\272\247\351\230\237\345\210\227.md"
@@ -1,28 +1,33 @@
# 二叉堆详解实现优先级队列
+
+
+
+
-
-
+
+
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
**-----------**
二叉堆(Binary Heap)没什么神秘,性质比二叉搜索树 BST 还简单。其主要操作就两个,`sink`(下沉)和 `swim`(上浮),用以维护二叉堆的性质。其主要应用有两个,首先是一种排序方法「堆排序」,第二是一种很有用的数据结构「优先级队列」。
-本文就以实现优先级队列(Priority Queue)为例,通过图片和人类的语言来描述一下二叉堆怎么运作的。
+本文参考《算法 4》的代码,以实现优先级队列(Priority Queue)为例,来讲讲一下二叉堆怎么运作的。
### 一、二叉堆概览
-首先,二叉堆和二叉树有啥关系呢,为什么人们总数把二叉堆画成一棵二叉树?
+首先,二叉堆和二叉树有啥关系呢,为什么人们总是把二叉堆画成一棵二叉树?
-因为,二叉堆其实就是一种特殊的二叉树(完全二叉树),只不过存储在数组里。一般的链表二叉树,我们操作节点的指针,而在数组里,我们把数组索引作为指针:
+因为,二叉堆在逻辑上其实是一种特殊的二叉树(完全二叉树),只不过存储在数组里。一般的链表二叉树,我们操作节点的指针,而在数组里,我们把数组索引作为指针:
```java
// 父节点的索引
@@ -39,29 +44,29 @@ int right(int root) {
}
```
-画个图你立即就能理解了,注意数组的第一个索引 0 空着不用,
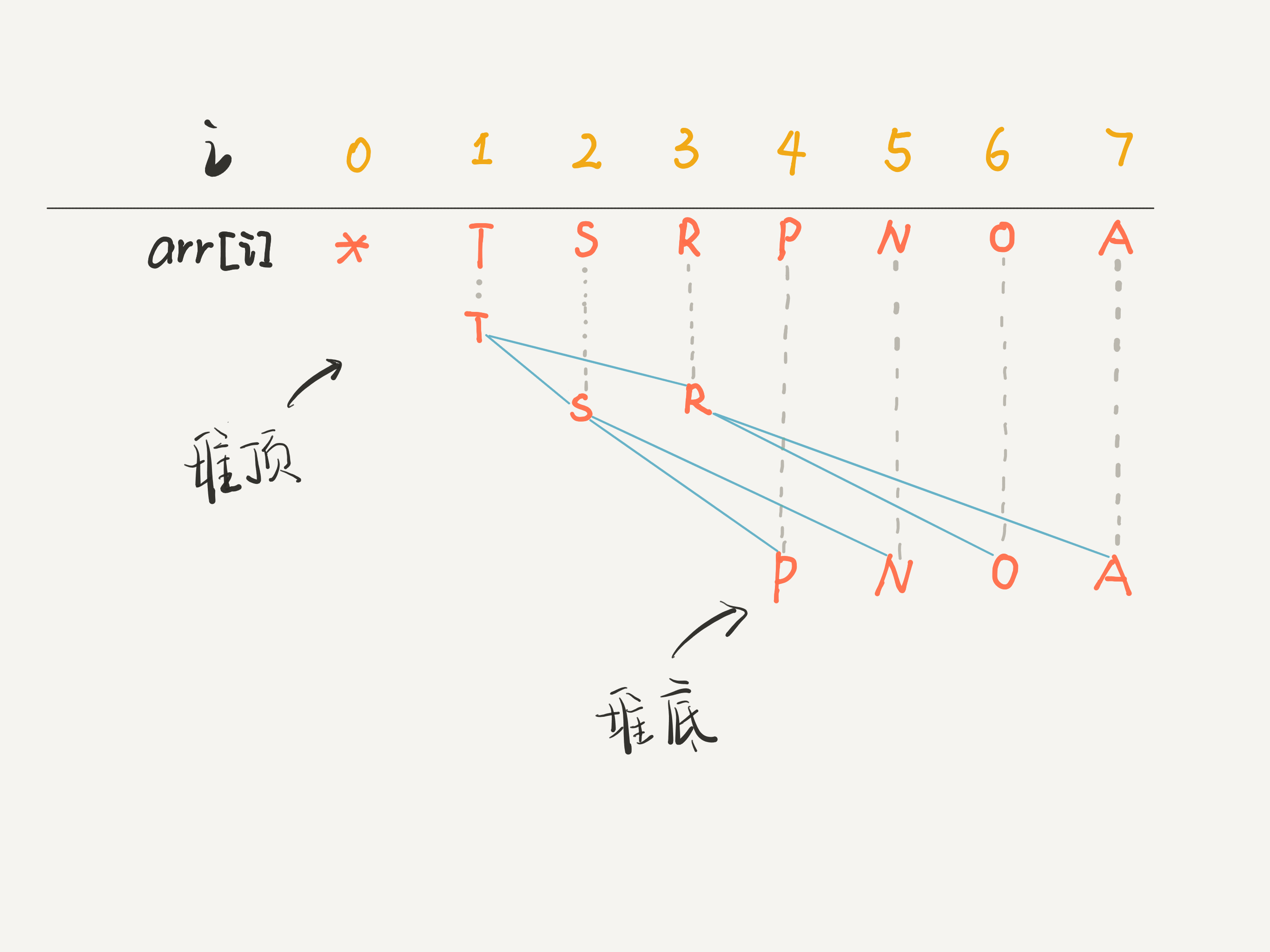
+画个图你立即就能理解了,比如 `arr` 是一个字符数组,注意数组的第一个索引 0 空着不用:
-
+
-PS:因为数组索引是数组,为了方便区分,将字符作为数组元素。
+你看到了,因为这棵二叉树是「完全二叉树」,所以把 `arr[1]` 作为整棵树的根的话,每个节点的父节点和左右孩子的索引都可以通过简单的运算得到,这就是二叉堆设计的一个巧妙之处。
-你看到了,把 arr[1] 作为整棵树的根的话,每个节点的父节点和左右孩子的索引都可以通过简单的运算得到,这就是二叉堆设计的一个巧妙之处。为了方便讲解,下面都会画的图都是二叉树结构,相信你能把树和数组对应起来。
+为了方便讲解,下面都会画的图都是二叉树结构,相信你能把树和数组对应起来。
-二叉堆还分为最大堆和最小堆。**最大堆的性质是:每个节点都大于等于它的两个子节点。**类似的,最小堆的性质是:每个节点都小于等于它的子节点。
+二叉堆还分为最大堆和最小堆。**最大堆的性质是:每个节点都大于等于它的两个子节点**。类似的,最小堆的性质是:每个节点都小于等于它的子节点。
两种堆核心思路都是一样的,本文以最大堆为例讲解。
-对于一个最大堆,根据其性质,显然堆顶,也就是 arr[1] 一定是所有元素中最大的元素。
+对于一个最大堆,根据其性质,显然堆顶,也就是 `arr[1]` 一定是所有元素中最大的元素。
### 二、优先级队列概览
优先级队列这种数据结构有一个很有用的功能,你插入或者删除元素的时候,元素会自动排序,这底层的原理就是二叉堆的操作。
-数据结构的功能无非增删查该,优先级队列有两个主要 API,分别是 `insert` 插入一个元素和 `delMax` 删除最大元素(如果底层用最小堆,那么就是 `delMin`)。
+数据结构的功能无非增删查改,优先级队列有两个主要 API,分别是 `insert` 插入一个元素和 `delMax` 删除最大元素(如果底层用最小堆,那么就是 `delMin`)。
下面我们实现一个简化的优先级队列,先看下代码框架:
-PS:为了清晰起见,这里用到 Java 的泛型,`Key` 可以是任何一种可比较大小的数据类型,你可以认为它是 int、char 等。
+> PS:这里用到 Java 的泛型,`Key` 可以是任何一种可比较大小的数据类型,比如 Integer 等类型。
```java
public class MaxPQ
@@ -69,7 +74,7 @@ public class MaxPQ
// 存储元素的数组
private Key[] pq;
// 当前 Priority Queue 中的元素个数
- private int N = 0;
+ private int size = 0;
public MaxPQ(int cap) {
// 索引 0 不用,所以多分配一个空间
@@ -87,14 +92,14 @@ public class MaxPQ
/* 删除并返回当前队列中最大元素 */
public Key delMax() {...}
- /* 上浮第 k 个元素,以维护最大堆性质 */
- private void swim(int k) {...}
+ /* 上浮第 x 个元素,以维护最大堆性质 */
+ private void swim(int x) {...}
- /* 下沉第 k 个元素,以维护最大堆性质 */
- private void sink(int k) {...}
+ /* 下沉第 x 个元素,以维护最大堆性质 */
+ private void sink(int x) {...}
/* 交换数组的两个元素 */
- private void exch(int i, int j) {
+ private void swap(int i, int j) {
Key temp = pq[i];
pq[i] = pq[j];
pq[j] = temp;
@@ -113,15 +118,15 @@ public class MaxPQ
### 三、实现 swim 和 sink
-为什么要有上浮 swim 和下沉 sink 的操作呢?为了维护堆结构。
+为什么要有上浮 `swim` 和下沉 `sink` 的操作呢?为了维护堆结构。
我们要讲的是最大堆,每个节点都比它的两个子节点大,但是在插入元素和删除元素时,难免破坏堆的性质,这就需要通过这两个操作来恢复堆的性质了。
-对于最大堆,会破坏堆性质的有有两种情况:
+对于最大堆,会破坏堆性质的有两种情况:
-1. 如果某个节点 A 比它的子节点(中的一个)小,那么 A 就不配做父节点,应该下去,下面那个更大的节点上来做父节点,这就是对 A 进行**下沉**。
+1、如果某个节点 A 比它的子节点(中的一个)小,那么 A 就不配做父节点,应该下去,下面那个更大的节点上来做父节点,这就是对 A 进行**下沉**。
-2. 如果某个节点 A 比它的父节点大,那么 A 不应该做子节点,应该把父节点换下来,自己去做父节点,这就是对 A 的**上浮**。
+2、如果某个节点 A 比它的父节点大,那么 A 不应该做子节点,应该把父节点换下来,自己去做父节点,这就是对 A 的**上浮**。
当然,错位的节点 A 可能要上浮(或下沉)很多次,才能到达正确的位置,恢复堆的性质。所以代码中肯定有一个 `while` 循环。
@@ -132,89 +137,87 @@ public class MaxPQ
**上浮的代码实现:**
```java
-private void swim(int k) {
+private void swim(int x) {
// 如果浮到堆顶,就不能再上浮了
- while (k > 1 && less(parent(k), k)) {
- // 如果第 k 个元素比上层大
- // 将 k 换上去
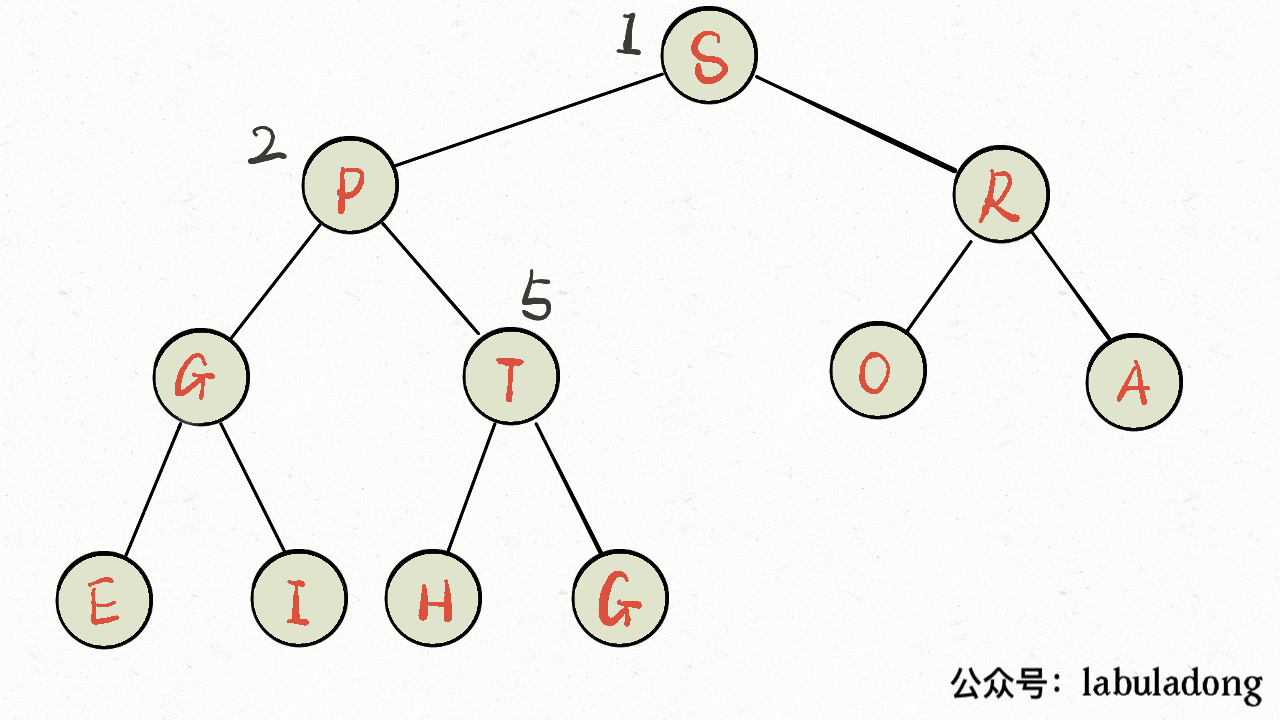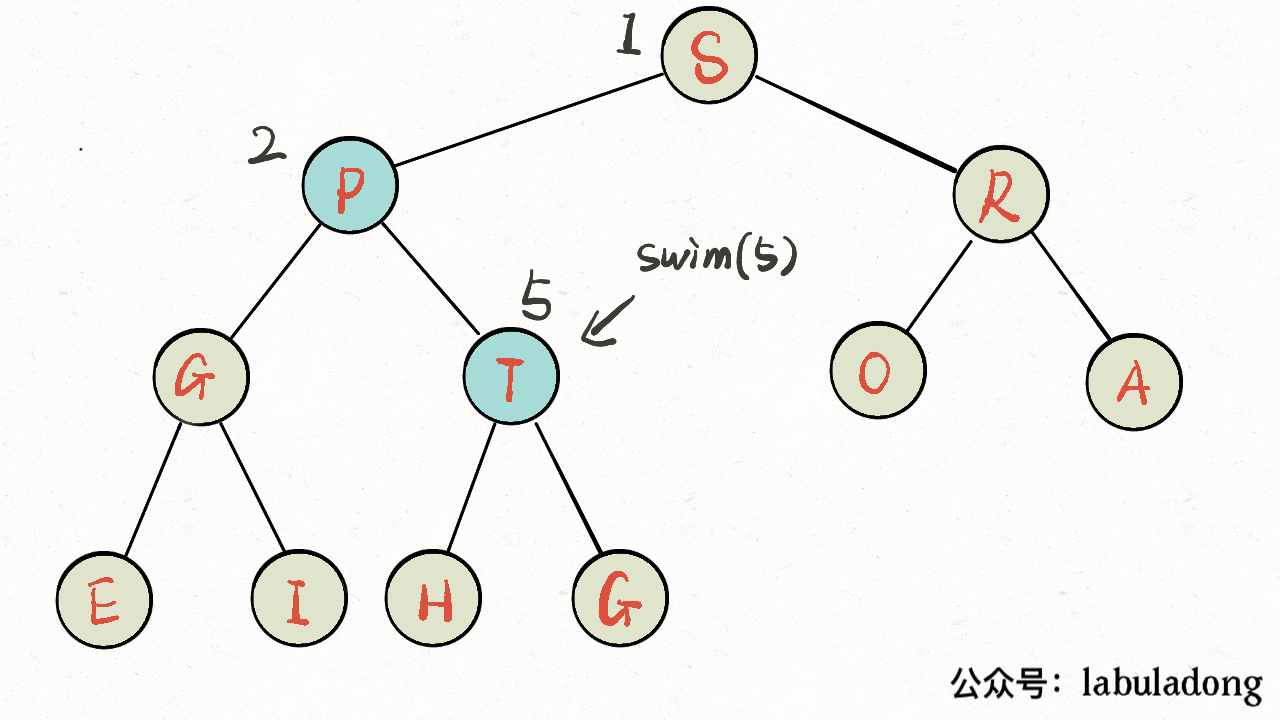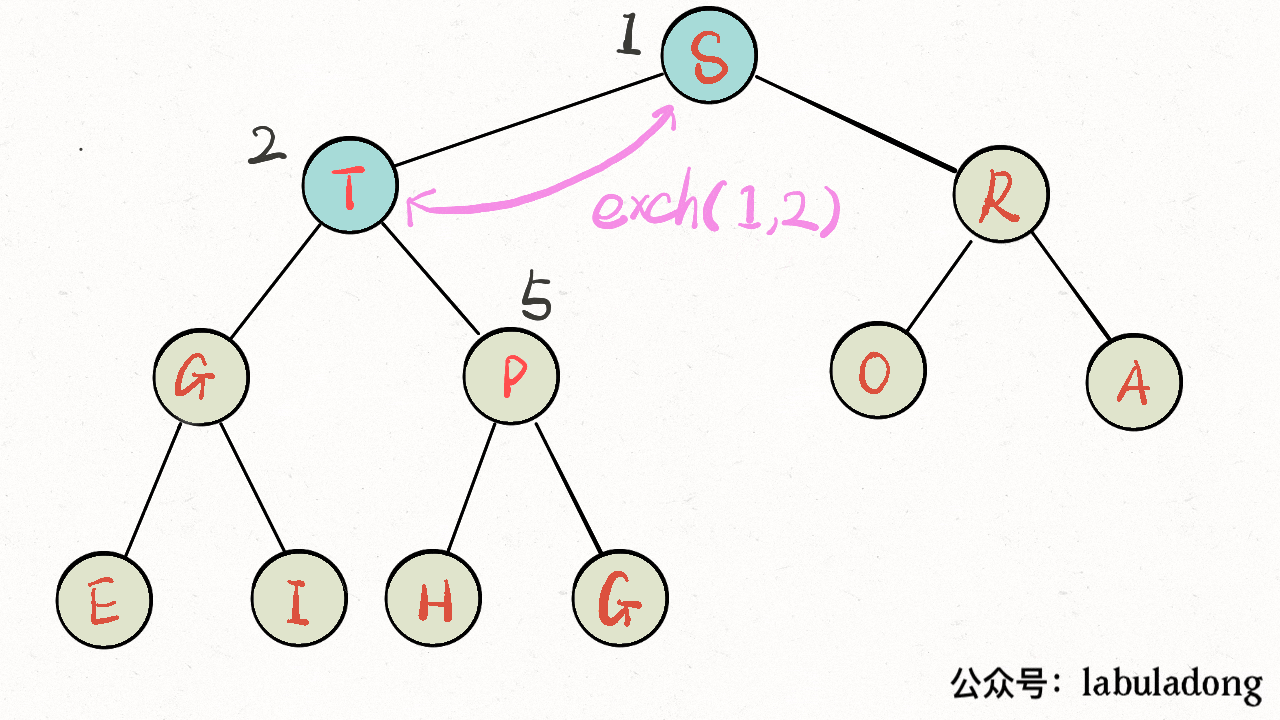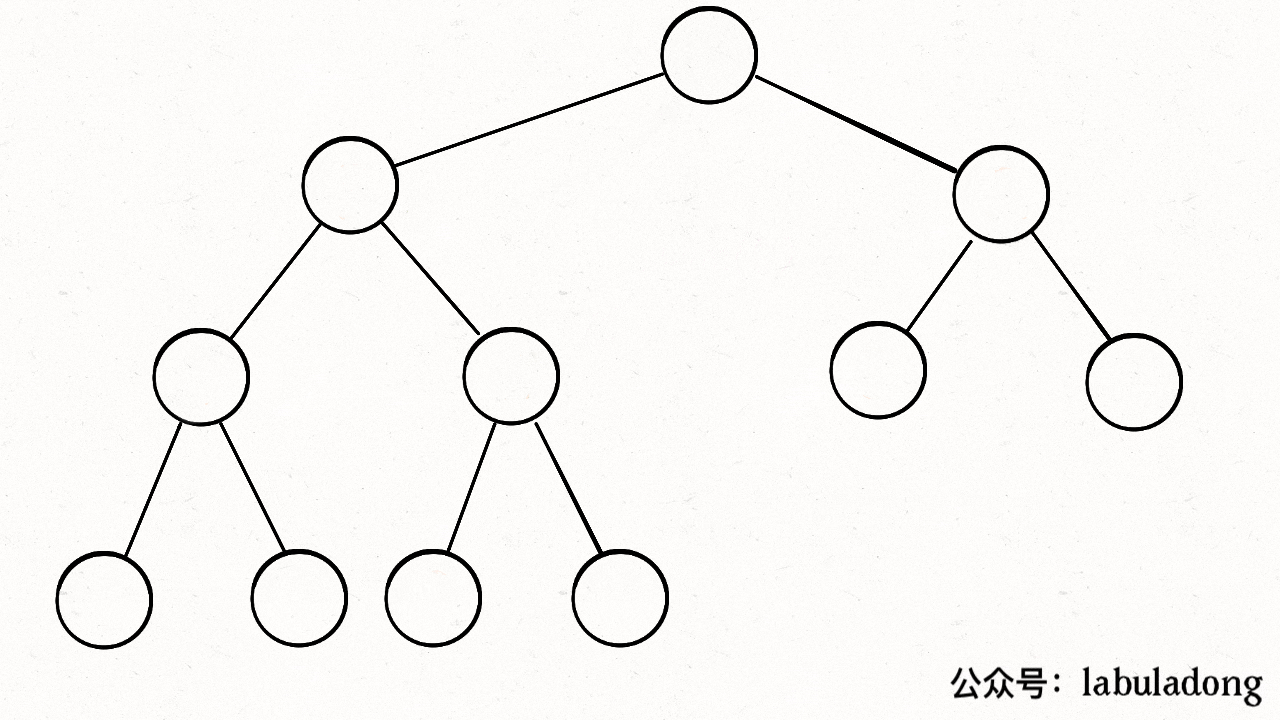
- exch(parent(k), k);
- k = parent(k);
+ while (x > 1 && less(parent(x), x)) {
+ // 如果第 x 个元素比上层大
+ // 将 x 换上去
+ swap(parent(x), x);
+ x = parent(x);
}
}
```
画个 GIF 看一眼就明白了:
-
+
**下沉的代码实现:**
下沉比上浮略微复杂一点,因为上浮某个节点 A,只需要 A 和其父节点比较大小即可;但是下沉某个节点 A,需要 A 和其**两个子节点**比较大小,如果 A 不是最大的就需要调整位置,要把较大的那个子节点和 A 交换。
```java
-private void sink(int k) {
+private void sink(int x) {
// 如果沉到堆底,就沉不下去了
- while (left(k) <= N) {
+ while (left(x) <= size) {
// 先假设左边节点较大
- int older = left(k);
+ int max = left(x);
// 如果右边节点存在,比一下大小
- if (right(k) <= N && less(older, right(k)))
- older = right(k);
- // 结点 k 比俩孩子都大,就不必下沉了
- if (less(older, k)) break;
- // 否则,不符合最大堆的结构,下沉 k 结点
- exch(k, older);
- k = older;
+ if (right(x) <= size && less(max, right(x)))
+ max = right(x);
+ // 结点 x 比俩孩子都大,就不必下沉了
+ if (less(max, x)) break;
+ // 否则,不符合最大堆的结构,下沉 x 结点
+ swap(x, max);
+ x = max;
}
}
```
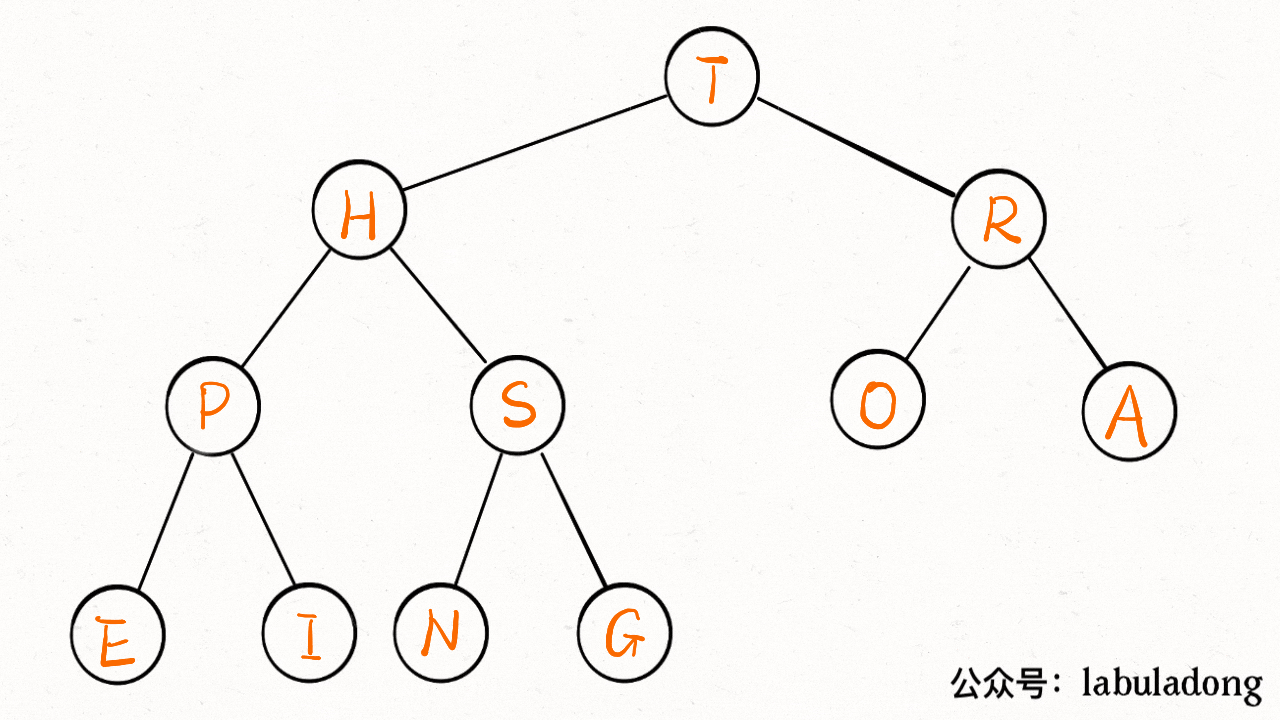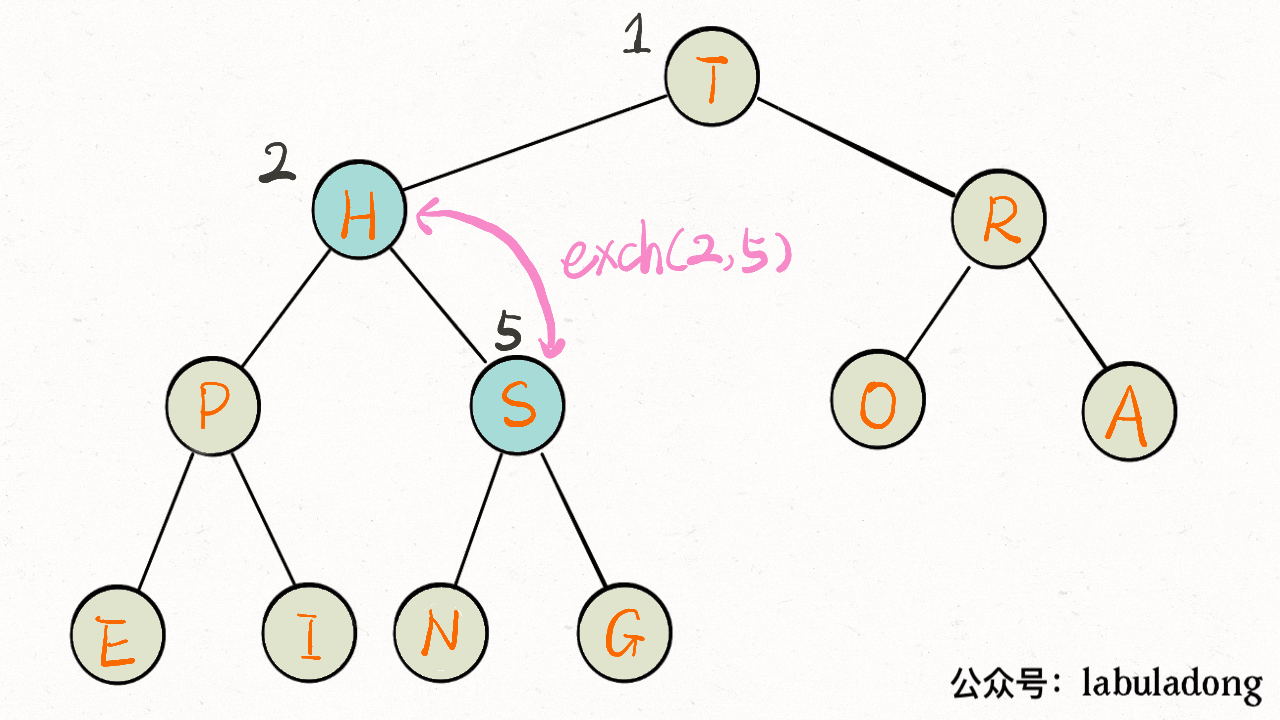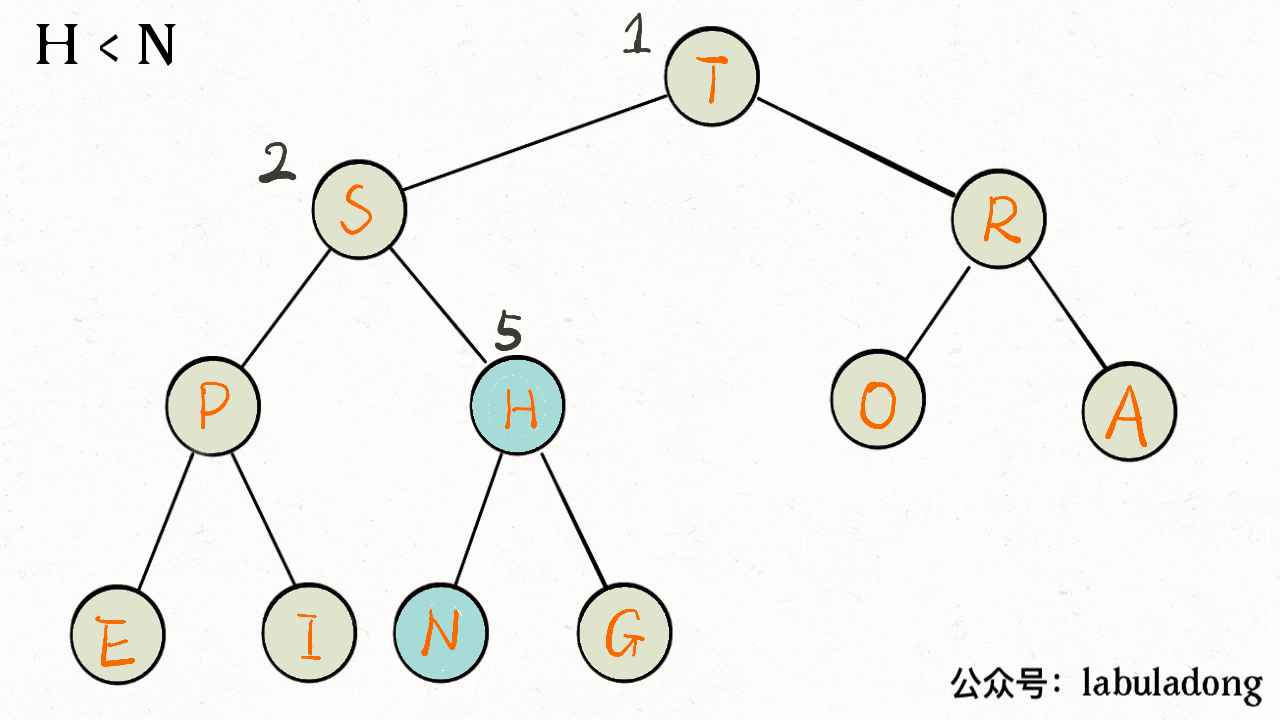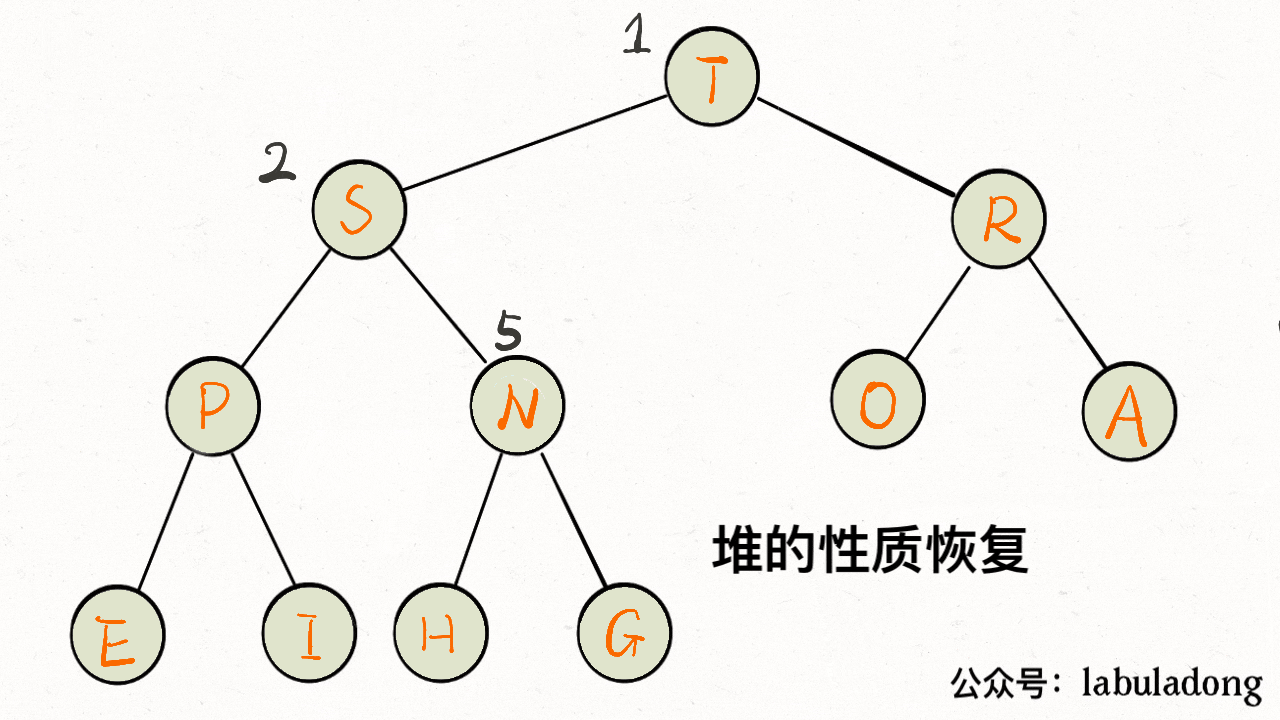
画个 GIF 看下就明白了:
-
+
至此,二叉堆的主要操作就讲完了,一点都不难吧,代码加起来也就十行。明白了 `sink` 和 `swim` 的行为,下面就可以实现优先级队列了。
-
### 四、实现 delMax 和 insert
这两个方法就是建立在 `swim` 和 `sink` 上的。
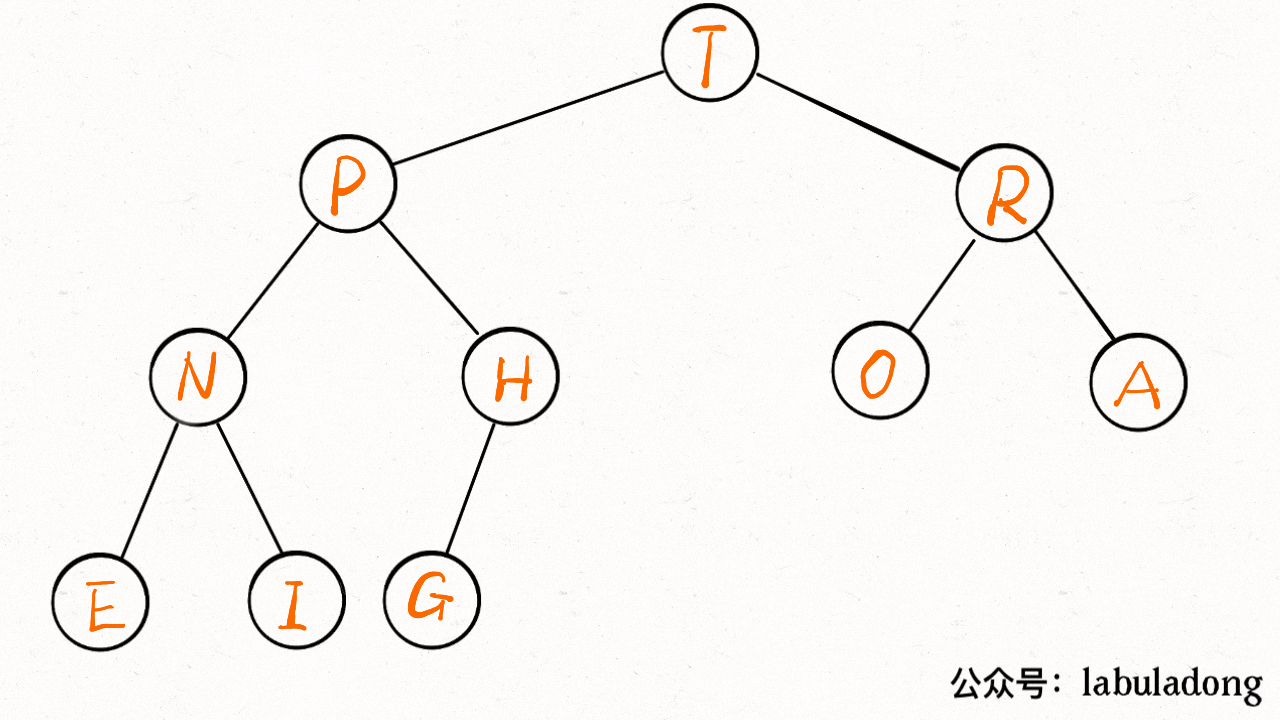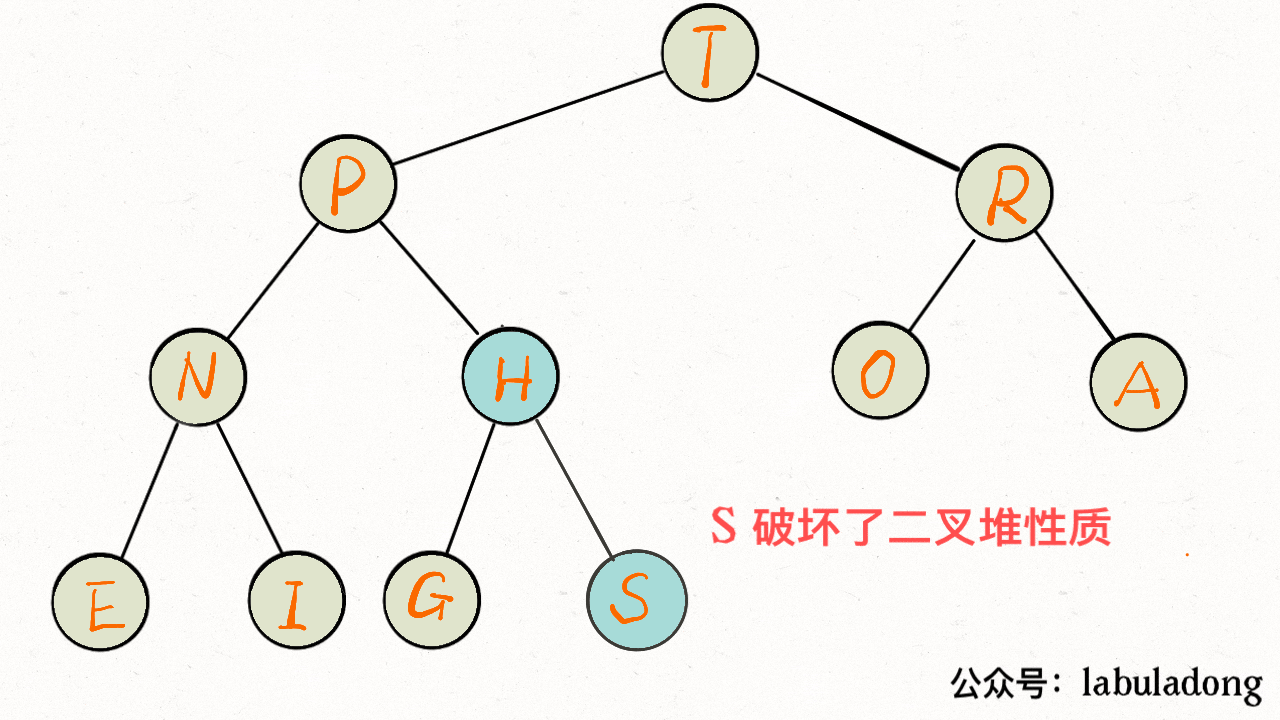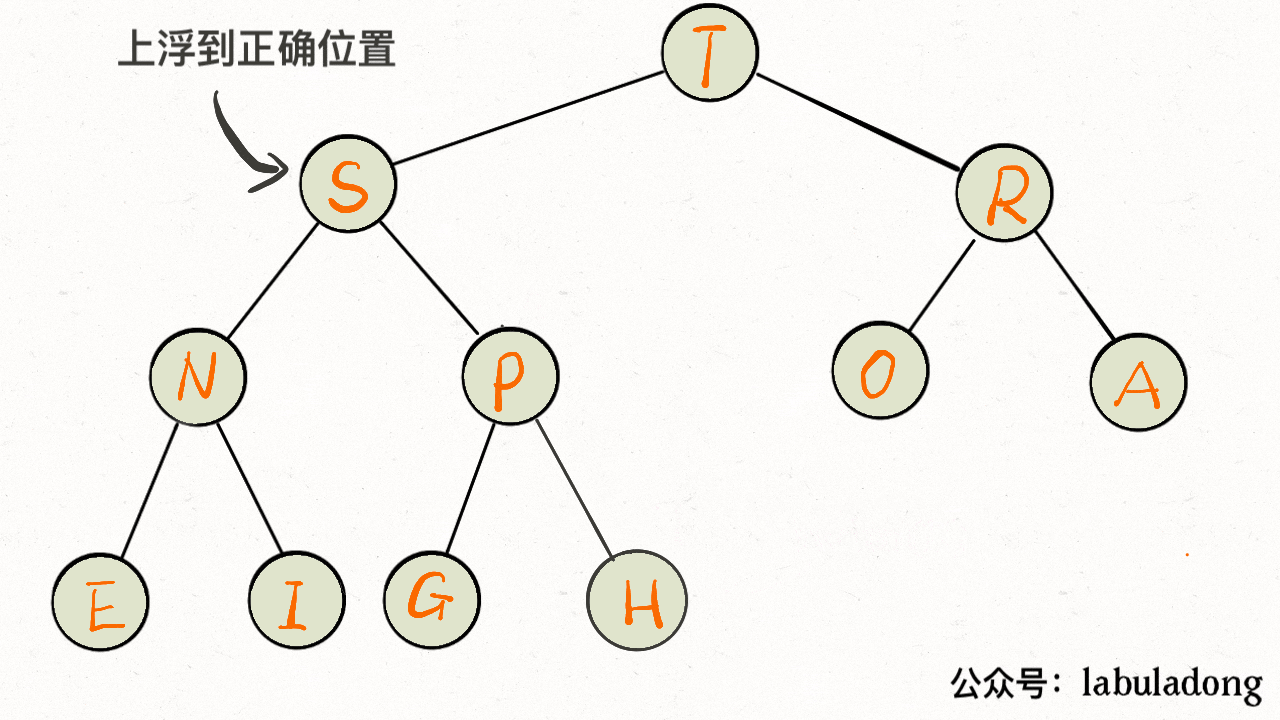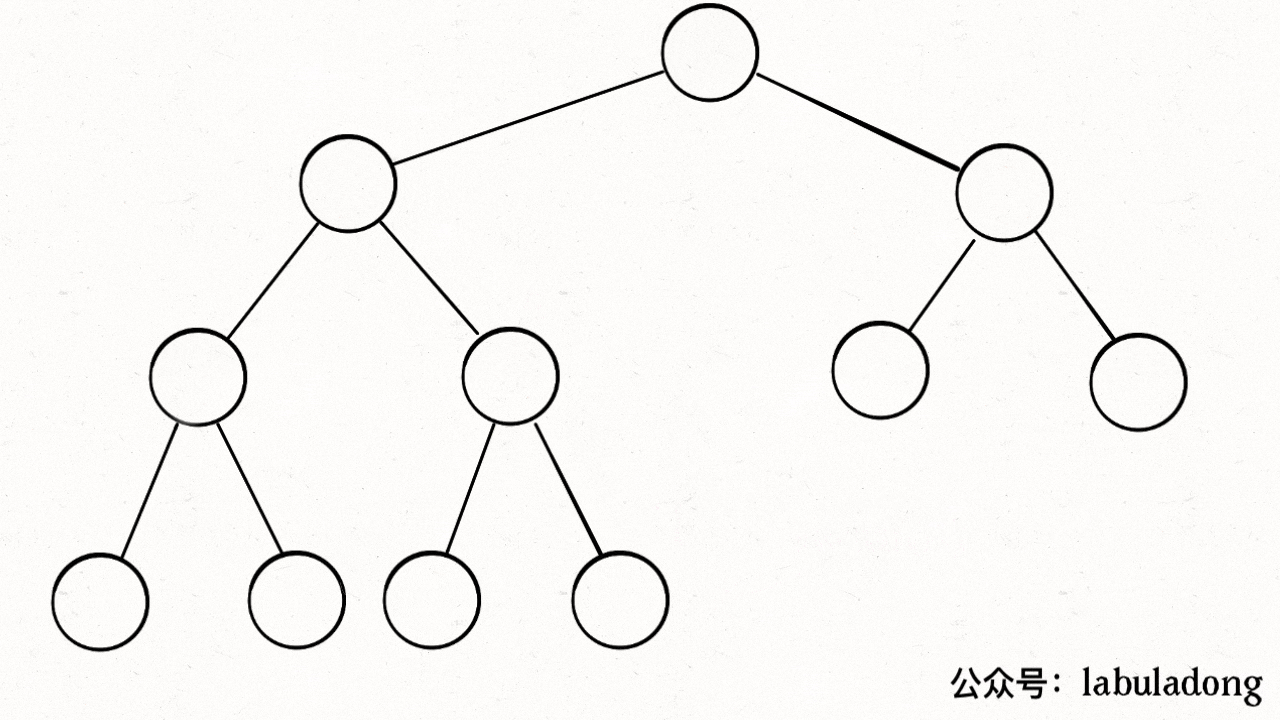
-**`insert` 方法先把要插入的元素添加到堆底的最后,然后让其上浮到正确位置。**
+**`insert` 方法先把要插入的元素添加到堆底的最后,然后让其上浮到正确位置**。
-
+
```java
public void insert(Key e) {
- N++;
+ size++;
// 先把新元素加到最后
- pq[N] = e;
+ pq[size] = e;
// 然后让它上浮到正确的位置
- swim(N);
+ swim(size);
}
```
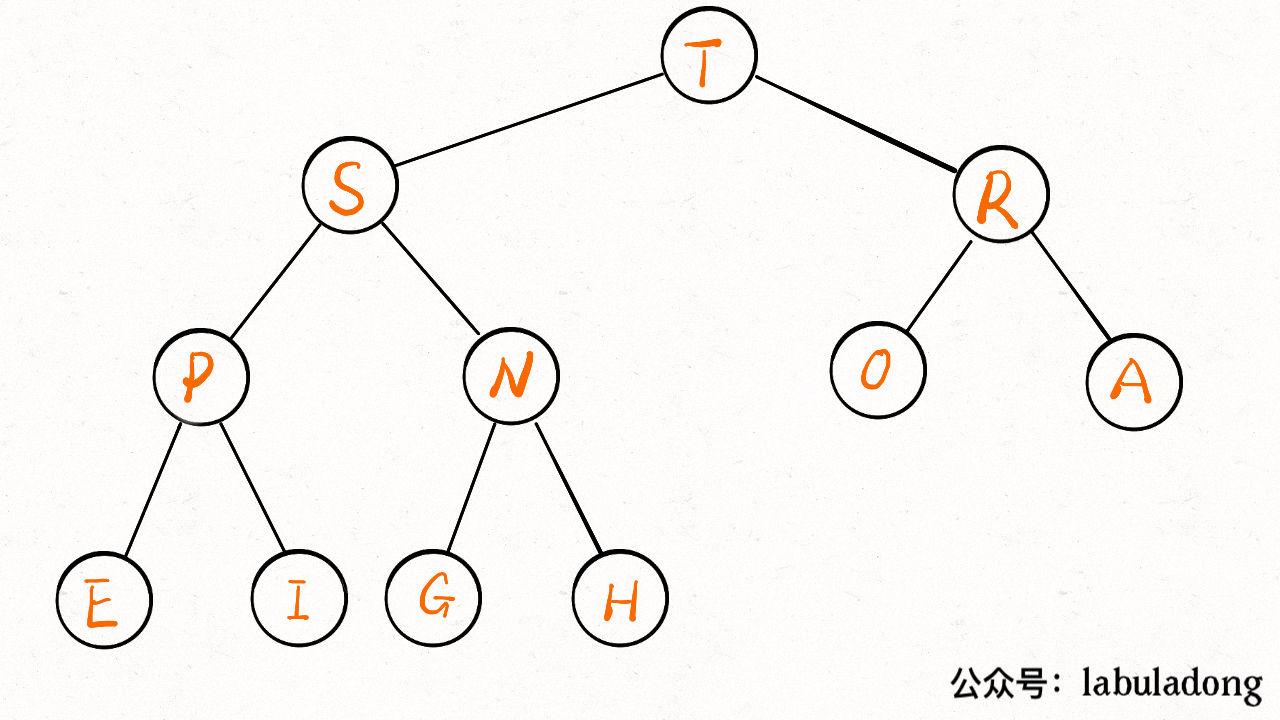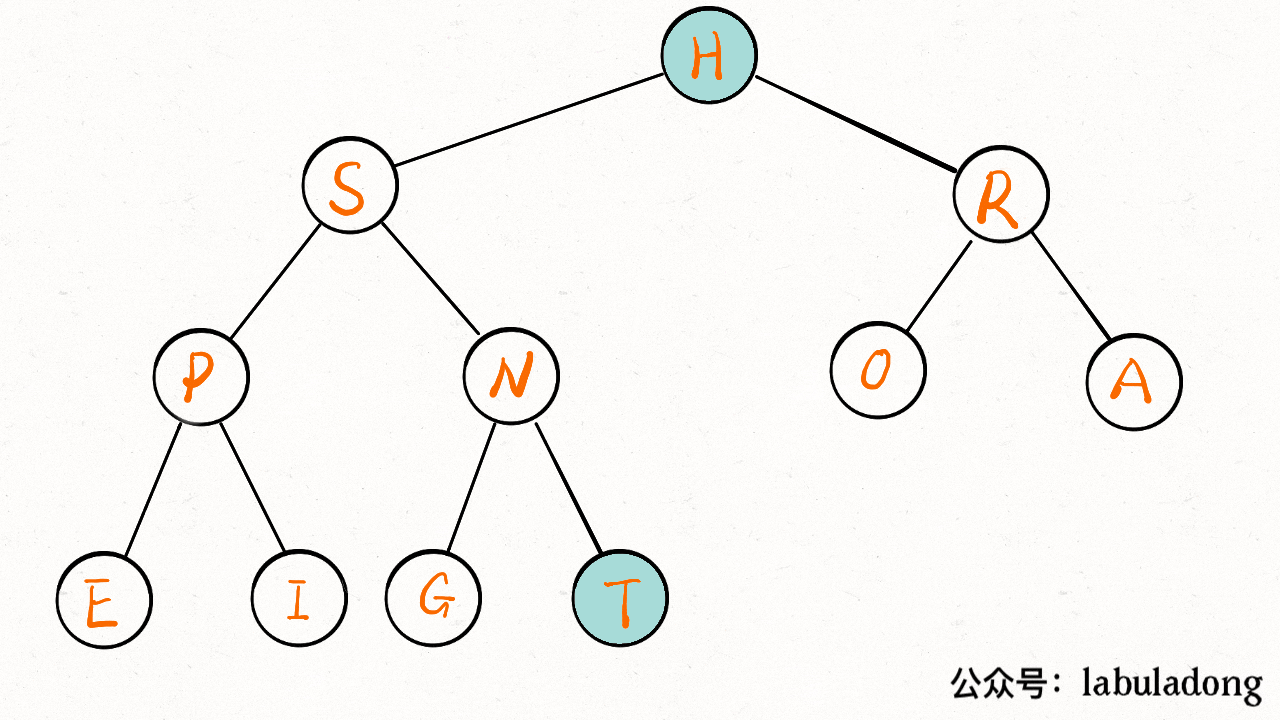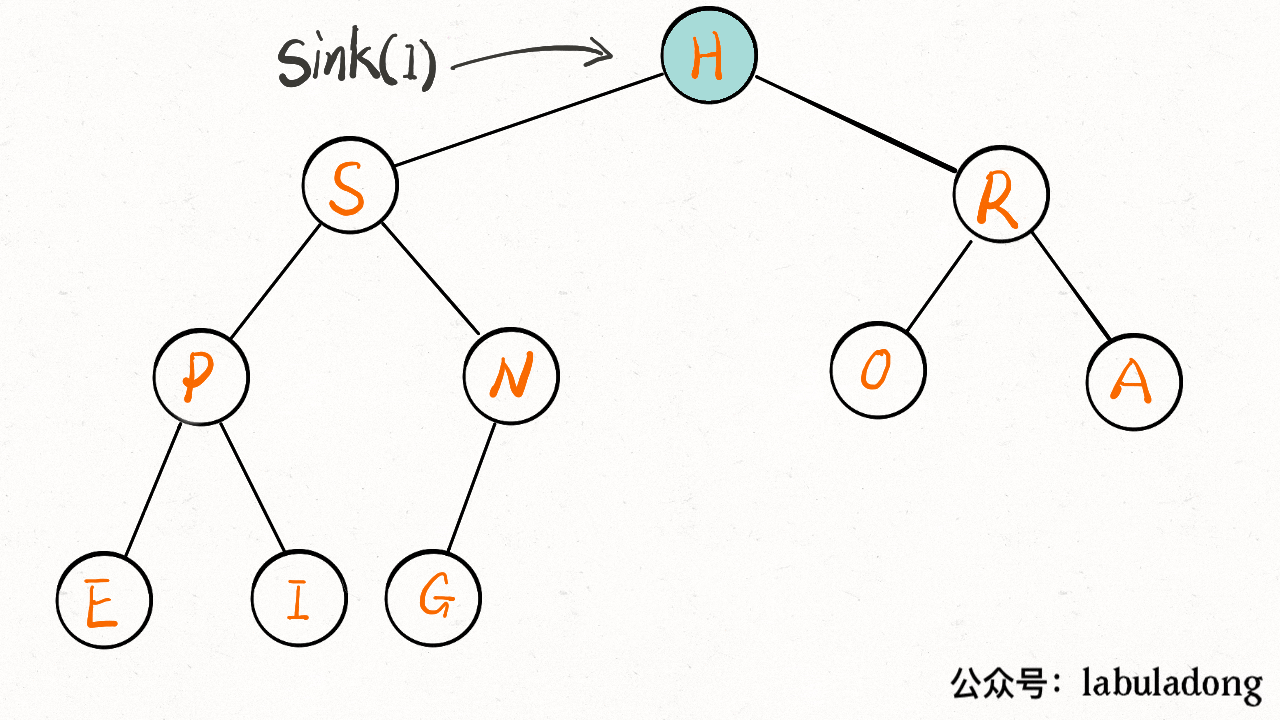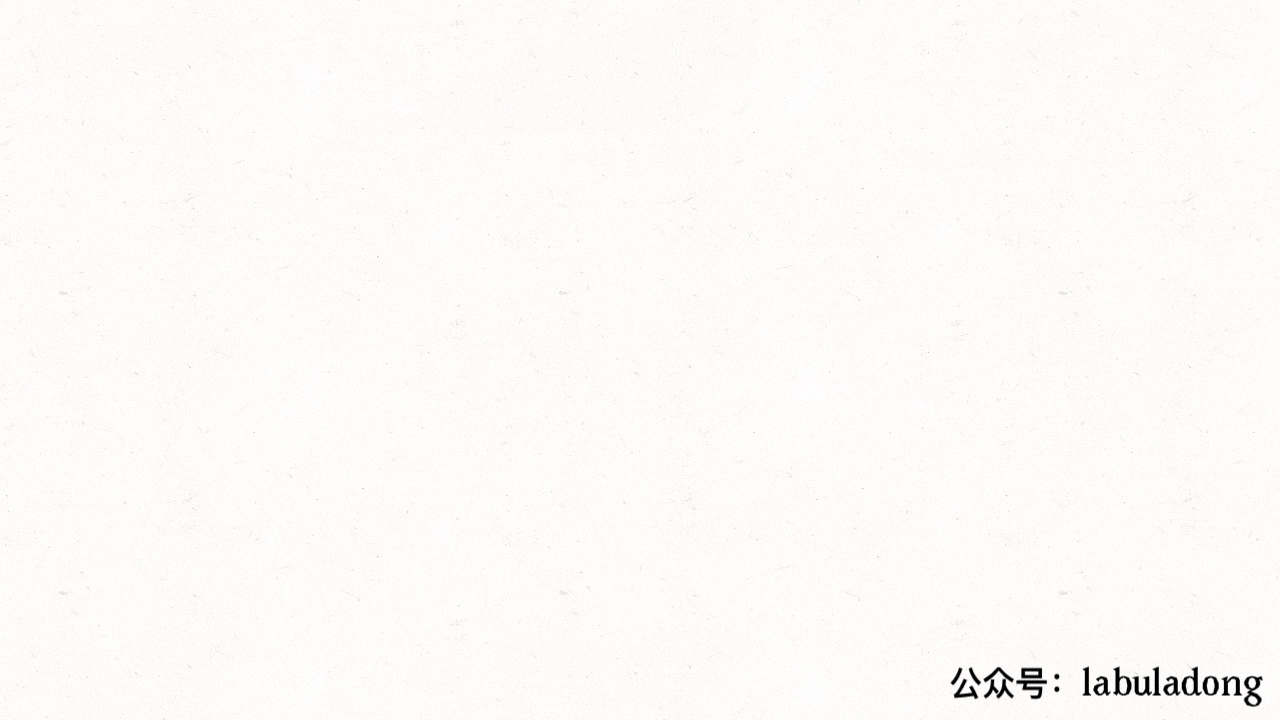
-**`delMax` 方法先把堆顶元素 A 和堆底最后的元素 B 对调,然后删除 A,最后让 B 下沉到正确位置。**
+**`delMax` 方法先把堆顶元素 `A` 和堆底最后的元素 `B` 对调,然后删除 `A`,最后让 `B` 下沉到正确位置**。
```java
public Key delMax() {
// 最大堆的堆顶就是最大元素
Key max = pq[1];
// 把这个最大元素换到最后,删除之
- exch(1, N);
- pq[N] = null;
- N--;
+ swap(1, size);
+ pq[size] = null;
+ size--;
// 让 pq[1] 下沉到正确位置
sink(1);
return max;
}
```
-
+
至此,一个优先级队列就实现了,插入和删除元素的时间复杂度为 `O(logK)`,`K` 为当前二叉堆(优先级队列)中的元素总数。因为我们时间复杂度主要花费在 `sink` 或者 `swim` 上,而不管上浮还是下沉,最多也就树(堆)的高度,也就是 log 级别。
-
### 五、最后总结
二叉堆就是一种完全二叉树,所以适合存储在数组中,而且二叉堆拥有一些特殊性质。
@@ -225,17 +228,15 @@ public Key delMax() {
也许这就是数据结构的威力,简单的操作就能实现巧妙的功能,真心佩服发明二叉堆算法的人!
-
+> 最后打个广告,我亲自制作了一门 [数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO),以视频课为主,手把手带你实现常用的数据结构及相关算法,旨在帮助算法基础较为薄弱的读者深入理解常用数据结构的底层原理,在算法学习中少走弯路。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
### javascript
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\346\240\210.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\346\240\210.md"
index d1c9f8ab4817ec80751643b628bb1d007f5c8a10..fb9d2085636bfca365257996eac602073eea04b0 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\346\240\210.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\346\240\210.md"
@@ -1,80 +1,78 @@
-# 如何使用单调栈解题
+# 特殊数据结构:单调栈
+
+
+
+
+
+
-
-
+
-相关推荐:
-* [回溯算法解题套路框架](https://labuladong.gitee.io/algo/)
- * [动态规划解题套路框架](https://labuladong.gitee.io/algo/)
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[496.下一个更大元素I](https://leetcode-cn.com/problems/next-greater-element-i)
-[503.下一个更大元素II](https://leetcode-cn.com/problems/next-greater-element-ii)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-[739.每日温度](https://leetcode-cn.com/problems/daily-temperatures/)
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [496. Next Greater Element I](https://leetcode.com/problems/next-greater-element-i/) | [496. 下一个更大元素 I](https://leetcode.cn/problems/next-greater-element-i/) | 🟢
+| [503. Next Greater Element II](https://leetcode.com/problems/next-greater-element-ii/) | [503. 下一个更大元素 II](https://leetcode.cn/problems/next-greater-element-ii/) | 🟠
+| [739. Daily Temperatures](https://leetcode.com/problems/daily-temperatures/) | [739. 每日温度](https://leetcode.cn/problems/daily-temperatures/) | 🟠
**-----------**
-栈(stack)是很简单的一种数据结构,先进后出的逻辑顺序,符合某些问题的特点,比如说函数调用栈。
+栈(stack)是很简单的一种数据结构,先进后出的逻辑顺序,符合某些问题的特点,比如说函数调用栈。单调栈实际上就是栈,只是利用了一些巧妙的逻辑,使得每次新元素入栈后,栈内的元素都保持有序(单调递增或单调递减)。
-单调栈实际上就是栈,只是利用了一些巧妙的逻辑,使得每次新元素入栈后,栈内的元素都保持有序(单调递增或单调递减)。
-
-听起来有点像堆(heap)?不是的,单调栈用途不太广泛,只处理一种典型的问题,叫做 Next Greater Element。本文用讲解单调队列的算法模版解决这类问题,并且探讨处理「循环数组」的策略。
+听起来有点像堆(heap)?不是的,单调栈用途不太广泛,只处理一类典型的问题,比如「下一个更大元素」,「上一个更小元素」等。本文用讲解单调队列的算法模版解决「下一个更大元素」相关问题,并且探讨处理「循环数组」的策略。至于其他的变体和经典例题,我会在 [数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO) 中讲解。
### 单调栈模板
-首先,看一下 Next Greater Number 的原始问题,这是力扣第 496 题「下一个更大元素 I」:
-
-给你一个数组,返回一个等长的数组,对应索引存储着下一个更大元素,如果没有更大的元素,就存 -1。
+现在给你出这么一道题:输入一个数组 `nums`,请你返回一个等长的结果数组,结果数组中对应索引存储着下一个更大元素,如果没有更大的元素,就存 -1。函数签名如下:
-函数签名如下:
-
-```cpp
-vector nextGreaterElement(vector& nums);
+```java
+int[] nextGreaterElement(int[] nums);
```
-比如说,输入一个数组 `nums = [2,1,2,4,3]`,你返回数组 `[4,2,4,-1,-1]`。
-
-解释:第一个 2 后面比 2 大的数是 4; 1 后面比 1 大的数是 2;第二个 2 后面比 2 大的数是 4; 4 后面没有比 4 大的数,填 -1;3 后面没有比 3 大的数,填 -1。
+比如说,输入一个数组 `nums = [2,1,2,4,3]`,你返回数组 `[4,2,4,-1,-1]`。因为第一个 2 后面比 2 大的数是 4; 1 后面比 1 大的数是 2;第二个 2 后面比 2 大的数是 4; 4 后面没有比 4 大的数,填 -1;3 后面没有比 3 大的数,填 -1。
这道题的暴力解法很好想到,就是对每个元素后面都进行扫描,找到第一个更大的元素就行了。但是暴力解法的时间复杂度是 `O(n^2)`。
-这个问题可以这样抽象思考:把数组的元素想象成并列站立的人,元素大小想象成人的身高。这些人面对你站成一列,如何求元素「2」的 Next Greater Number 呢?很简单,如果能够看到元素「2」,那么他后面可见的第一个人就是「2」的 Next Greater Number,因为比「2」小的元素身高不够,都被「2」挡住了,第一个露出来的就是答案。
+这个问题可以这样抽象思考:把数组的元素想象成并列站立的人,元素大小想象成人的身高。这些人面对你站成一列,如何求元素「2」的下一个更大元素呢?很简单,如果能够看到元素「2」,那么他后面可见的第一个人就是「2」的下一个更大元素,因为比「2」小的元素身高不够,都被「2」挡住了,第一个露出来的就是答案。
-
+
这个情景很好理解吧?带着这个抽象的情景,先来看下代码。
-```cpp
-vector nextGreaterElement(vector& nums) {
- vector res(nums.size()); // 存放答案的数组
- stack s;
+```java
+int[] nextGreaterElement(int[] nums) {
+ int n = nums.length;
+ // 存放答案的数组
+ int[] res = new int[n];
+ Stack s = new Stack<>();
// 倒着往栈里放
- for (int i = nums.size() - 1; i >= 0; i--) {
+ for (int i = n - 1; i >= 0; i--) {
// 判定个子高矮
- while (!s.empty() && s.top() <= nums[i]) {
+ while (!s.isEmpty() && s.peek() <= nums[i]) {
// 矮个起开,反正也被挡着了。。。
s.pop();
}
- // nums[i] 身后的 next great number
- res[i] = s.empty() ? -1 : s.top();
- //
+ // nums[i] 身后的更大元素
+ res[i] = s.isEmpty() ? -1 : s.peek();
s.push(nums[i]);
}
return res;
}
```
-这就是单调队列解决问题的模板。for 循环要从后往前扫描元素,因为我们借助的是栈的结构,倒着入栈,其实是正着出栈。while 循环是把两个「个子高」元素之间的元素排除,因为他们的存在没有意义,前面挡着个「更高」的元素,所以他们不可能被作为后续进来的元素的 Next Great Number 了。
+这就是单调队列解决问题的模板。for 循环要从后往前扫描元素,因为我们借助的是栈的结构,倒着入栈,其实是正着出栈。while 循环是把两个「个子高」元素之间的元素排除,因为他们的存在没有意义,前面挡着个「更高」的元素,所以他们不可能被作为后续进来的元素的下一个更大元素了。
这个算法的时间复杂度不是那么直观,如果你看到 for 循环嵌套 while 循环,可能认为这个算法的复杂度也是 `O(n^2)`,但是实际上这个算法的复杂度只有 `O(n)`。
@@ -82,36 +80,68 @@ vector nextGreaterElement(vector& nums) {
### 问题变形
-单调栈的使用技巧差不多了,来一个简单的变形,力扣第 739 题「每日温度」:
+单调栈的使用技巧差不多了,首先来一个简单的变形,力扣第 496 题「下一个更大元素 I」:
+
+
-给你一个数组 `T`,这个数组存放的是近几天的天气气温,你返回一个等长的数组,计算:**对于每一天,你还要至少等多少天才能等到一个更暖和的气温;如果等不到那一天,填 0**。
+这道题给你输入两个数组 `nums1` 和 `nums2`,让你求 `nums1` 中的元素在 `nums2` 中的下一个更大元素,函数签名如下:
-函数签名如下:
+```java
+int[] nextGreaterElement(int[] nums1, int[] nums2)
+```
+
+其实和把我们刚才的代码改一改就可以解决这道题了,因为题目说 `nums1` 是 `nums2` 的子集,那么我们先把 `nums2` 中每个元素的下一个更大元素算出来存到一个映射里,然后再让 `nums1` 中的元素去查表即可:
+
+```java
+int[] nextGreaterElement(int[] nums1, int[] nums2) {
+ // 记录 nums2 中每个元素的下一个更大元素
+ int[] greater = nextGreaterElement(nums2);
+ // 转化成映射:元素 x -> x 的下一个最大元素
+ HashMap greaterMap = new HashMap<>();
+ for (int i = 0; i < nums2.length; i++) {
+ greaterMap.put(nums2[i], greater[i]);
+ }
+ // nums1 是 nums2 的子集,所以根据 greaterMap 可以得到结果
+ int[] res = new int[nums1.length];
+ for (int i = 0; i < nums1.length; i++) {
+ res[i] = greaterMap.get(nums1[i]);
+ }
+ return res;
+}
-```cpp
-vector dailyTemperatures(vector& T);
+int[] nextGreaterElement(int[] nums) {
+ // 见上文
+}
```
-比如说给你输入 `T = [73,74,75,71,69,76]`,你返回 `[1,1,3,2,1,0]`。
-解释:第一天 73 华氏度,第二天 74 华氏度,比 73 大,所以对于第一天,只要等一天就能等到一个更暖和的气温,后面的同理。
+再看看力扣第 739 题「每日温度」:
+
+给你一个数组 `temperatures`,这个数组存放的是近几天的天气气温,你返回一个等长的数组,计算:对于每一天,你还要至少等多少天才能等到一个更暖和的气温;如果等不到那一天,填 0。函数签名如下:
+
+```java
+int[] dailyTemperatures(int[] temperatures);
+```
+
+比如说给你输入 `temperatures = [73,74,75,71,69,76]`,你返回 `[1,1,3,2,1,0]`。因为第一天 73 华氏度,第二天 74 华氏度,比 73 大,所以对于第一天,只要等一天就能等到一个更暖和的气温,后面的同理。
-这个问题本质上也是找 Next Greater Number,只不过现在不是问你 Next Greater Number 是多少,而是问你当前距离 Next Greater Number 的距离而已。
+这个问题本质上也是找下一个更大元素,只不过现在不是问你下一个更大元素的值是多少,而是问你当前元素距离下一个更大元素的索引距离而已。
相同的思路,直接调用单调栈的算法模板,稍作改动就可以,直接上代码吧:
-```cpp
-vector dailyTemperatures(vector& T) {
- vector res(T.size());
+```java
+int[] dailyTemperatures(int[] temperatures) {
+ int n = temperatures.length;
+ int[] res = new int[n];
// 这里放元素索引,而不是元素
- stack s;
+ Stack s = new Stack<>();
/* 单调栈模板 */
- for (int i = T.size() - 1; i >= 0; i--) {
- while (!s.empty() && T[s.top()] <= T[i]) {
+ for (int i = n - 1; i >= 0; i--) {
+ while (!s.isEmpty() && temperatures[s.peek()] <= temperatures[i]) {
s.pop();
}
// 得到索引间距
- res[i] = s.empty() ? 0 : (s.top() - i);
+ res[i] = s.isEmpty() ? 0 : (s.peek() - i);
// 将索引入栈,而不是元素
s.push(i);
}
@@ -123,44 +153,44 @@ vector dailyTemperatures(vector& T) {
### 如何处理环形数组
-同样是 Next Greater Number,现在假设给你的数组是个环形的,如何处理?力扣第 503 题「下一个更大元素 II」就是这个问题:
+同样是求下一个更大元素,现在假设给你的数组是个环形的,如何处理?力扣第 503 题「下一个更大元素 II」就是这个问题:输入一个「环形数组」,请你计算其中每个元素的下一个更大元素。
-比如输入一个数组 `[2,1,2,4,3]`,你返回数组 `[4,2,4,-1,4]`。拥有了环形属性,**最后一个元素 3 绕了一圈后找到了比自己大的元素 4**。
+比如输入 `[2,1,2,4,3]`,你应该返回 `[4,2,4,-1,4]`,因为拥有了环形属性,**最后一个元素 3 绕了一圈后找到了比自己大的元素 4**。
-一般是通过 % 运算符求模(余数),来获得环形特效:
+我们一般是通过 % 运算符求模(余数),来模拟环形特效:
```java
int[] arr = {1,2,3,4,5};
int n = arr.length, index = 0;
while (true) {
+ // 在环形数组中转圈
print(arr[index % n]);
index++;
}
```
-这个问题肯定还是要用单调栈的解题模板,但难点在于,比如输入是 `[2,1,2,4,3]`,对于最后一个元素 3,如何找到元素 4 作为 Next Greater Number。
+这个问题肯定还是要用单调栈的解题模板,但难点在于,比如输入是 `[2,1,2,4,3]`,对于最后一个元素 3,如何找到元素 4 作为下一个更大元素。
**对于这种需求,常用套路就是将数组长度翻倍**:
-
-
-这样,元素 3 就可以找到元素 4 作为 Next Greater Number 了,而且其他的元素都可以被正确地计算。
+
-有了思路,最简单的实现方式当然可以把这个双倍长度的数组构造出来,然后套用算法模板。但是,**我们可以不用构造新数组,而是利用循环数组的技巧来模拟数组长度翻倍的效果**。
+这样,元素 3 就可以找到元素 4 作为下一个更大元素了,而且其他的元素都可以被正确地计算。
-直接看代码吧:
+有了思路,最简单的实现方式当然可以把这个双倍长度的数组构造出来,然后套用算法模板。但是,**我们可以不用构造新数组,而是利用循环数组的技巧来模拟数组长度翻倍的效果**。直接看代码吧:
-```cpp
-vector nextGreaterElements(vector& nums) {
- int n = nums.size();
- vector res(n);
- stack s;
- // 假装这个数组长度翻倍了
+```java
+int[] nextGreaterElements(int[] nums) {
+ int n = nums.length;
+ int[] res = new int[n];
+ Stack s = new Stack<>();
+ // 数组长度加倍模拟环形数组
for (int i = 2 * n - 1; i >= 0; i--) {
- // 索引要求模,其他的和模板一样
- while (!s.empty() && s.top() <= nums[i % n])
+ // 索引 i 要求模,其他的和模板一样
+ while (!s.isEmpty() && s.peek() <= nums[i % n]) {
s.pop();
- res[i % n] = s.empty() ? -1 : s.top();
+ }
+ res[i % n] = s.isEmpty() ? -1 : s.peek();
s.push(nums[i % n]);
}
return res;
@@ -169,17 +199,16 @@ vector nextGreaterElements(vector& nums) {
这样,就可以巧妙解决环形数组的问题,时间复杂度 `O(N)`。
-如果本文对你有帮助,请三连,这次一定。
+最后提出一些问题吧,本文提供的单调栈模板是 `nextGreaterElement` 函数,可以计算每个元素的下一个更大元素,但如果题目让你计算上一个更大元素,或者计算上一个更大或相等的元素,应该如何修改对应的模板呢?而且在实际应用中,题目不会直接让你计算下一个(上一个)更大(小)的元素,你如何把问题转化成单调栈相关的问题呢?
+
+我会在 [单调栈的几种变体](https://appktavsiei5995.pc.xiaoe-tech.com/detail/i_628dc1ace4b09dda126cf793/1) 对比单调栈的几种其他形式,并在 [单调栈的运用](https://appktavsiei5995.pc.xiaoe-tech.com/detail/i_628dc2d7e4b0cedf38b67734/1) 中给出单调栈的经典例题。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
[496.下一个更大元素I](https://leetcode-cn.com/problems/next-greater-element-i)
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\351\230\237\345\210\227.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\351\230\237\345\210\227.md"
index d3ed0484c76467abc1e8bbddd7d0b4f96338663e..4e8f1a3d296b0912f1468ec742d5e323308b704e 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\351\230\237\345\210\227.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\215\225\350\260\203\351\230\237\345\210\227.md"
@@ -1,51 +1,84 @@
# 特殊数据结构:单调队列
+
+
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[239.滑动窗口最大值](https://leetcode-cn.com/problems/sliding-window-maximum)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [239. Sliding Window Maximum](https://leetcode.com/problems/sliding-window-maximum/) | [239. 滑动窗口最大值](https://leetcode.cn/problems/sliding-window-maximum/) | 🔴
+| - | [剑指 Offer 59 - I. 滑动窗口的最大值](https://leetcode.cn/problems/hua-dong-chuang-kou-de-zui-da-zhi-lcof/) | 🔴
+| - | [剑指 Offer 59 - II. 队列的最大值](https://leetcode.cn/problems/dui-lie-de-zui-da-zhi-lcof/) | 🟠
**-----------**
-前文讲了一种特殊的数据结构「单调栈」monotonic stack,解决了一类问题「Next Greater Number」,本文写一个类似的数据结构「单调队列」。
+前文用 [单调栈解决三道算法问题](https://labuladong.github.io/article/fname.html?fname=单调栈) 介绍了单调栈这种特殊数据结构,本文写一个类似的数据结构「单调队列」。
-也许这种数据结构的名字你没听过,其实没啥难的,就是一个「队列」,只是使用了一点巧妙的方法,使得队列中的元素单调递增(或递减)。这个数据结构有什么用?可以解决滑动窗口的一系列问题。
+也许这种数据结构的名字你没听过,其实没啥难的,就是一个「队列」,只是使用了一点巧妙的方法,使得队列中的元素全都是单调递增(或递减)的。
-看一道 LeetCode 题目,难度 hard:
+为啥要发明「单调队列」这种结构呢,主要是为了解决下面这个场景:
-
+**给你一个数组 `window`,已知其最值为 `A`,如果给 `window` 中添加一个数 `B`,那么比较一下 `A` 和 `B` 就可以立即算出新的最值;但如果要从 `window` 数组中减少一个数,就不能直接得到最值了,因为如果减少的这个数恰好是 `A`,就需要遍历 `window` 中的所有元素重新寻找新的最值**。
-### 一、搭建解题框架
+这个场景很常见,但不用单调队列似乎也可以,比如优先级队列也是一种特殊的队列,专门用来动态寻找最值的,我创建一个大(小)顶堆,不就可以很快拿到最大(小)值了吗?
-这道题不复杂,难点在于如何在 O(1) 时间算出每个「窗口」中的最大值,使得整个算法在线性时间完成。在之前我们探讨过类似的场景,得到一个结论:
+如果单纯地维护最值的话,优先级队列很专业,队头元素就是最值。但优先级队列无法满足标准队列结构「先进先出」的**时间顺序**,因为优先级队列底层利用二叉堆对元素进行动态排序,元素的出队顺序是元素的大小顺序,和入队的先后顺序完全没有关系。
-在一堆数字中,已知最值,如果给这堆数添加一个数,那么比较一下就可以很快算出最值;但如果减少一个数,就不一定能很快得到最值了,而要遍历所有数重新找最值。
+所以,现在需要一种新的队列结构,既能够维护队列元素「先进先出」的时间顺序,又能够正确维护队列中所有元素的最值,这就是「单调队列」结构。
-回到这道题的场景,每个窗口前进的时候,要添加一个数同时减少一个数,所以想在 O(1) 的时间得出新的最值,就需要「单调队列」这种特殊的数据结构来辅助了。
+「单调队列」这个数据结构主要用来辅助解决滑动窗口相关的问题,前文 [滑动窗口核心框架](https://labuladong.github.io/article/fname.html?fname=滑动窗口技巧进阶) 把滑动窗口算法作为双指针技巧的一部分进行了讲解,但有些稍微复杂的滑动窗口问题不能只靠两个指针来解决,需要上更先进的数据结构。
-一个普通的队列一定有这两个操作:
+比方说,你注意看前文 [滑动窗口核心框架](https://labuladong.github.io/article/fname.html?fname=滑动窗口技巧进阶) 讲的几道题目,每当窗口扩大(`right++`)和窗口缩小(`left++`)时,你单凭移出和移入窗口的元素即可决定是否更新答案。
+
+但就本文开头说的那个判断一个窗口中最值的例子,你就无法单凭移出窗口的那个元素更新窗口的最值,除非重新遍历所有元素,但这样的话时间复杂度就上来了,这是我们不希望看到的。
+
+我们来看看力扣第 239 题「滑动窗口最大值」,就是一道标准的滑动窗口问题:
+
+给你输入一个数组 `nums` 和一个正整数 `k`,有一个大小为 `k` 的窗口在 `nums` 上从左至右滑动,请你输出每次窗口中 `k` 个元素的最大值。
+
+函数签名如下:
+
+```java
+int[] maxSlidingWindow(int[] nums, int k);
+```
+
+比如说力扣给出的一个示例:
+
+
+
+接下来,我们就借助单调队列结构,用 `O(1)` 时间算出每个滑动窗口中的最大值,使得整个算法在线性时间完成。
+
+### 一、搭建解题框架
+
+在介绍「单调队列」这种数据结构的 API 之前,先来看看一个普通的队列的标准 API:
```java
class Queue {
+ // enqueue 操作,在队尾加入元素 n
void push(int n);
- // 或 enqueue,在队尾加入元素 n
+ // dequeue 操作,删除队头元素
void pop();
- // 或 dequeue,删除队头元素
}
```
-一个「单调队列」的操作也差不多:
+我们要实现的「单调队列」的 API 也差不多:
```java
class MonotonicQueue {
@@ -60,153 +93,190 @@ class MonotonicQueue {
当然,这几个 API 的实现方法肯定跟一般的 Queue 不一样,不过我们暂且不管,而且认为这几个操作的时间复杂度都是 O(1),先把这道「滑动窗口」问题的解答框架搭出来:
-```cpp
-vector maxSlidingWindow(vector& nums, int k) {
- MonotonicQueue window;
- vector res;
- for (int i = 0; i < nums.size(); i++) {
- if (i < k - 1) { //先把窗口的前 k - 1 填满
+```java
+int[] maxSlidingWindow(int[] nums, int k) {
+ MonotonicQueue window = new MonotonicQueue();
+ List res = new ArrayList<>();
+
+ for (int i = 0; i < nums.length; i++) {
+ if (i < k - 1) {
+ //先把窗口的前 k - 1 填满
window.push(nums[i]);
- } else { // 窗口开始向前滑动
+ } else {
+ // 窗口开始向前滑动
+ // 移入新元素
window.push(nums[i]);
- res.push_back(window.max());
+ // 将当前窗口中的最大元素记入结果
+ res.add(window.max());
+ // 移出最后的元素
window.pop(nums[i - k + 1]);
- // nums[i - k + 1] 就是窗口最后的元素
}
}
- return res;
+ // 将 List 类型转化成 int[] 数组作为返回值
+ int[] arr = new int[res.size()];
+ for (int i = 0; i < res.size(); i++) {
+ arr[i] = res.get(i);
+ }
+ return arr;
}
```
-
+
这个思路很简单,能理解吧?下面我们开始重头戏,单调队列的实现。
### 二、实现单调队列数据结构
-首先我们要认识另一种数据结构:deque,即双端队列。很简单:
-
-```java
-class deque {
- // 在队头插入元素 n
- void push_front(int n);
- // 在队尾插入元素 n
- void push_back(int n);
- // 在队头删除元素
- void pop_front();
- // 在队尾删除元素
- void pop_back();
- // 返回队头元素
- int front();
- // 返回队尾元素
- int back();
-}
-```
-
-而且,这些操作的复杂度都是 O(1)。这其实不是啥稀奇的数据结构,用链表作为底层结构的话,很容易实现这些功能。
+观察滑动窗口的过程就能发现,实现「单调队列」必须使用一种数据结构支持在头部和尾部进行插入和删除,很明显双链表是满足这个条件的。
-「单调队列」的核心思路和「单调栈」类似。单调队列的 push 方法依然在队尾添加元素,但是要把前面比新元素小的元素都删掉:
+「单调队列」的核心思路和「单调栈」类似,`push` 方法依然在队尾添加元素,但是要把前面比自己小的元素都删掉:
-```cpp
+```java
class MonotonicQueue {
-private:
- deque data;
-public:
- void push(int n) {
- while (!data.empty() && data.back() < n)
- data.pop_back();
- data.push_back(n);
+// 双链表,支持头部和尾部增删元素
+// 维护其中的元素自尾部到头部单调递增
+private LinkedList maxq = new LinkedList<>();
+
+// 在尾部添加一个元素 n,维护 maxq 的单调性质
+public void push(int n) {
+ // 将前面小于自己的元素都删除
+ while (!maxq.isEmpty() && maxq.getLast() < n) {
+ maxq.pollLast();
}
-};
+ maxq.addLast(n);
+}
```
你可以想象,加入数字的大小代表人的体重,把前面体重不足的都压扁了,直到遇到更大的量级才停住。
-
+
-如果每个元素被加入时都这样操作,最终单调队列中的元素大小就会保持一个单调递减的顺序,因此我们的 max() API 可以可以这样写:
+如果每个元素被加入时都这样操作,最终单调队列中的元素大小就会保持一个**单调递减**的顺序,因此我们的 `max` 方法可以可以这样写:
-```cpp
-int max() {
- return data.front();
+```java
+public int max() {
+ // 队头的元素肯定是最大的
+ return maxq.getFirst();
}
```
-pop() API 在队头删除元素 n,也很好写:
+`pop` 方法在队头删除元素 `n`,也很好写:
-```cpp
-void pop(int n) {
- if (!data.empty() && data.front() == n)
- data.pop_front();
+```java
+public void pop(int n) {
+ if (n == maxq.getFirst()) {
+ maxq.pollFirst();
+ }
}
```
-之所以要判断 `data.front() == n`,是因为我们想删除的队头元素 n 可能已经被「压扁」了,这时候就不用删除了:
+之所以要判断 `data.getFirst() == n`,是因为我们想删除的队头元素 `n` 可能已经被「压扁」了,可能已经不存在了,所以这时候就不用删除了:
-
+
至此,单调队列设计完毕,看下完整的解题代码:
-```cpp
+```java
+/* 单调队列的实现 */
class MonotonicQueue {
-private:
- deque data;
-public:
- void push(int n) {
- while (!data.empty() && data.back() < n)
- data.pop_back();
- data.push_back(n);
+ LinkedList maxq = new LinkedList<>();
+ public void push(int n) {
+ // 将小于 n 的元素全部删除
+ while (!maxq.isEmpty() && maxq.getLast() < n) {
+ maxq.pollLast();
+ }
+ // 然后将 n 加入尾部
+ maxq.addLast(n);
}
- int max() { return data.front(); }
+ public int max() {
+ return maxq.getFirst();
+ }
- void pop(int n) {
- if (!data.empty() && data.front() == n)
- data.pop_front();
+ public void pop(int n) {
+ if (n == maxq.getFirst()) {
+ maxq.pollFirst();
+ }
}
-};
+}
-vector maxSlidingWindow(vector& nums, int k) {
- MonotonicQueue window;
- vector res;
- for (int i = 0; i < nums.size(); i++) {
- if (i < k - 1) { //先填满窗口的前 k - 1
+/* 解题函数的实现 */
+int[] maxSlidingWindow(int[] nums, int k) {
+ MonotonicQueue window = new MonotonicQueue();
+ List res = new ArrayList<>();
+
+ for (int i = 0; i < nums.length; i++) {
+ if (i < k - 1) {
+ //先填满窗口的前 k - 1
window.push(nums[i]);
- } else { // 窗口向前滑动
+ } else {
+ // 窗口向前滑动,加入新数字
window.push(nums[i]);
- res.push_back(window.max());
+ // 记录当前窗口的最大值
+ res.add(window.max());
+ // 移出旧数字
window.pop(nums[i - k + 1]);
}
}
- return res;
+ // 需要转成 int[] 数组再返回
+ int[] arr = new int[res.size()];
+ for (int i = 0; i < res.size(); i++) {
+ arr[i] = res.get(i);
+ }
+ return arr;
}
```
-**三、算法复杂度分析**
+有一点细节问题不要忽略,在实现 `MonotonicQueue` 时,我们使用了 Java 的 `LinkedList`,因为链表结构支持在头部和尾部快速增删元素;而在解法代码中的 `res` 则使用的 `ArrayList` 结构,因为后续会按照索引取元素,所以数组结构更合适。
+
+关于单调队列 API 的时间复杂度,读者可能有疑惑:`push` 操作中含有 while 循环,时间复杂度应该不是 `O(1)` 呀,那么本算法的时间复杂度应该不是线性时间吧?
+
+这里就用到了 [算法时空复杂度分析使用手册](https://labuladong.github.io/article/fname.html?fname=时间复杂度) 中讲到的摊还分析:
+
+单独看 `push` 操作的复杂度确实不是 `O(1)`,但是算法整体的复杂度依然是 `O(N)` 线性时间。要这样想,`nums` 中的每个元素最多被 `push` 和 `pop` 一次,没有任何多余操作,所以整体的复杂度还是 `O(N)`。空间复杂度就很简单了,就是窗口的大小 `O(k)`。
+
+### 拓展延伸
+
+最后,我提出几个问题请大家思考:
+
+1、本文给出的 `MonotonicQueue` 类只实现了 `max` 方法,你是否能够再额外添加一个 `min` 方法,在 `O(1)` 的时间返回队列中所有元素的最小值?
+
+2、本文给出的 `MonotonicQueue` 类的 `pop` 方法还需要接收一个参数,这显然有悖于标准队列的做法,请你修复这个缺陷。
-读者可能疑惑,push 操作中含有 while 循环,时间复杂度不是 O(1) 呀,那么本算法的时间复杂度应该不是线性时间吧?
+3、请你实现 `MonotonicQueue` 类的 `size` 方法,返回单调队列中元素的个数(注意,由于每次 `push` 方法都可能从底层的 `q` 列表中删除元素,所以 `q` 中的元素个数并不是单调队列的元素个数)。
-单独看 push 操作的复杂度确实不是 O(1),但是算法整体的复杂度依然是 O(N) 线性时间。要这样想,nums 中的每个元素最多被 push_back 和 pop_back 一次,没有任何多余操作,所以整体的复杂度还是 O(N)。
+也就是说,你是否能够实现单调队列的通用实现:
-空间复杂度就很简单了,就是窗口的大小 O(k)。
+```java
+/* 单调队列的通用实现,可以高效维护最大值和最小值 */
+class MonotonicQueue> {
+
+ // 标准队列 API,向队尾加入元素
+ public void push(E elem);
-**四、最后总结**
+ // 标准队列 API,从队头弹出元素,符合先进先出的顺序
+ public E pop();
-有的读者可能觉得「单调队列」和「优先级队列」比较像,实际上差别很大的。
+ // 标准队列 API,返回队列中的元素个数
+ public int size();
-单调队列在添加元素的时候靠删除元素保持队列的单调性,相当于抽取出某个函数中单调递增(或递减)的部分;而优先级队列(二叉堆)相当于自动排序,差别大了去了。
+ // 单调队列特有 API,O(1) 时间计算队列中元素的最大值
+ public E max();
+
+ // 单调队列特有 API,O(1) 时间计算队列中元素的最小值
+ public E min();
+}
+```
-赶紧去拿下 LeetCode 第 239 道题吧~
+我将在 [单调队列通用实现及应用](https://appktavsiei5995.pc.xiaoe-tech.com/detail/i_62a692efe4b01a48520b9b9b/1) 中给出单调队列的通用实现和经典习题。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[239.滑动窗口最大值](https://leetcode-cn.com/problems/sliding-window-maximum)
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\256\236\347\216\260\350\256\241\347\256\227\345\231\250.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\256\236\347\216\260\350\256\241\347\256\227\345\231\250.md"
index f4b740122071c80f52a93bf6145d8a10357e9fde..04c9ee47374abd2c1adb04dc64b48adb22a8ead6 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\256\236\347\216\260\350\256\241\347\256\227\345\231\250.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\345\256\236\347\216\260\350\256\241\347\256\227\345\231\250.md"
@@ -2,30 +2,34 @@
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[224.基本计算器](https://leetcode-cn.com/problems/basic-calculator)
-[227.基本计算器II](https://leetcode-cn.com/problems/basic-calculator-ii)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-[772.基本计算器III](https://leetcode-cn.com/problems/basic-calculator-iii)
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [224. Basic Calculator](https://leetcode.com/problems/basic-calculator/) | [224. 基本计算器](https://leetcode.cn/problems/basic-calculator/) | 🔴
+| [227. Basic Calculator II](https://leetcode.com/problems/basic-calculator-ii/) | [227. 基本计算器 II](https://leetcode.cn/problems/basic-calculator-ii/) | 🟠
+| [772. Basic Calculator III](https://leetcode.com/problems/basic-calculator-iii/)🔒 | [772. 基本计算器 III](https://leetcode.cn/problems/basic-calculator-iii/)🔒 | 🔴
**-----------**
我们最终要实现的计算器功能如下:
-1、输入一个字符串,可以包含`+ - * /`、数字、括号以及空格,你的算法返回运算结果。
+1、输入一个字符串,可以包含 `+ - * /`、数字、括号以及空格,你的算法返回运算结果。
2、要符合运算法则,括号的优先级最高,先乘除后加减。
@@ -35,7 +39,12 @@
比如输入如下字符串,算法会返回 9:
-`3 * (2-6 /(3 -7))`
+```java
+ 3 * (2 - 6 / (3 - 7))
+= 3 * (2 - 6 / (-4))
+= 3 * (2 - (-1))
+= 9
+```
可以看到,这就已经非常接近我们实际生活中使用的计算器了,虽然我们以前肯定都用过计算器,但是如果简单思考一下其算法实现,就会大惊失色:
@@ -47,7 +56,7 @@
我记得很多大学数据结构的教材上,在讲栈这种数据结构的时候,应该都会用计算器举例,但是有一说一,讲的真的垃圾,不知道多少未来的计算机科学家就被这种简单的数据结构劝退了。
-那么本文就来聊聊怎么实现上述一个功能完备的计算器功能,**关键在于层层拆解问题,化整为零,逐个击破**,相信这种思维方式能帮大家解决各种复杂问题。
+那么本文就来聊聊怎么实现上述一个功能完备的计算器功能,**关键在于层层拆解问题,化整为零,逐个击破**,几条简单的算法规则就可以处理极其复杂的运算,相信这种思维方式能帮大家解决各种复杂问题。
下面就来拆解,从最简单的一个问题开始。
@@ -66,17 +75,17 @@ for (int i = 0; i < s.size(); i++) {
// n 现在就等于 458
```
-这个还是很简单的吧,老套路了。但是即便这么简单,依然有坑:**`(c - '0')`的这个括号不能省略,否则可能造成整型溢出**。
+这个还是很简单的吧,老套路了。但是即便这么简单,依然有坑:**`(c - '0')` 的这个括号不能省略,否则可能造成整型溢出**。
-因为变量`c`是一个 ASCII 码,如果不加括号就会先加后减,想象一下`s`如果接近 INT_MAX,就会溢出。所以用括号保证先减后加才行。
+因为变量 `c` 是一个 ASCII 码,如果不加括号就会先加后减,想象一下 `s` 如果接近 INT_MAX,就会溢出。所以用括号保证先减后加才行。
### 二、处理加减法
-现在进一步,**如果输入的这个算式只包含加减法,而且不存在空格**,你怎么计算结果?我们拿字符串算式`1-12+3`为例,来说一个很简单的思路:
+现在进一步,**如果输入的这个算式只包含加减法,而且不存在空格**,你怎么计算结果?我们拿字符串算式 `1-12+3` 为例,来说一个很简单的思路:
-1、先给第一个数字加一个默认符号`+`,变成`+1-12+3`。
+1、先给第一个数字加一个默认符号 `+`,变成 `+1-12+3`。
-2、把一个运算符和数字组合成一对儿,也就是三对儿`+1`,`-12`,`+3`,把它们转化成数字,然后放到一个栈中。
+2、把一个运算符和数字组合成一对儿,也就是三对儿 `+1`,`-12`,`+3`,把它们转化成数字,然后放到一个栈中。
3、将栈中所有的数字求和,就是原算式的结果。
@@ -118,23 +127,23 @@ int calculate(string s) {
}
```
-我估计就是中间带`switch`语句的部分有点不好理解吧,`i`就是从左到右扫描,`sign`和`num`跟在它身后。当`s[i]`遇到一个运算符时,情况是这样的:
+我估计就是中间带 `switch` 语句的部分有点不好理解吧,`i` 就是从左到右扫描,`sign` 和 `num` 跟在它身后。当 `s[i]` 遇到一个运算符时,情况是这样的:
-
+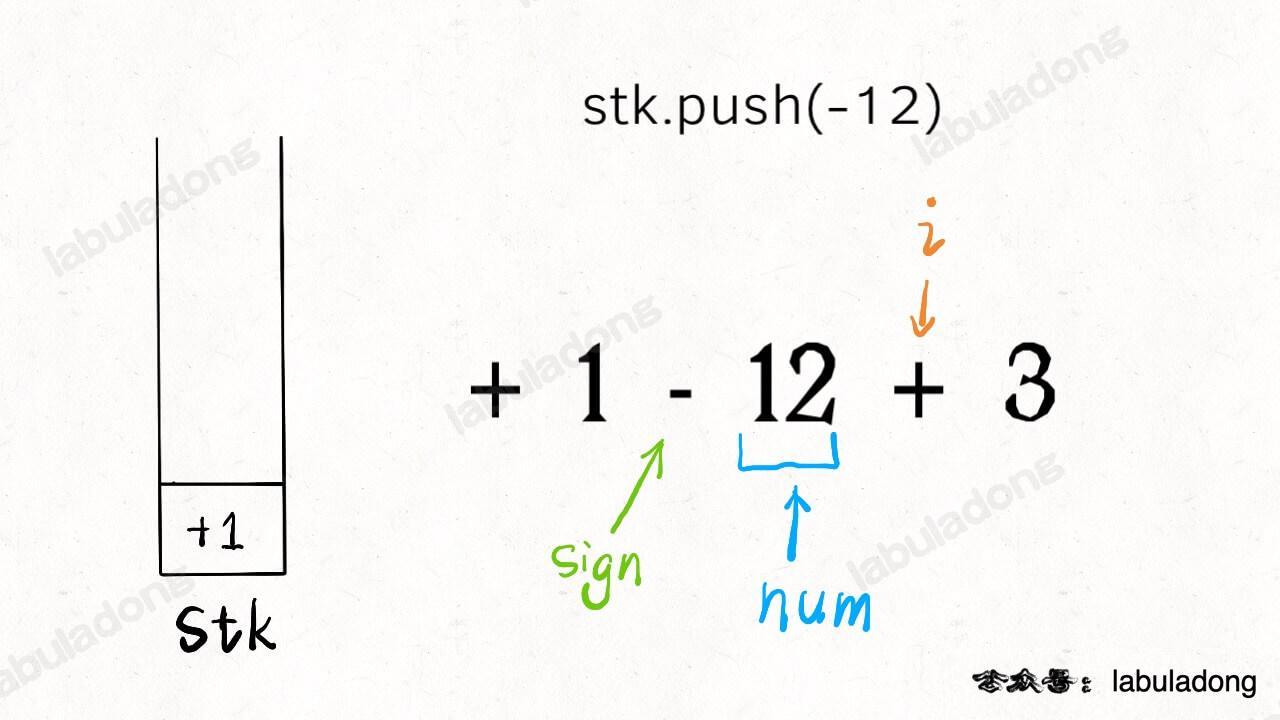
-所以说,此时要根据`sign`的 case 不同选择`nums`的正负号,存入栈中,然后更新`sign`并清零`nums`记录下一对儿符合和数字的组合。
+所以说,此时要根据 `sign` 的 case 不同选择 `nums` 的正负号,存入栈中,然后更新 `sign` 并清零 `nums` 记录下一对儿符合和数字的组合。
-另外注意,不只是遇到新的符号会触发入栈,当`i`走到了算式的尽头(`i == s.size() - 1`),也应该将前面的数字入栈,方便后续计算最终结果。
+另外注意,不只是遇到新的符号会触发入栈,当 `i` 走到了算式的尽头(`i == s.size() - 1` ),也应该将前面的数字入栈,方便后续计算最终结果。
-
+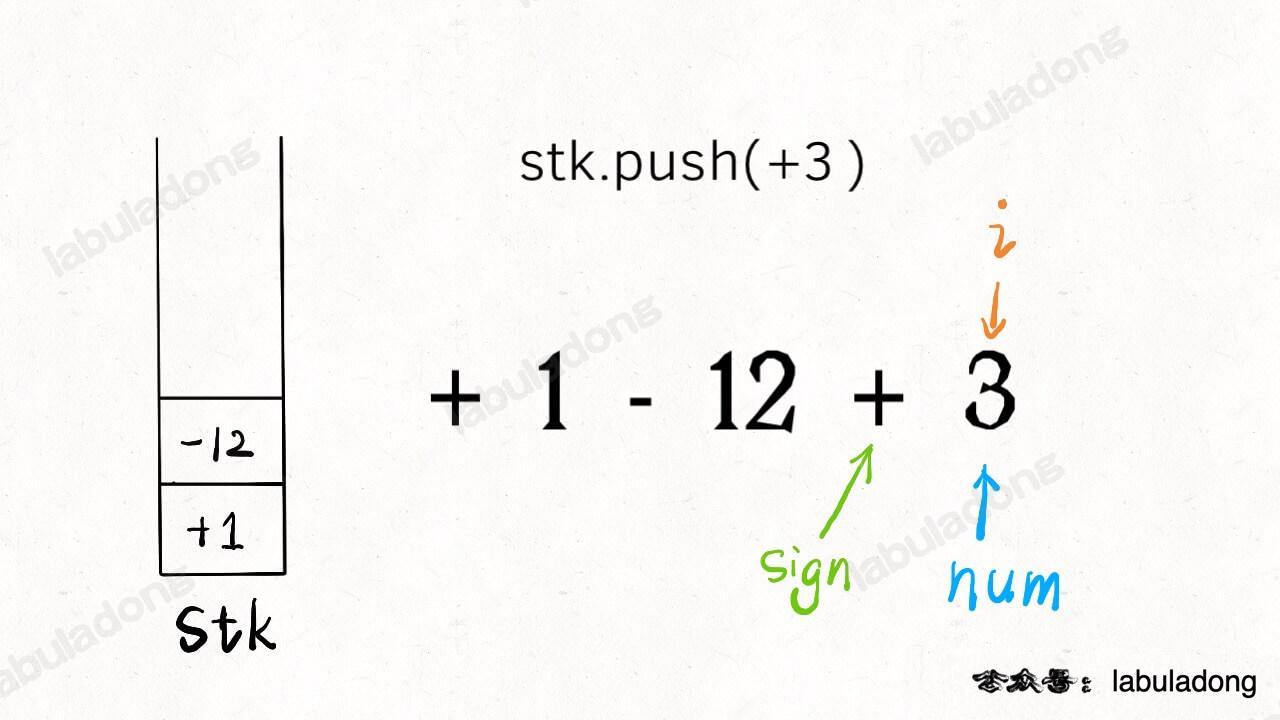
至此,仅处理紧凑加减法字符串的算法就完成了,请确保理解以上内容,后续的内容就基于这个框架修修改改就完事儿了。
### 三、处理乘除法
-其实思路跟仅处理加减法没啥区别,拿字符串`2-3*4+5`举例,核心思路依然是把字符串分解成符号和数字的组合。
+其实思路跟仅处理加减法没啥区别,拿字符串 `2-3*4+5` 举例,核心思路依然是把字符串分解成符号和数字的组合。
-比如上述例子就可以分解为`+2`,`-3`,`*4`,`+5`几对儿,我们刚才不是没有处理乘除号吗,很简单,**其他部分都不用变**,在`switch`部分加上对应的 case 就行了:
+比如上述例子就可以分解为 `+2`,`-3`,`*4`,`+5` 几对儿,我们刚才不是没有处理乘除号吗,很简单,**其他部分都不用变**,在 `switch` 部分加上对应的 case 就行了:
```cpp
for (int i = 0; i < s.size(); i++) {
@@ -168,7 +177,7 @@ for (int i = 0; i < s.size(); i++) {
}
```
-
+
**乘除法优先于加减法体现在,乘除法可以和栈顶的数结合,而加减法只能把自己放入栈**。
@@ -183,7 +192,7 @@ if (!isdigit(c) || i == s.size() - 1) {
}
```
-显然空格会进入这个 if 语句,但是我们并不想让空格的情况进入这个 if,因为这里会更新`sign`并清零`nums`,空格根本就不是运算符,应该被忽略。
+显然空格会进入这个 if 语句,但是我们并不想让空格的情况进入这个 if,因为这里会更新 `sign` 并清零 `nums`,空格根本就不是运算符,应该被忽略。
那么只要多加一个条件即可:
@@ -228,22 +237,24 @@ def calculate(s: str) -> int:
sign = c
return sum(stack)
- # 需要把字符串转成列表方便操作
- return helper(list(s))
+ # 需要把字符串转成双端队列方便操作
+ return helper(collections.deque(s))
```
-这段代码跟刚才 C++ 代码完全相同,唯一的区别是,不是从左到右遍历字符串,而是不断从左边`pop`出字符,本质还是一样的。
+这段代码跟刚才 C++ 代码完全相同,唯一的区别是,不是从左到右遍历字符串,而是不断从左边 `pop` 出字符,本质还是一样的。
-那么,为什么说处理括号没有看起来那么难呢,**因为括号具有递归性质**。我们拿字符串`3*(4-5/2)-6`举例:
+那么,为什么说处理括号没有看起来那么难呢,**因为括号具有递归性质**。我们拿字符串 `3*(4-5/2)-6` 举例:
-calculate(`3*(4-5/2)-6`)
-= 3 * calculate(`4-5/2`) - 6
+```java
+calculate(3 * (4 - 5/2) - 6)
+= 3 * calculate(4 - 5/2) - 6
= 3 * 2 - 6
= 0
+```
可以脑补一下,无论多少层括号嵌套,通过 calculate 函数递归调用自己,都可以将括号中的算式化简成一个数字。**换句话说,括号包含的算式,我们直接视为一个数字就行了**。
-现在的问题是,递归的开始条件和结束条件是什么?**遇到`(`开始递归,遇到`)`结束递归**:
+现在的问题是,递归的开始条件和结束条件是什么?**遇到 `(` 开始递归,遇到 `)` 结束递归**:
```python
def calculate(s: str) -> int:
@@ -254,7 +265,7 @@ def calculate(s: str) -> int:
num = 0
while len(s) > 0:
- c = s.pop(0)
+ c = s.popleft()
if c.isdigit():
num = 10 * num + int(c)
# 遇到左括号开始递归计算 num
@@ -262,24 +273,29 @@ def calculate(s: str) -> int:
num = helper(s)
if (not c.isdigit() and c != ' ') or len(s) == 0:
- if sign == '+': ...
- elif sign == '-': ...
- elif sign == '*': ...
- elif sign == '/': ...
+ if sign == '+':
+ stack.append(num)
+ elif sign == '-':
+ stack.append(-num)
+ elif sign == '*':
+ stack[-1] = stack[-1] * num
+ elif sign == '/':
+ # python 除法向 0 取整的写法
+ stack[-1] = int(stack[-1] / float(num))
num = 0
sign = c
# 遇到右括号返回递归结果
if c == ')': break
return sum(stack)
- return helper(list(s))
+ return helper(collections.deque(s))
```
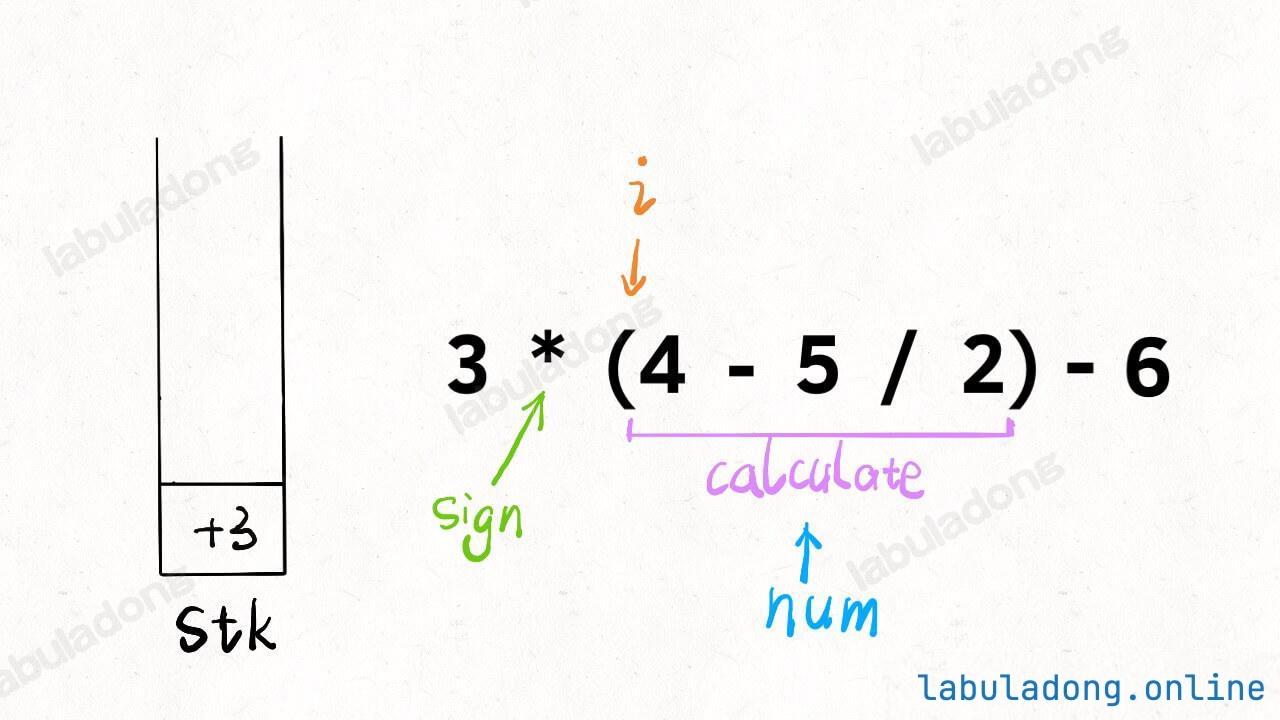
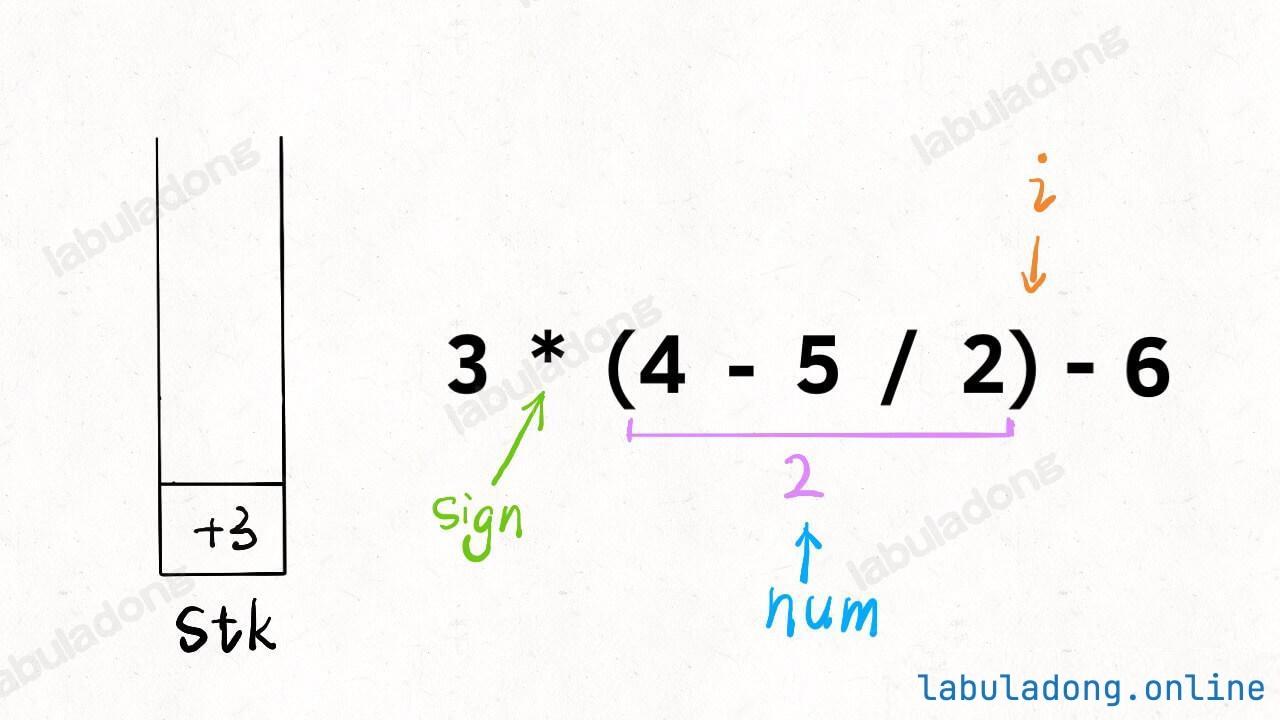
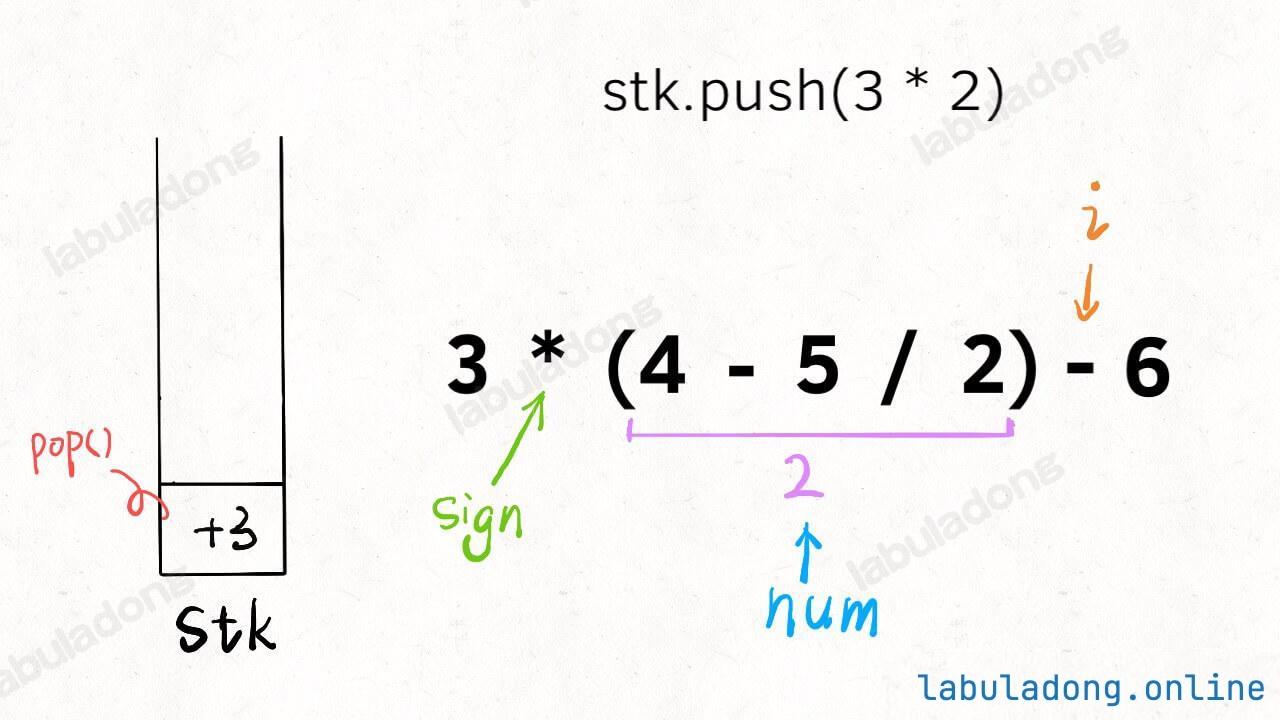
-
+
-
+
-
+
你看,加了两三行代码,就可以处理括号了,这就是递归的魅力。至此,计算器的全部功能就实现了,通过对问题的层层拆解化整为零,再回头看,这个问题似乎也没那么复杂嘛。
@@ -293,16 +309,12 @@ def calculate(s: str) -> int:
**退而求其次是一种很聪明策略**。你想想啊,假设这是一道考试题,你不会实现这个计算器,但是你写了字符串转整数的算法并指出了容易溢出的陷阱,那起码可以得 20 分吧;如果你能够处理加减法,那可以得 40 分吧;如果你能处理加减乘除四则运算,那起码够 70 分了;再加上处理空格字符,80 有了吧。我就是不会处理括号,那就算了,80 已经很 OK 了好不好。
-
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\350\256\276\350\256\241Twitter.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\350\256\276\350\256\241Twitter.md"
index ae61622934b0ecc7e2fc90741cadb50ffed3acfa..0144a6072613875cb54c850220e656f08b664551 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\350\256\276\350\256\241Twitter.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\350\256\276\350\256\241Twitter.md"
@@ -1,24 +1,31 @@
# 设计Twitter
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[355.设计推特](https://leetcode-cn.com/problems/design-twitter)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [355. Design Twitter](https://leetcode.com/problems/design-twitter/) | [355. 设计推特](https://leetcode.cn/problems/design-twitter/) | 🟠
**-----------**
-「design Twitter」是 LeetCode 上第 355 道题目,不仅题目本身很有意思,而且把合并多个有序链表的算法和面向对象设计(OO design)结合起来了,很有实际意义,本文就带大家来看看这道题。
+力扣第 355 「设计推特」不仅题目本身很有意思,而且把合并多个有序链表的算法和面向对象设计(OO design)结合起来了,很有实际意义,本文就带大家来看看这道题。
至于 Twitter 的什么功能跟算法有关系,等我们描述一下题目要求就知道了。
@@ -120,13 +127,13 @@ class Tweet {
}
```
-
+
**2、User 类的实现**
我们根据实际场景想一想,一个用户需要存储的信息有 userId,关注列表,以及该用户发过的推文列表。其中关注列表应该用集合(Hash Set)这种数据结构来存,因为不能重复,而且需要快速查找;推文列表应该由链表这种数据结构储存,以便于进行有序合并的操作。画个图理解一下:
-
+
除此之外,根据面向对象的设计原则,「关注」「取关」和「发文」应该是 User 的行为,况且关注列表和推文列表也存储在 User 类中,所以我们也应该给 User 添加 follow,unfollow 和 post 这几个方法:
@@ -269,11 +276,10 @@ public List getNewsFeed(int userId) {
这个过程是这样的,下面是我制作的一个 GIF 图描述合并链表的过程。假设有三个 Tweet 链表按 time 属性降序排列,我们把他们降序合并添加到 res 中。注意图中链表节点中的数字是 time 属性,不是 id 属性:
-
+
至此,这道一个极其简化的 Twitter 时间线功能就设计完毕了。
-
### 四、最后总结
本文运用简单的面向对象技巧和合并 k 个有序链表的算法设计了一套简化的时间线功能,这个功能其实广泛地运用在许多社交应用中。
@@ -282,23 +288,19 @@ public List getNewsFeed(int userId) {
当然,实际应用中的社交 App 数据量是巨大的,考虑到数据库的读写性能,我们的设计可能承受不住流量压力,还是有些太简化了。而且实际的应用都是一个极其庞大的工程,比如下图,是 Twitter 这样的社交网站大致的系统结构:
-
+
我们解决的问题应该只能算 Timeline Service 模块的一小部分,功能越多,系统的复杂性可能是指数级增长的。所以说合理的顶层设计十分重要,其作用是远超某一个算法的。
最后,Github 上有一个优秀的开源项目,专门收集了很多大型系统设计的案例和解析,而且有中文版本,上面这个图也出自该项目。对系统设计感兴趣的读者可以点击 [这里](https://github.com/donnemartin/system-design-primer) 查看。
-PS:本文前两张图片和 GIF 是我第一次尝试用平板的绘图软件制作的,花了很多时间,尤其是 GIF 图,需要一帧一帧制作。如果本文内容对你有帮助,点个赞分个享,鼓励一下我呗!
-
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[355.设计推特](https://leetcode-cn.com/problems/design-twitter)
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\200\222\345\275\222\345\217\215\350\275\254\351\223\276\350\241\250\347\232\204\344\270\200\351\203\250\345\210\206.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\200\222\345\275\222\345\217\215\350\275\254\351\223\276\350\241\250\347\232\204\344\270\200\351\203\250\345\210\206.md"
index 27f7666eb462b0c0ca13f8d3e6c3debf0442b02b..28ea9eeb9801aa80a11ffff17a96299544efba06 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\200\222\345\275\222\345\217\215\350\275\254\351\223\276\350\241\250\347\232\204\344\270\200\351\203\250\345\210\206.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\200\222\345\275\222\345\217\215\350\275\254\351\223\276\350\241\250\347\232\204\344\270\200\351\203\250\345\210\206.md"
@@ -1,20 +1,30 @@
# 递归反转链表的一部分
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[92.反转链表II](https://leetcode-cn.com/problems/reverse-linked-list-ii/)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [206. Reverse Linked List](https://leetcode.com/problems/reverse-linked-list/) | [206. 反转链表](https://leetcode.cn/problems/reverse-linked-list/) | 🟢
+| [92. Reverse Linked List II](https://leetcode.com/problems/reverse-linked-list-ii/) | [92. 反转链表 II](https://leetcode.cn/problems/reverse-linked-list-ii/) | 🟠
+| - | [剑指 Offer 24. 反转链表](https://leetcode.cn/problems/fan-zhuan-lian-biao-lcof/) | 🟢
+| - | [剑指 Offer II 024. 反转链表](https://leetcode.cn/problems/UHnkqh/) | 🟢
**-----------**
@@ -31,9 +41,11 @@ public class ListNode {
}
```
-什么叫反转单链表的一部分呢,就是给你一个索引区间,让你把单链表中这部分元素反转,其他部分不变:
+什么叫反转单链表的一部分呢,就是给你一个索引区间,让你把单链表中这部分元素反转,其他部分不变。
+
+看下力扣第 92 题「反转链表 II」:
-
+
**注意这里的索引是从 1 开始的**。迭代的思路大概是:先用一个 for 循环找到第 `m` 个位置,然后再用一个 for 循环将 `m` 和 `n` 之间的元素反转。但是我们的递归解法不用一个 for 循环,纯递归实现反转。
@@ -41,11 +53,14 @@ public class ListNode {
### 一、递归反转整个链表
-这个算法可能很多读者都听说过,这里详细介绍一下,先直接看实现代码:
+这也是力扣第 206 题「反转链表」,递归反转单链表的算法可能很多读者都听说过,这里详细介绍一下,直接看代码实现:
```java
+// 定义:输入一个单链表头结点,将该链表反转,返回新的头结点
ListNode reverse(ListNode head) {
- if (head.next == null) return head;
+ if (head == null || head.next == null) {
+ return head;
+ }
ListNode last = reverse(head.next);
head.next.next = head;
head.next = null;
@@ -59,9 +74,9 @@ ListNode reverse(ListNode head) {
**输入一个节点 `head`,将「以 `head` 为起点」的链表反转,并返回反转之后的头结点**。
-明白了函数的定义,在来看这个问题。比如说我们想反转这个链表:
+明白了函数的定义,再来看这个问题。比如说我们想反转这个链表:
-
+
那么输入 `reverse(head)` 后,会在这里进行递归:
@@ -71,11 +86,11 @@ ListNode last = reverse(head.next);
不要跳进递归(你的脑袋能压几个栈呀?),而是要根据刚才的函数定义,来弄清楚这段代码会产生什么结果:
-
+
这个 `reverse(head.next)` 执行完成后,整个链表就成了这样:
-
+
并且根据函数定义,`reverse` 函数会返回反转之后的头结点,我们用变量 `last` 接收了。
@@ -85,7 +100,7 @@ ListNode last = reverse(head.next);
head.next.next = head;
```
-
+
接下来:
@@ -94,17 +109,19 @@ head.next = null;
return last;
```
-
+
神不神奇,这样整个链表就反转过来了!递归代码就是这么简洁优雅,不过其中有两个地方需要注意:
1、递归函数要有 base case,也就是这句:
```java
-if (head.next == null) return head;
+if (head == null || head.next == null) {
+ return head;
+}
```
-意思是如果链表只有一个节点的时候反转也是它自己,直接返回即可。
+意思是如果链表为空或者只有一个节点的时候,反转结果就是它自己,直接返回即可。
2、当链表递归反转之后,新的头结点是 `last`,而之前的 `head` 变成了最后一个节点,别忘了链表的末尾要指向 null:
@@ -125,7 +142,7 @@ ListNode reverseN(ListNode head, int n)
比如说对于下图链表,执行 `reverseN(head, 3)`:
-
+
解决思路和反转整个链表差不多,只要稍加修改即可:
@@ -134,7 +151,7 @@ ListNode successor = null; // 后驱节点
// 反转以 head 为起点的 n 个节点,返回新的头结点
ListNode reverseN(ListNode head, int n) {
- if (n == 1) {
+ if (n == 1) {
// 记录第 n + 1 个节点
successor = head.next;
return head;
@@ -146,22 +163,22 @@ ListNode reverseN(ListNode head, int n) {
// 让反转之后的 head 节点和后面的节点连起来
head.next = successor;
return last;
-}
+}
```
具体的区别:
1、base case 变为 `n == 1`,反转一个元素,就是它本身,同时**要记录后驱节点**。
-2、刚才我们直接把 `head.next` 设置为 null,因为整个链表反转后原来的 `head` 变成了整个链表的最后一个节点。但现在 `head` 节点在递归反转之后不一定是最后一个节点了,所以要记录后驱 `successor`(第 n + 1 个节点),反转之后将 `head` 连接上。
+2、刚才我们直接把 `head.next` 设置为 null,因为整个链表反转后原来的 `head` 变成了整个链表的最后一个节点。但现在 `head` 节点在递归反转之后不一定是最后一个节点了,所以要记录后驱 `successor`(第 `n + 1` 个节点),反转之后将 `head` 连接上。
-
+
OK,如果这个函数你也能看懂,就离实现「反转一部分链表」不远了。
### 三、反转链表的一部分
-现在解决我们最开始提出的问题,给一个索引区间 `[m,n]`(索引从 1 开始),仅仅反转区间中的链表元素。
+现在解决我们最开始提出的问题,给一个索引区间 `[m, n]`(索引从 1 开始),仅仅反转区间中的链表元素。
```java
ListNode reverseBetween(ListNode head, int m, int n)
@@ -206,15 +223,15 @@ ListNode reverseBetween(ListNode head, int m, int n) {
值得一提的是,递归操作链表并不高效。和迭代解法相比,虽然时间复杂度都是 O(N),但是迭代解法的空间复杂度是 O(1),而递归解法需要堆栈,空间复杂度是 O(N)。所以递归操作链表可以作为对递归算法的练习或者拿去和小伙伴装逼,但是考虑效率的话还是使用迭代算法更好。
+> 最后打个广告,我亲自制作了一门 [数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO),以视频课为主,手把手带你实现常用的数据结构及相关算法,旨在帮助算法基础较为薄弱的读者深入理解常用数据结构的底层原理,在算法学习中少走弯路。
+
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[92.反转链表II](https://leetcode-cn.com/problems/reverse-linked-list-ii/)
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\230\237\345\210\227\345\256\236\347\216\260\346\240\210\346\240\210\345\256\236\347\216\260\351\230\237\345\210\227.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\230\237\345\210\227\345\256\236\347\216\260\346\240\210\346\240\210\345\256\236\347\216\260\351\230\237\345\210\227.md"
index 62ba35500b838da81d28a39ca854a072ee80f24c..c0587c49cb8c46feffdabcd4b301b8f438afd4ab 100644
--- "a/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\230\237\345\210\227\345\256\236\347\216\260\346\240\210\346\240\210\345\256\236\347\216\260\351\230\237\345\210\227.md"
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204\347\263\273\345\210\227/\351\230\237\345\210\227\345\256\236\347\216\260\346\240\210\346\240\210\345\256\236\347\216\260\351\230\237\345\210\227.md"
@@ -1,34 +1,41 @@
# 队列实现栈|栈实现队列
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[232.用栈实现队列](https://leetcode-cn.com/problems/implement-queue-using-stacks)
-[225.用队列实现栈](https://leetcode-cn.com/problems/implement-stack-using-queues)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [225. Implement Stack using Queues](https://leetcode.com/problems/implement-stack-using-queues/) | [225. 用队列实现栈](https://leetcode.cn/problems/implement-stack-using-queues/) | 🟢
+| [232. Implement Queue using Stacks](https://leetcode.com/problems/implement-queue-using-stacks/) | [232. 用栈实现队列](https://leetcode.cn/problems/implement-queue-using-stacks/) | 🟢
+| - | [剑指 Offer 09. 用两个栈实现队列](https://leetcode.cn/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof/) | 🟢
**-----------**
队列是一种先进先出的数据结构,栈是一种先进后出的数据结构,形象一点就是这样:
-
+
这两种数据结构底层其实都是数组或者链表实现的,只是 API 限定了它们的特性,那么今天就来看看如何使用「栈」的特性来实现一个「队列」,如何用「队列」实现一个「栈」。
### 一、用栈实现队列
-首先,队列的 API 如下:
+力扣第 232 题「用栈实现队列」让我们实现的 API 如下:
```java
class MyQueue {
@@ -49,7 +56,7 @@ class MyQueue {
我们使用两个栈 `s1, s2` 就能实现一个队列的功能(这样放置栈可能更容易理解):
-
+
```java
class MyQueue {
@@ -65,7 +72,7 @@ class MyQueue {
当调用 `push` 让元素入队时,只要把元素压入 `s1` 即可,比如说 `push` 进 3 个元素分别是 1,2,3,那么底层结构就是这样:
-
+
```java
/** 添加元素到队尾 */
@@ -76,7 +83,7 @@ public void push(int x) {
那么如果这时候使用 `peek` 查看队头的元素怎么办呢?按道理队头元素应该是 1,但是在 `s1` 中 1 被压在栈底,现在就要轮到 `s2` 起到一个中转的作用了:当 `s2` 为空时,可以把 `s1` 的所有元素取出再添加进 `s2`,**这时候 `s2` 中元素就是先进先出顺序了**。
-
+
```java
/** 返回队头元素 */
@@ -119,7 +126,9 @@ public boolean empty() {
### 二、用队列实现栈
-如果说双栈实现队列比较巧妙,那么用队列实现栈就比较简单粗暴了,只需要一个队列作为底层数据结构。首先看下栈的 API:
+如果说双栈实现队列比较巧妙,那么用队列实现栈就比较简单粗暴了,只需要一个队列作为底层数据结构。
+
+力扣第 225 题「用队列实现栈」让我们实现如下 API:
```java
class MyStack {
@@ -159,13 +168,13 @@ class MyStack {
}
```
-我们的底层数据结构是先进先出的队列,每次 `pop` 只能从队头取元素;但是栈是后进先出,也就是说 `pop` API 要从队尾取元素。
+我们的底层数据结构是先进先出的队列,每次 `pop` 只能从队头取元素;但是栈是后进先出,也就是说 `pop` API 要从队尾取元素:
-
+
解决方法简单粗暴,把队列前面的都取出来再加入队尾,让之前的队尾元素排到队头,这样就可以取出了:
-
+
```java
/** 删除栈顶的元素并返回 */
@@ -212,7 +221,7 @@ public boolean empty() {
个人认为,用队列实现栈是没啥亮点的问题,但是**用双栈实现队列是值得学习的**。
-
+
从栈 `s1` 搬运元素到 `s2` 之后,元素在 `s2` 中就变成了队列的先进先出顺序,这个特性有点类似「负负得正」,确实不太容易想到。
@@ -220,13 +229,10 @@ public boolean empty() {
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/FloodFill\347\256\227\346\263\225\350\257\246\350\247\243\345\217\212\345\272\224\347\224\250.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/FloodFill\347\256\227\346\263\225\350\257\246\350\247\243\345\217\212\345\272\224\347\224\250.md"
index 9b2322d74318334fa21bf1c1c3aedfc709fb4437..79ee3cd974d03e9211d053dcb3f2e5dc44146093 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/FloodFill\347\256\227\346\263\225\350\257\246\350\247\243\345\217\212\345\272\224\347\224\250.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/FloodFill\347\256\227\346\263\225\350\257\246\350\247\243\345\217\212\345\272\224\347\224\250.md"
@@ -1,34 +1,39 @@
# FloodFill算法详解及应用
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[733.图像渲染](https://leetcode-cn.com/problems/flood-fill)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [733. Flood Fill](https://leetcode.com/problems/flood-fill/) | [733. 图像渲染](https://leetcode.cn/problems/flood-fill/) | 🟢
**-----------**
啥是 FloodFill 算法呢,最直接的一个应用就是「颜色填充」,就是 Windows 绘画本中那个小油漆桶的标志,可以把一块被圈起来的区域全部染色。
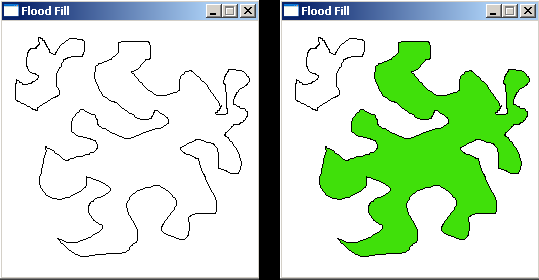
-
+
这种算法思想还在许多其他地方有应用。比如说扫雷游戏,有时候你点一个方格,会一下子展开一片区域,这个展开过程,就是 FloodFill 算法实现的。
-
+
类似的,像消消乐这类游戏,相同方块积累到一定数量,就全部消除,也是 FloodFill 算法的功劳。
-
+
通过以上的几个例子,你应该对 FloodFill 算法有个概念了,现在我们要抽象问题,提取共同点。
@@ -52,7 +57,7 @@ void fill(int x, int y) {
下面看一道 LeetCode 题目,其实就是让我们来实现一个「颜色填充」功能。
-
+
根据上篇文章,我们讲了「树」算法设计的一个总路线,今天就可以用到:
@@ -89,11 +94,11 @@ boolean inArea(int[][] image, int x, int y) {
### 二、研究细节
-为什么会陷入无限递归呢,很好理解,因为每个坐标都要搜索上下左右,那么对于一个坐标,一定会被上下左右的坐标搜索。**被重复搜索时,必须保证递归函数能够能正确地退出,否则就会陷入死循环。**
+为什么会陷入无限递归呢,很好理解,因为每个坐标都要搜索上下左右,那么对于一个坐标,一定会被上下左右的坐标搜索。**被重复搜索时,必须保证递归函数能够能正确地退出,否则就会陷入死循环**。
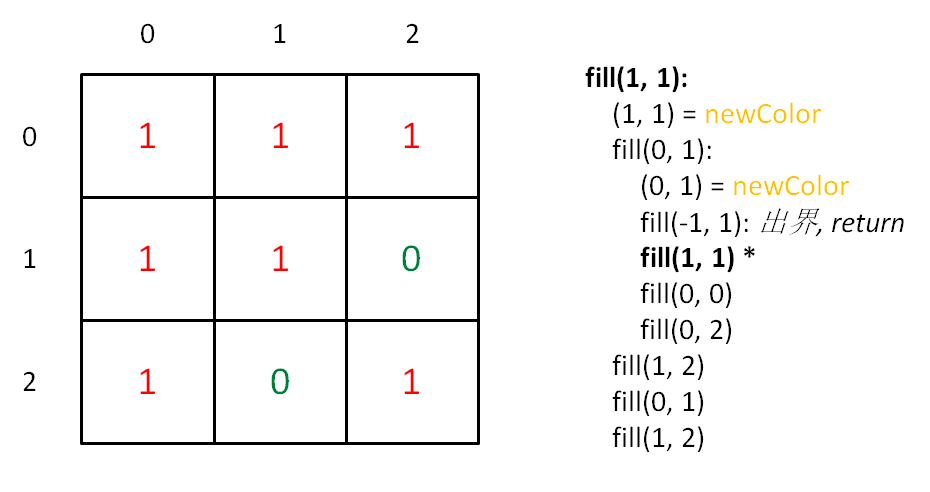
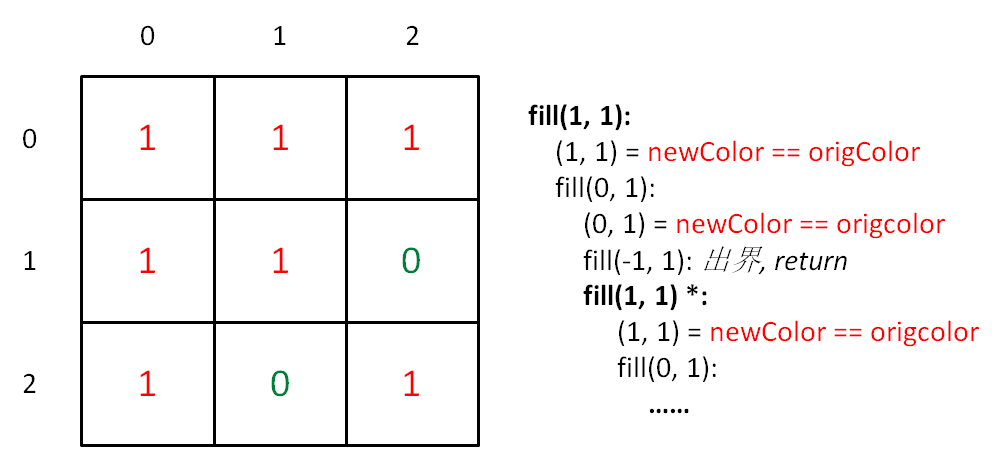
为什么 newColor 和 origColor 不同时可以正常退出呢?把算法流程画个图理解一下:
-
+
可以看到,fill(1, 1) 被重复搜索了,我们用 fill(1, 1)* 表示这次重复搜索。fill(1, 1)* 执行时,(1, 1) 已经被换成了 newColor,所以 fill(1, 1)* 会在这个 if 语句被怼回去,正确退出了。
@@ -101,11 +106,11 @@ boolean inArea(int[][] image, int x, int y) {
// 碰壁:遇到其他颜色,超出 origColor 区域
if (image[x][y] != origColor) return;
```
-
+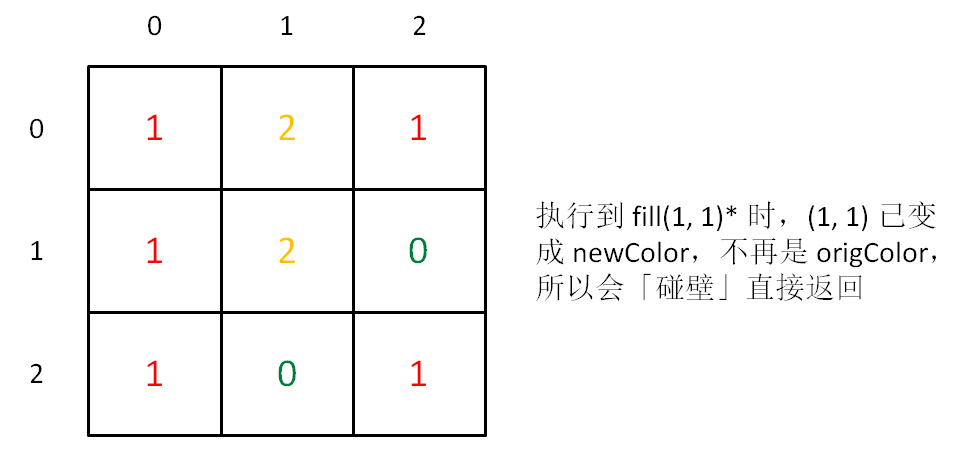
但是,如果说 origColor 和 newColor 一样,这个 if 语句就无法让 fill(1, 1)* 正确退出,而是开启了下面的重复递归,形成了死循环。
-
+
### 三、处理细节
@@ -124,7 +129,7 @@ image[x][y] = newColor;
完全 OK,这也是处理「图」的一种常用手段。不过对于此题,不用开数组,我们有一种更好的方法,那就是回溯算法。
-前文 [回溯算法框架套路](https://labuladong.gitee.io/algo/)讲过,这里不再赘述,直接套回溯算法框架:
+前文 [回溯算法框架套路](https://labuladong.github.io/article/fname.html?fname=回溯算法详解修订版)讲过,这里不再赘述,直接套回溯算法框架:
```java
void fill(int[][] image, int x, int y,
@@ -149,12 +154,11 @@ void fill(int[][] image, int x, int y,
这种解决方法是最常用的,相当于使用一个特殊值 -1 代替 visited 数组的作用,达到不走回头路的效果。为什么是 -1,因为题目中说了颜色取值在 0 - 65535 之间,所以 -1 足够特殊,能和颜色区分开。
-
### 四、拓展延伸:自动魔棒工具和扫雷
大部分图片编辑软件一定有「自动魔棒工具」这个功能:点击一个地方,帮你自动选中相近颜色的部分。如下图,我想选中老鹰,可以先用自动魔棒选中蓝天背景,然后反向选择,就选中了老鹰。我们来分析一下自动魔棒工具的原理。
-
+
显然,这个算法肯定是基于 FloodFill 算法的,但有两点不同:首先,背景色是蓝色,但不能保证都是相同的蓝色,毕竟是像素点,可能存在肉眼无法分辨的深浅差异,而我们希望能够忽略这种细微差异。第二,FloodFill 算法是「区域填充」,这里更像「边界填充」。
@@ -167,7 +171,7 @@ if (Math.abs(image[x][y] - origColor) > threshold)
对于第二个问题,我们首先明确问题:不要把区域内所有 origColor 的都染色,而是只给区域最外圈染色。然后,我们分析,如何才能仅给外围染色,即如何才能找到最外围坐标,最外围坐标有什么特点?
-
+
可以发现,区域边界上的坐标,至少有一个方向不是 origColor,而区域内部的坐标,四面都是 origColor,这就是解决问题的关键。保持框架不变,使用 visited 数组记录已搜索坐标,主要代码如下:
@@ -223,19 +227,16 @@ int fill(int[][] image, int x, int y,
同理,思考扫雷游戏,应用 FloodFill 算法展开空白区域的同时,也需要计算并显示边界上雷的个数,如何实现的?其实也是相同的思路,遇到雷就返回 true,这样 surround 变量存储的就是雷的个数。当然,扫雷的 FloodFill 算法不能只检查上下左右,还得加上四个斜向。
-
+
以上详细讲解了 FloodFill 算法的框架设计,**二维矩阵中的搜索问题,都逃不出这个算法框架**。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/UnionFind\347\256\227\346\263\225\350\257\246\350\247\243.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/UnionFind\347\256\227\346\263\225\350\257\246\350\247\243.md"
index c6a1878510fae4e6214723c73325647d4e0c1aa9..92e21743d0d209c2bece51ccd7c919f27b74116c 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/UnionFind\347\256\227\346\263\225\350\257\246\350\247\243.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/UnionFind\347\256\227\346\263\225\350\257\246\350\247\243.md"
@@ -1,22 +1,37 @@
-# Union-Find算法详解
+# Union-Find 算法详解
+
+
+
+
-
-
+
+
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
+
+
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [130. Surrounded Regions](https://leetcode.com/problems/surrounded-regions/) | [130. 被围绕的区域](https://leetcode.cn/problems/surrounded-regions/) | 🟠
+| [323. Number of Connected Components in an Undirected Graph](https://leetcode.com/problems/number-of-connected-components-in-an-undirected-graph/)🔒 | [323. 无向图中连通分量的数目](https://leetcode.cn/problems/number-of-connected-components-in-an-undirected-graph/)🔒 | 🟠
+| [990. Satisfiability of Equality Equations](https://leetcode.com/problems/satisfiability-of-equality-equations/) | [990. 等式方程的可满足性](https://leetcode.cn/problems/satisfiability-of-equality-equations/) | 🟠
**-----------**
-今天讲讲 Union-Find 算法,也就是常说的并查集算法,主要是解决图论中「动态连通性」问题的。名词很高端,其实特别好理解,等会解释,另外这个算法的应用都非常有趣。
+今天讲讲 Union-Find 算法,也就是常说的并查集(Disjoint Set)结构,主要是解决图论中「动态连通性」问题的。名词很高端,其实特别好理解,等会解释,另外这个算法的应用都非常有趣。
-说起这个 Union-Find,应该算是我的「启蒙算法」了,因为《算法4》的开头就介绍了这款算法,可是把我秀翻了,感觉好精妙啊!后来刷了 LeetCode,并查集相关的算法题目都非常有意思,而且《算法4》给的解法竟然还可以进一步优化,只要加一个微小的修改就可以把时间复杂度降到 O(1)。
+说起这个 Union-Find,应该算是我的「启蒙算法」了,因为《算法4》的开头就介绍了这款算法,可是把我秀翻了,感觉好精妙啊!
+
+后来刷了 LeetCode,并查集相关的算法题目都非常有意思,而且《算法4》给的解法竟然还可以进一步优化,只要加一个微小的修改就可以把时间复杂度降到 O(1)。
废话不多说,直接上干货,先解释一下什么叫动态连通性吧。
@@ -24,7 +39,7 @@
简单说,动态连通性其实可以抽象成给一幅图连线。比如下面这幅图,总共有 10 个节点,他们互不相连,分别用 0~9 标记:
-
+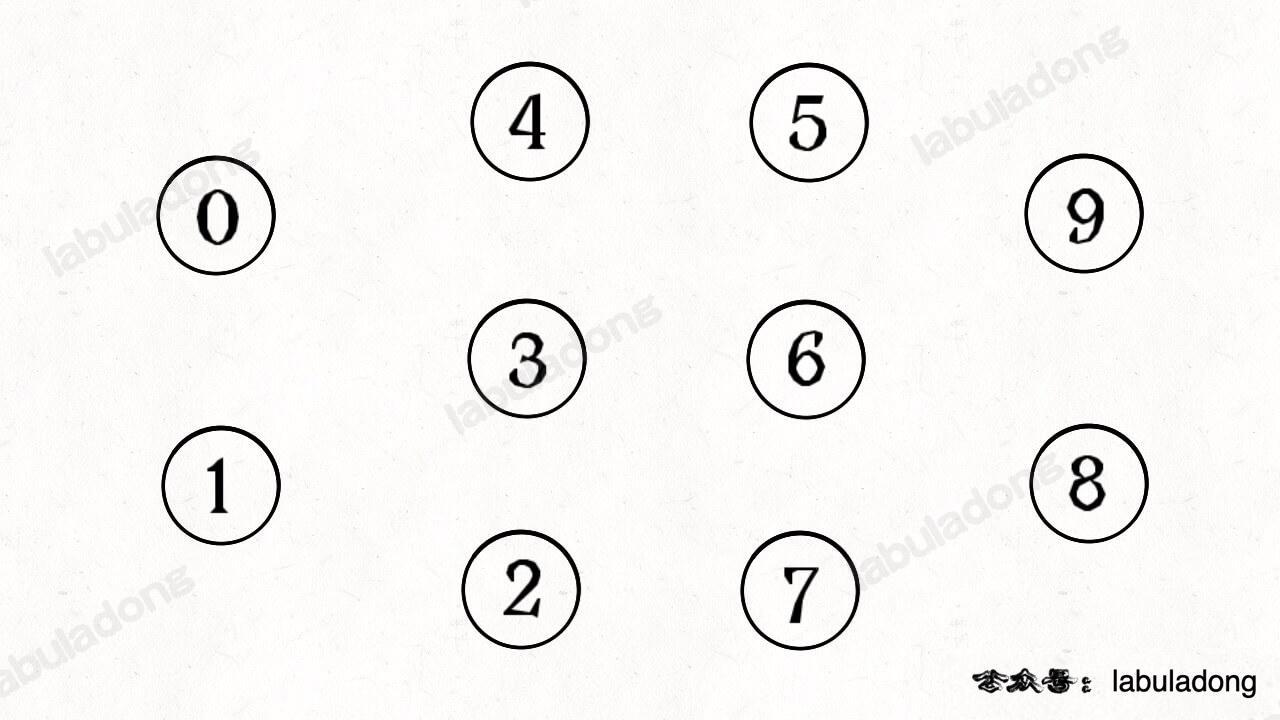
现在我们的 Union-Find 算法主要需要实现这两个 API:
@@ -41,23 +56,23 @@ class UF {
这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
-1、自反性:节点`p`和`p`是连通的。
+1、自反性:节点 `p` 和 `p` 是连通的。
-2、对称性:如果节点`p`和`q`连通,那么`q`和`p`也连通。
+2、对称性:如果节点 `p` 和 `q` 连通,那么 `q` 和 `p` 也连通。
-3、传递性:如果节点`p`和`q`连通,`q`和`r`连通,那么`p`和`r`也连通。
+3、传递性:如果节点 `p` 和 `q` 连通,`q` 和 `r` 连通,那么 `p` 和 `r` 也连通。
-比如说之前那幅图,0~9 任意两个**不同**的点都不连通,调用`connected`都会返回 false,连通分量为 10 个。
+比如说之前那幅图,0~9 任意两个**不同**的点都不连通,调用 `connected` 都会返回 false,连通分量为 10 个。
-如果现在调用`union(0, 1)`,那么 0 和 1 被连通,连通分量降为 9 个。
+如果现在调用 `union(0, 1)`,那么 0 和 1 被连通,连通分量降为 9 个。
-再调用`union(1, 2)`,这时 0,1,2 都被连通,调用`connected(0, 2)`也会返回 true,连通分量变为 8 个。
+再调用 `union(1, 2)`,这时 0,1,2 都被连通,调用 `connected(0, 2)` 也会返回 true,连通分量变为 8 个。
-
+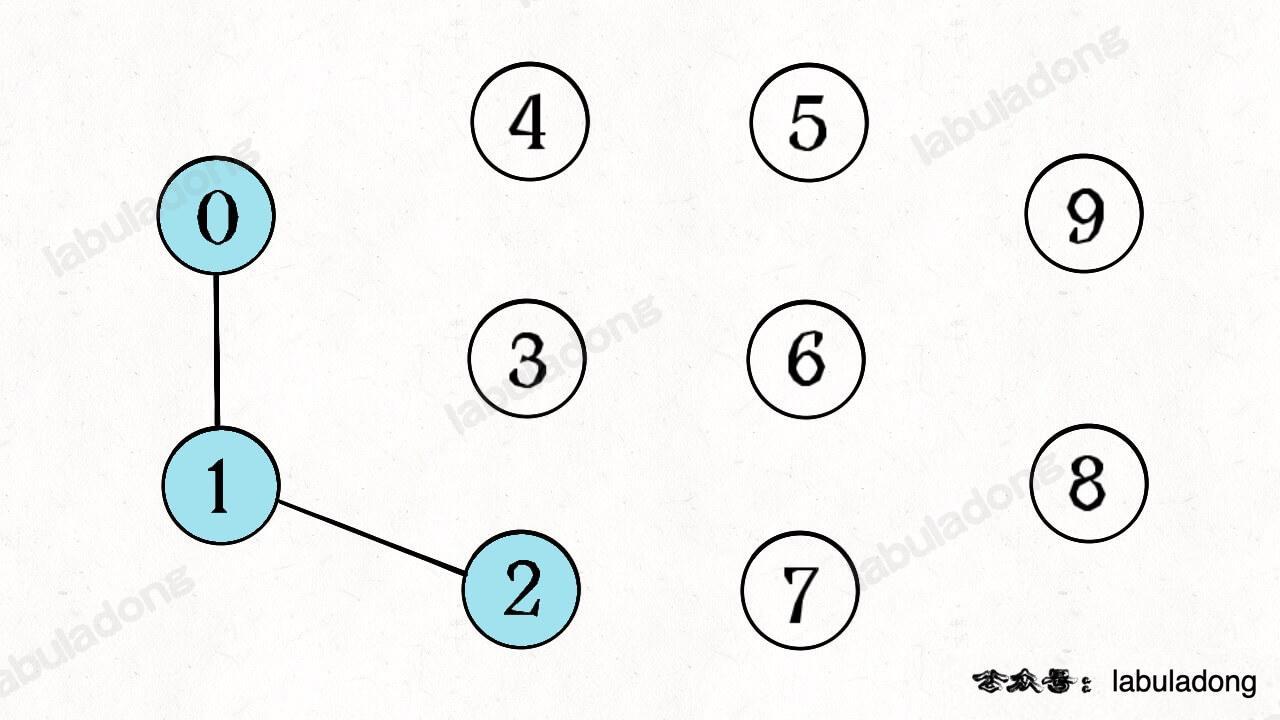
判断这种「等价关系」非常实用,比如说编译器判断同一个变量的不同引用,比如社交网络中的朋友圈计算等等。
-这样,你应该大概明白什么是动态连通性了,Union-Find 算法的关键就在于`union`和`connected`函数的效率。那么用什么模型来表示这幅图的连通状态呢?用什么数据结构来实现代码呢?
+这样,你应该大概明白什么是动态连通性了,Union-Find 算法的关键就在于 `union` 和 `connected` 函数的效率。那么用什么模型来表示这幅图的连通状态呢?用什么数据结构来实现代码呢?
### 二、基本思路
@@ -65,13 +80,13 @@ class UF {
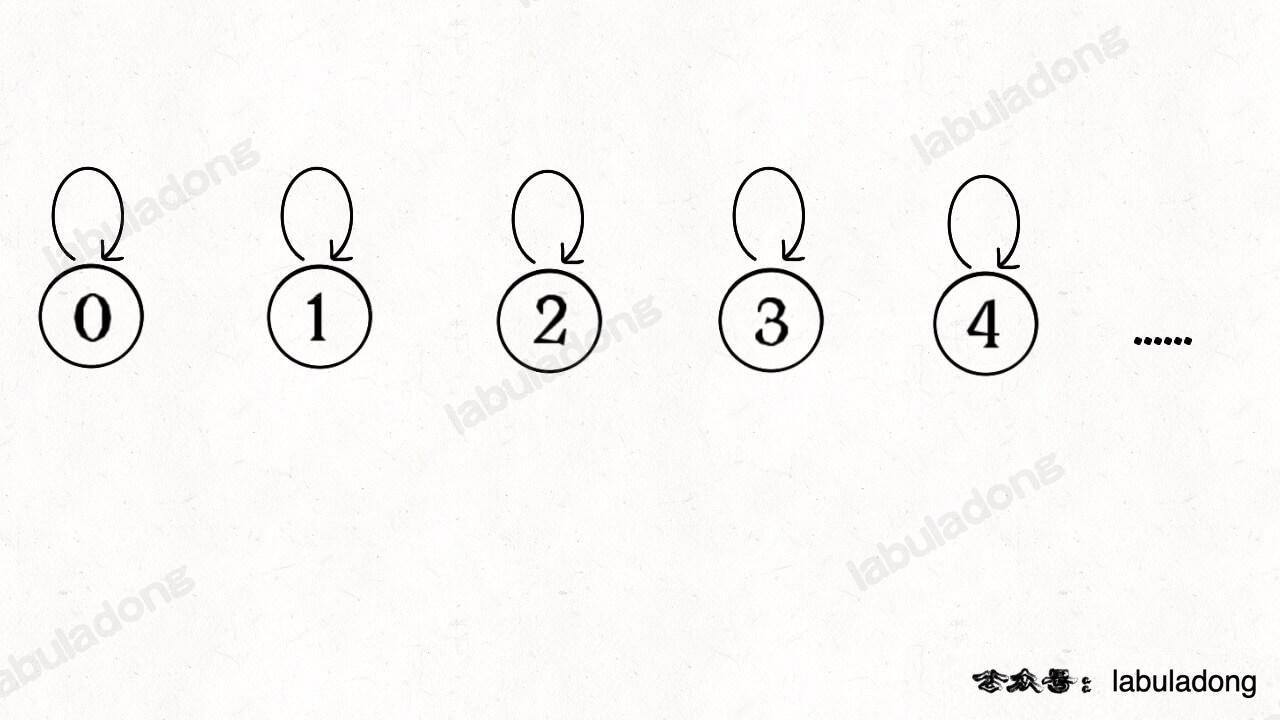
怎么用森林来表示连通性呢?我们设定树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。比如说刚才那幅 10 个节点的图,一开始的时候没有相互连通,就是这样:
-
+
```java
class UF {
// 记录连通分量
private int count;
- // 节点 x 的节点是 parent[x]
+ // 节点 x 的父节点是 parent[x]
private int[] parent;
/* 构造函数,n 为图的节点总数 */
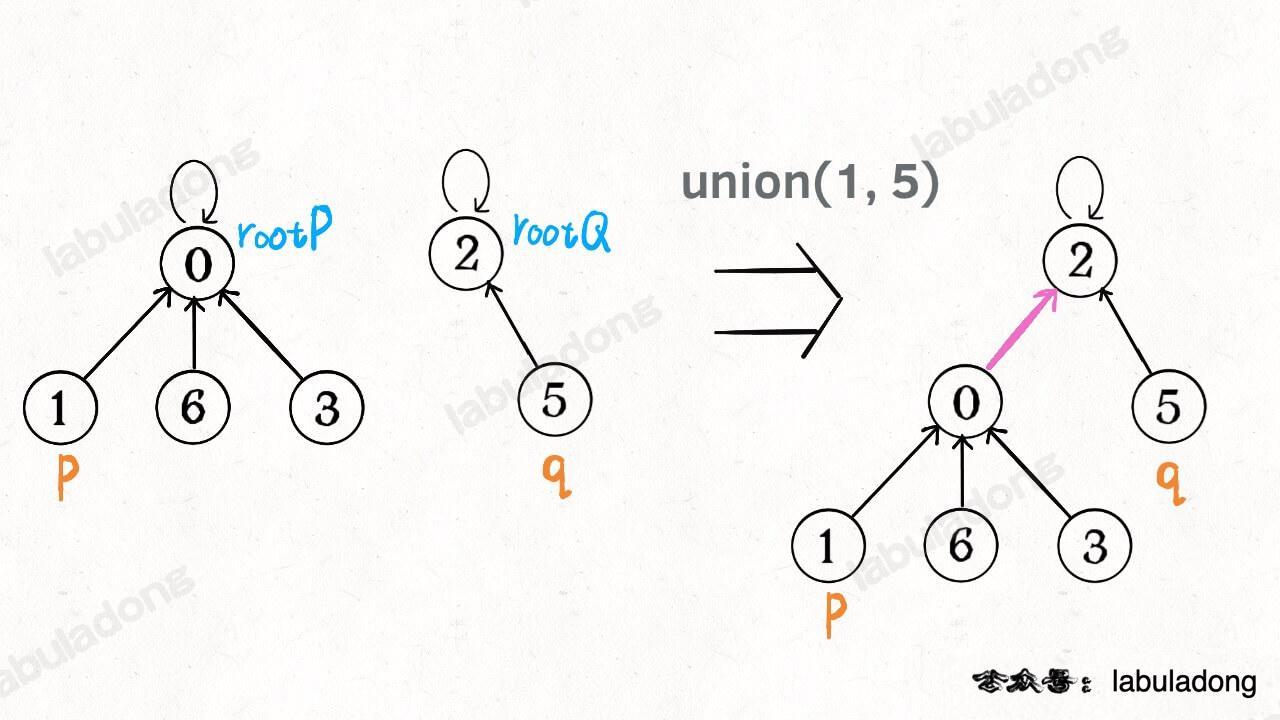
@@ -90,7 +105,7 @@ class UF {
**如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上**:
-
+
```java
public void union(int p, int q) {
@@ -118,9 +133,9 @@ public int count() {
}
```
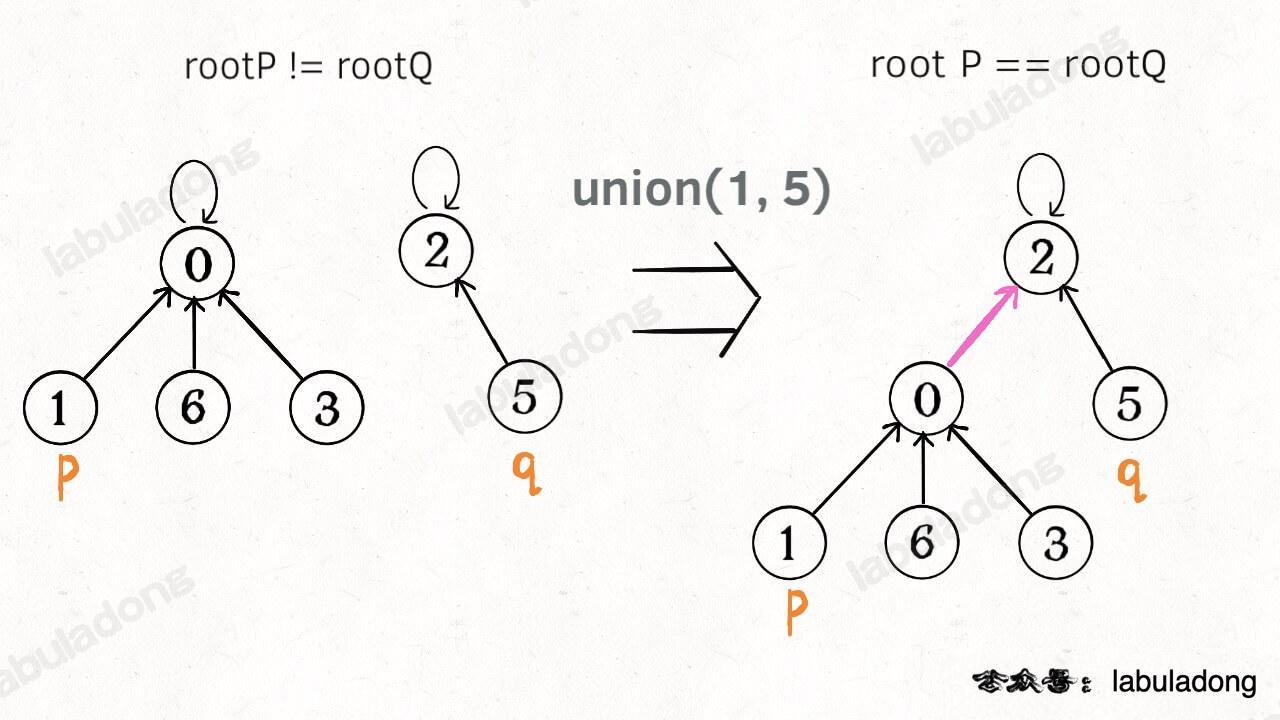
-**这样,如果节点`p`和`q`连通的话,它们一定拥有相同的根节点**:
+**这样,如果节点 `p` 和 `q` 连通的话,它们一定拥有相同的根节点**:
-
+
```java
public boolean connected(int p, int q) {
@@ -132,19 +147,19 @@ public boolean connected(int p, int q) {
至此,Union-Find 算法就基本完成了。是不是很神奇?竟然可以这样使用数组来模拟出一个森林,如此巧妙的解决这个比较复杂的问题!
-那么这个算法的复杂度是多少呢?我们发现,主要 API`connected`和`union`中的复杂度都是`find`函数造成的,所以说它们的复杂度和`find`一样。
+那么这个算法的复杂度是多少呢?我们发现,主要 API `connected` 和 `union` 中的复杂度都是 `find` 函数造成的,所以说它们的复杂度和 `find` 一样。
-`find`主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是`logN`,但这并不一定。`logN`的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成`N`。
+`find` 主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是 `logN`,但这并不一定。`logN` 的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成 `N`。
-
+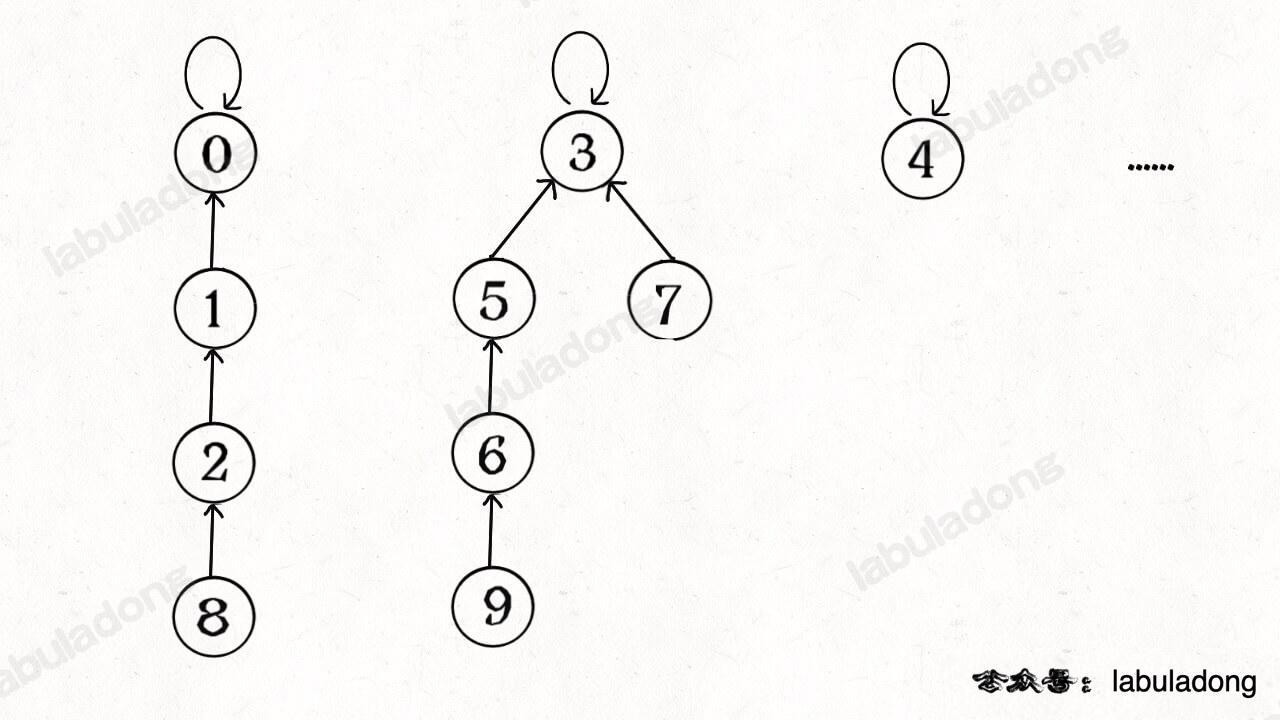
-所以说上面这种解法,`find`,`union`,`connected`的时间复杂度都是 O(N)。这个复杂度很不理想的,你想图论解决的都是诸如社交网络这样数据规模巨大的问题,对于`union`和`connected`的调用非常频繁,每次调用需要线性时间完全不可忍受。
+所以说上面这种解法,`find` , `union` , `connected` 的时间复杂度都是 O(N)。这个复杂度很不理想的,你想图论解决的都是诸如社交网络这样数据规模巨大的问题,对于 `union` 和 `connected` 的调用非常频繁,每次调用需要线性时间完全不可忍受。
**问题的关键在于,如何想办法避免树的不平衡呢**?只需要略施小计即可。
### 三、平衡性优化
-我们要知道哪种情况下可能出现不平衡现象,关键在于`union`过程:
+我们要知道哪种情况下可能出现不平衡现象,关键在于 `union` 过程:
```java
public void union(int p, int q) {
@@ -155,14 +170,14 @@ public void union(int p, int q) {
// 将两棵树合并为一棵
parent[rootP] = rootQ;
// parent[rootQ] = rootP 也可以
- count--;
+ count--;
```
-我们一开始就是简单粗暴的把`p`所在的树接到`q`所在的树的根节点下面,那么这里就可能出现「头重脚轻」的不平衡状况,比如下面这种局面:
+我们一开始就是简单粗暴的把 `p` 所在的树接到 `q` 所在的树的根节点下面,那么这里就可能出现「头重脚轻」的不平衡状况,比如下面这种局面:
-
+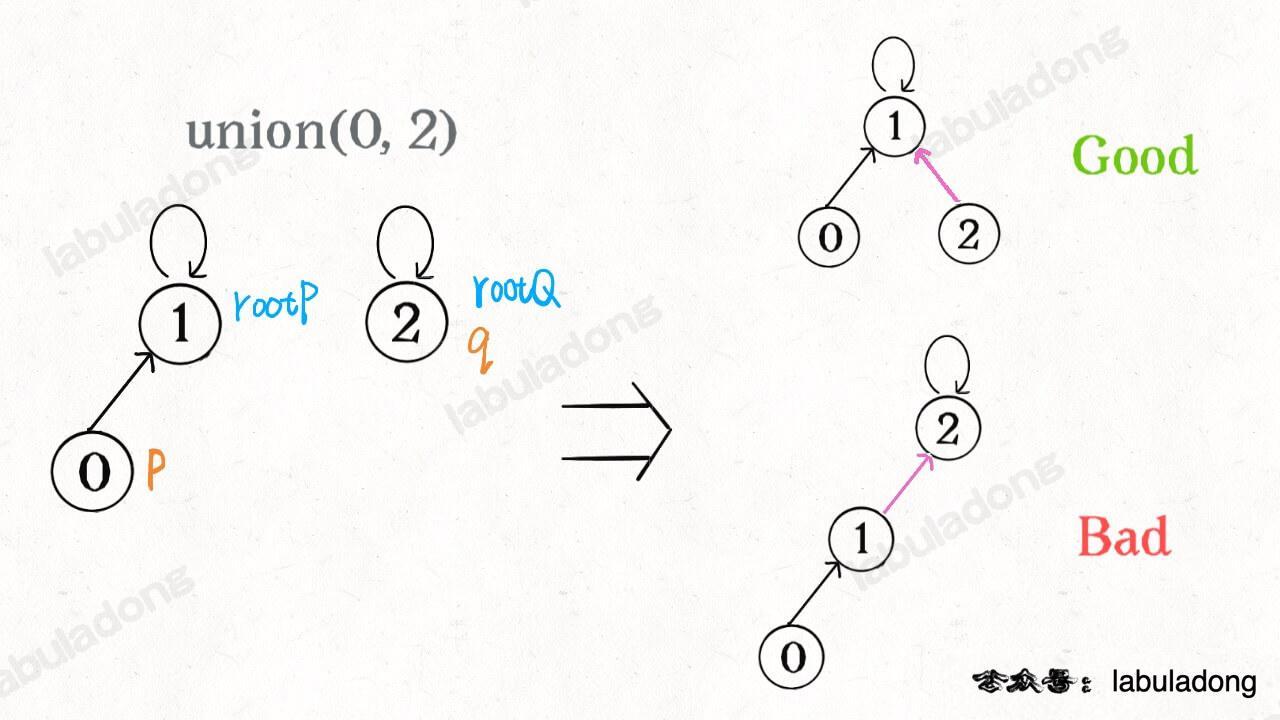
-长此以往,树可能生长得很不平衡。**我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些**。解决方法是额外使用一个`size`数组,记录每棵树包含的节点数,我们不妨称为「重量」:
+长此以往,树可能生长得很不平衡。**我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些**。解决方法是额外使用一个 `size` 数组,记录每棵树包含的节点数,我们不妨称为「重量」:
```java
class UF {
@@ -186,7 +201,7 @@ class UF {
}
```
-比如说`size[3] = 5`表示,以节点`3`为根的那棵树,总共有`5`个节点。这样我们可以修改一下`union`方法:
+比如说 `size[3] = 5` 表示,以节点 `3` 为根的那棵树,总共有 `5` 个节点。这样我们可以修改一下 `union` 方法:
```java
public void union(int p, int q) {
@@ -207,24 +222,30 @@ public void union(int p, int q) {
}
```
-这样,通过比较树的重量,就可以保证树的生长相对平衡,树的高度大致在`logN`这个数量级,极大提升执行效率。
+这样,通过比较树的重量,就可以保证树的生长相对平衡,树的高度大致在 `logN` 这个数量级,极大提升执行效率。
-此时,`find`,`union`,`connected`的时间复杂度都下降为 O(logN),即便数据规模上亿,所需时间也非常少。
+此时,`find` , `union` , `connected` 的时间复杂度都下降为 O(logN),即便数据规模上亿,所需时间也非常少。
### 四、路径压缩
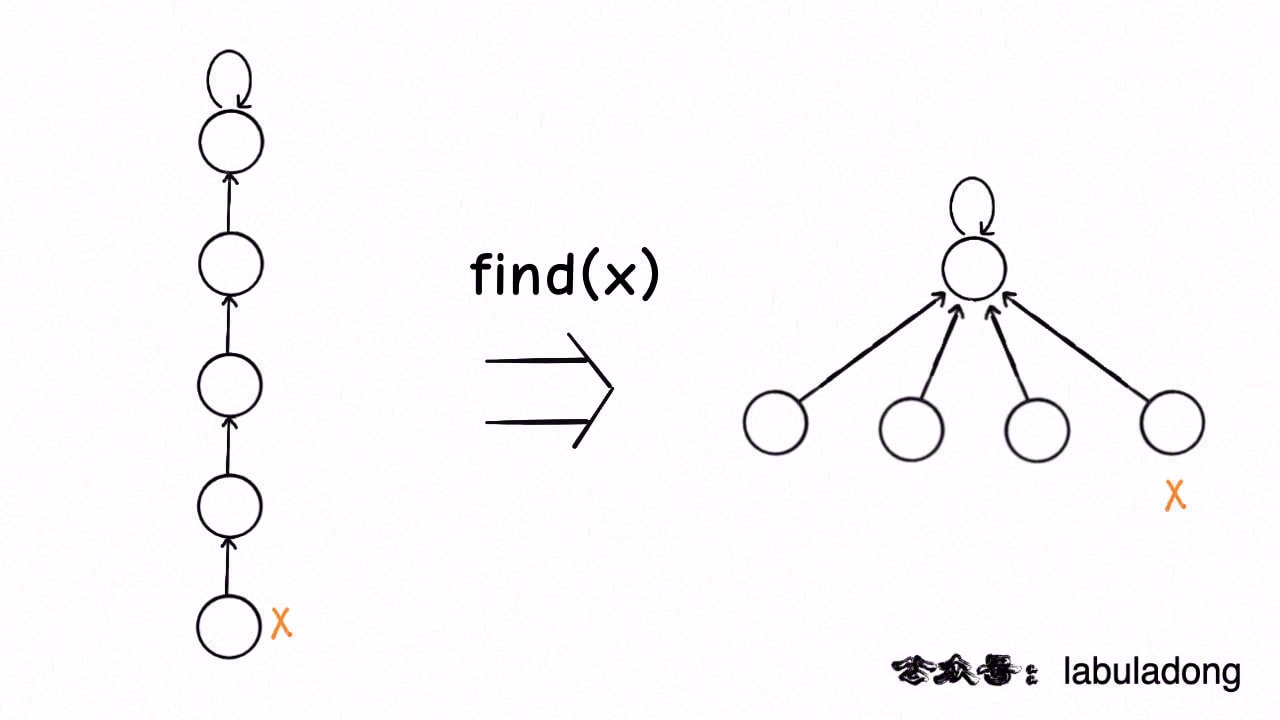
-这步优化特别简单,所以非常巧妙。我们能不能进一步压缩每棵树的高度,使树高始终保持为常数?
+这步优化虽然代码很简单,但原理非常巧妙。
+
+**其实我们并不在乎每棵树的结构长什么样,只在乎根节点**。
+
+因为无论树长啥样,树上的每个节点的根节点都是相同的,所以能不能进一步压缩每棵树的高度,使树高始终保持为常数?
-
+
-这样`find`就能以 O(1) 的时间找到某一节点的根节点,相应的,`connected`和`union`复杂度都下降为 O(1)。
+这样每个节点的父节点就是整棵树的根节点,`find` 就能以 O(1) 的时间找到某一节点的根节点,相应的,`connected` 和 `union` 复杂度都下降为 O(1)。
-要做到这一点,非常简单,只需要在`find`中加一行代码:
+要做到这一点主要是修改 `find` 函数逻辑,非常简单,但你可能会看到两种不同的写法。
+
+第一种是在 `find` 中加一行代码:
```java
private int find(int x) {
while (parent[x] != x) {
- // 进行路径压缩
+ // 这行代码进行路径压缩
parent[x] = parent[parent[x]];
x = parent[x];
}
@@ -234,86 +255,284 @@ private int find(int x) {
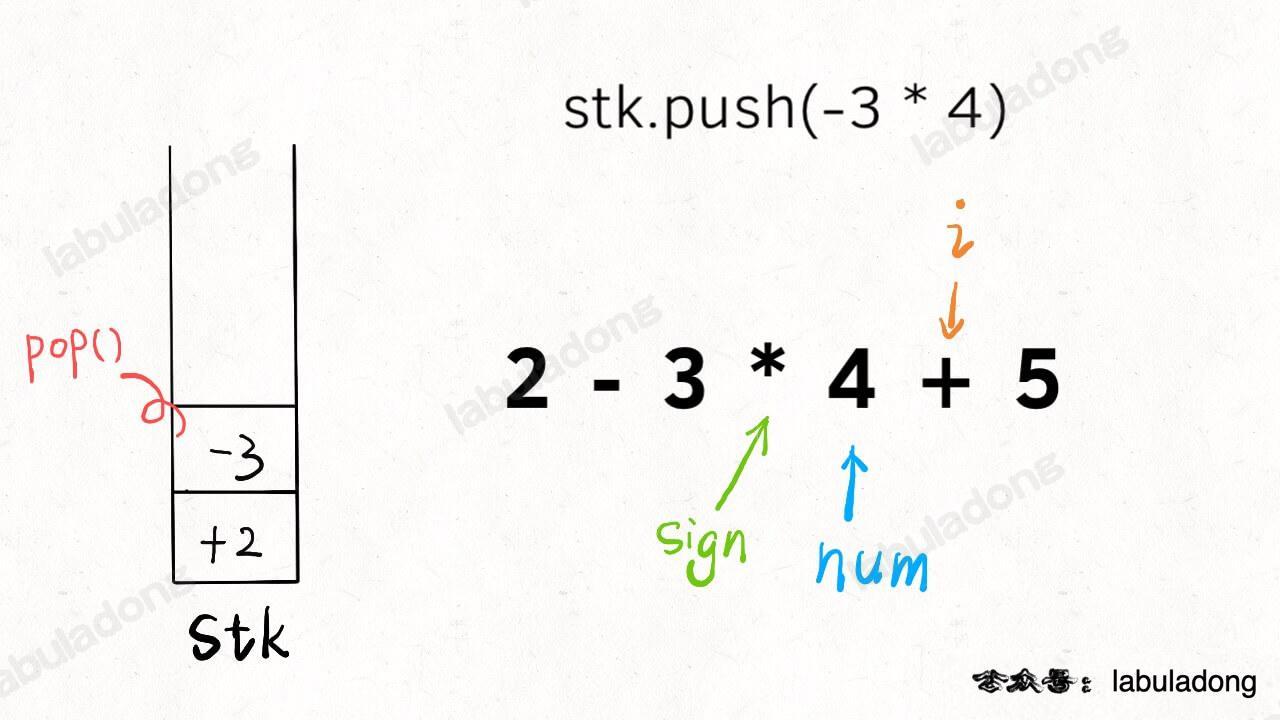
这个操作有点匪夷所思,看个 GIF 就明白它的作用了(为清晰起见,这棵树比较极端):
-
+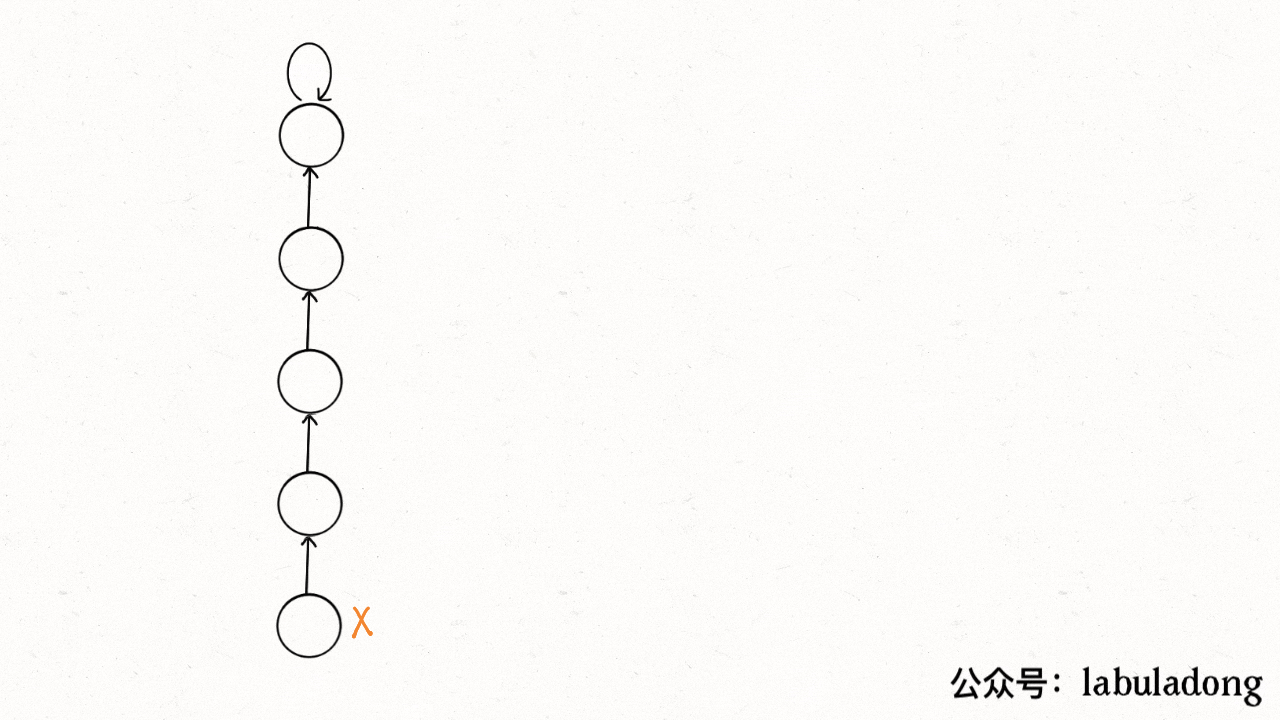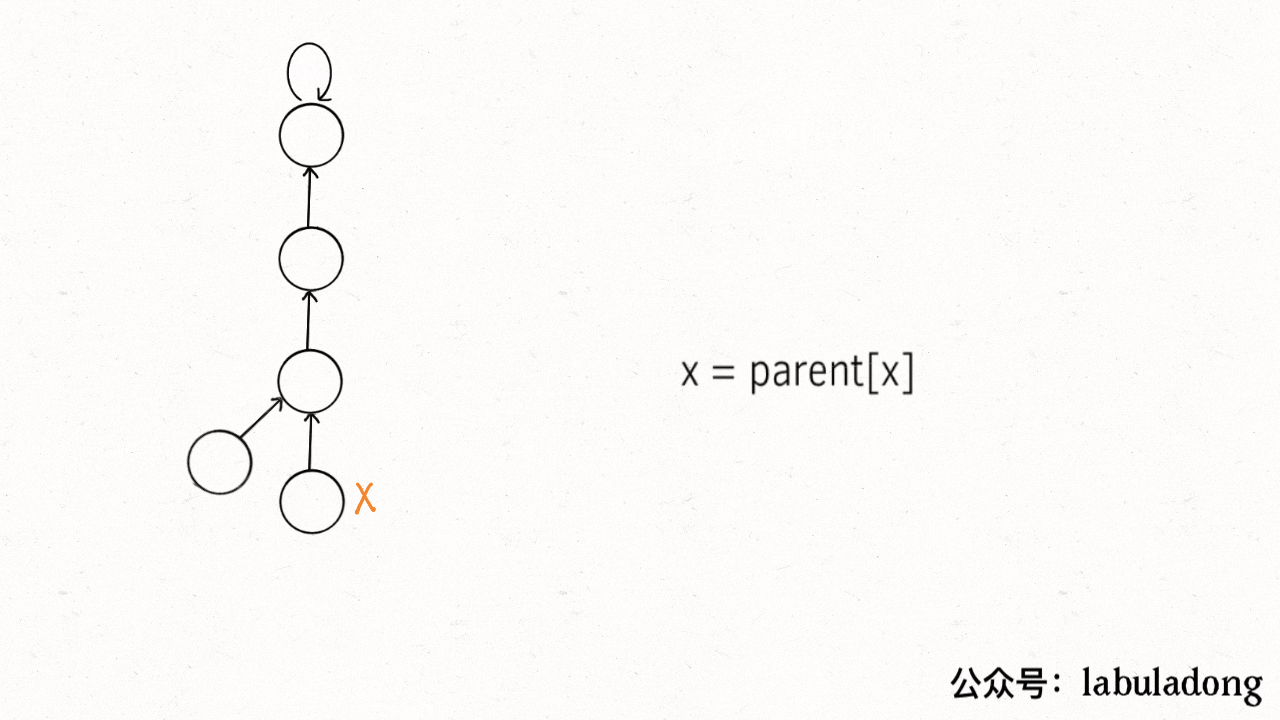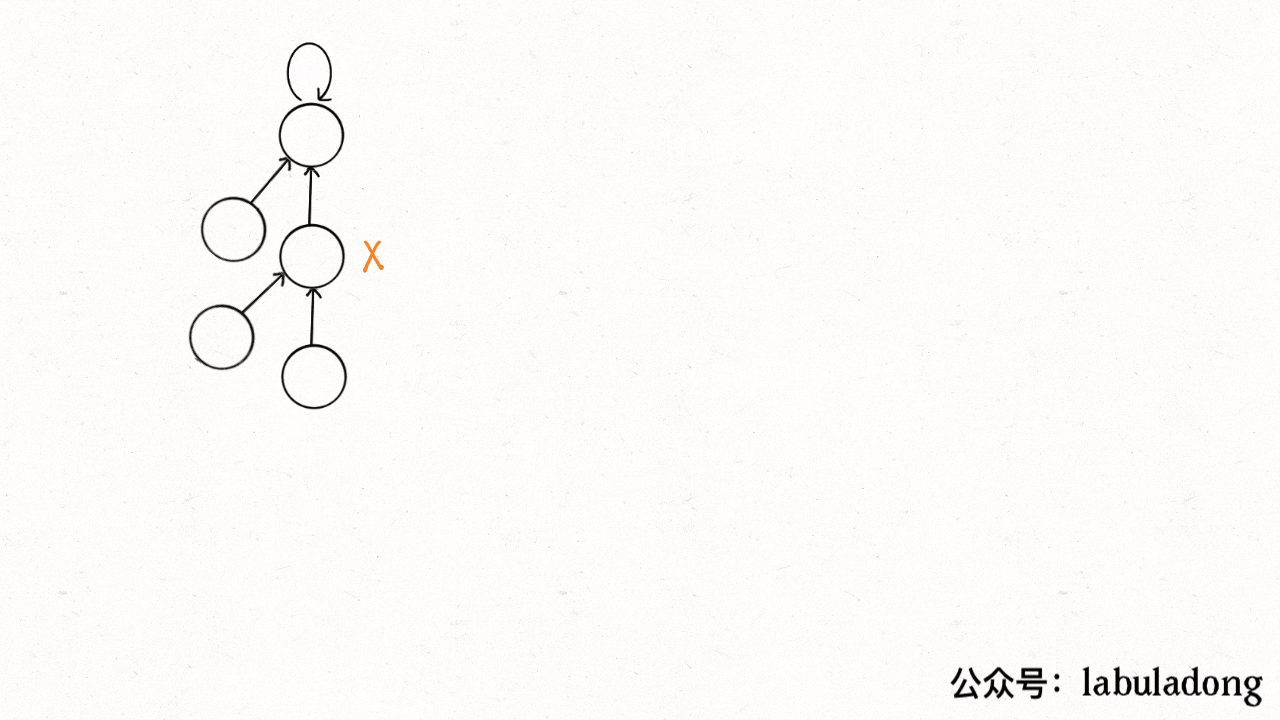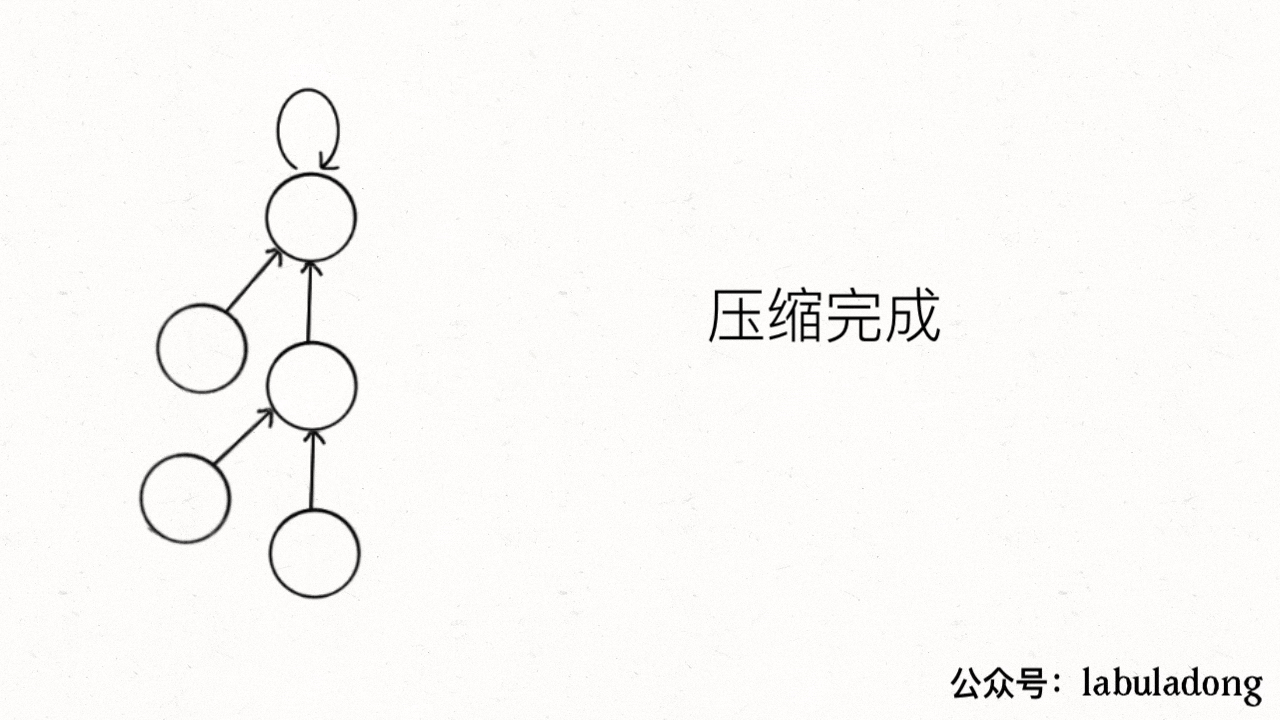
+
+用语言描述就是,每次 while 循环都会把一对儿父子节点改到同一层,这样每次调用 `find` 函数向树根遍历的同时,顺手就将树高缩短了。
+
+路径压缩的第二种写法是这样:
+
+```java
+// 第二种路径压缩的 find 方法
+public int find(int x) {
+ if (parent[x] != x) {
+ parent[x] = find(parent[x]);
+ }
+ return parent[x];
+}
+```
+
+我一度认为这种递归写法和第一种迭代写法做的事情一样,但实际上是我大意了,有读者指出这种写法进行路径压缩的效率是高于上一种解法的。
+
+这个递归过程有点不好理解,你可以自己手画一下递归过程。我把这个函数做的事情翻译成迭代形式,方便你理解它进行路径压缩的原理:
+
+```java
+// 这段迭代代码方便你理解递归代码所做的事情
+public int find(int x) {
+ // 先找到根节点
+ int root = x;
+ while (parent[root] != root) {
+ root = parent[root];
+ }
+ // 然后把 x 到根节点之间的所有节点直接接到根节点下面
+ int old_parent = parent[x];
+ while (x != root) {
+ parent[x] = root;
+ x = old_parent;
+ old_parent = parent[old_parent];
+ }
+ return root;
+}
+```
-可见,调用`find`函数每次向树根遍历的同时,顺手将树高缩短了,最终所有树高都不会超过 3(`union`的时候树高可能达到 3)。
+这种路径压缩的效果如下:
-PS:读者可能会问,这个 GIF 图的find过程完成之后,树高恰好等于 3 了,但是如果更高的树,压缩后高度依然会大于 3 呀?不能这么想。这个 GIF 的情景是我编出来方便大家理解路径压缩的,但是实际中,每次find都会进行路径压缩,所以树本来就不可能增长到这么高,你的这种担心应该是多余的。
+
-### 五、最后总结
+比起第一种路径压缩,显然这种方法压缩得更彻底,直接把一整条树枝压平,一点意外都没有。就算一些极端情况下产生了一棵比较高的树,只要一次路径压缩就能大幅降低树高,从 [摊还分析](https://labuladong.github.io/article/fname.html?fname=时间复杂度) 的角度来看,所有操作的平均时间复杂度依然是 O(1),所以从效率的角度来说,推荐你使用这种路径压缩算法。
-我们先来看一下完整代码:
+**另外,如果使用路径压缩技巧,那么 `size` 数组的平衡优化就不是特别必要了**。所以你一般看到的 Union Find 算法应该是如下实现:
```java
class UF {
// 连通分量个数
private int count;
- // 存储一棵树
+ // 存储每个节点的父节点
private int[] parent;
- // 记录树的“重量”
- private int[] size;
+ // n 为图中节点的个数
public UF(int n) {
this.count = n;
parent = new int[n];
- size = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
- size[i] = 1;
}
}
+ // 将节点 p 和节点 q 连通
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
+
if (rootP == rootQ)
return;
- // 小树接到大树下面,较平衡
- if (size[rootP] > size[rootQ]) {
- parent[rootQ] = rootP;
- size[rootP] += size[rootQ];
- } else {
- parent[rootP] = rootQ;
- size[rootQ] += size[rootP];
- }
+ parent[rootQ] = rootP;
+ // 两个连通分量合并成一个连通分量
count--;
}
+ // 判断节点 p 和节点 q 是否连通
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
- private int find(int x) {
- while (parent[x] != x) {
- // 进行路径压缩
- parent[x] = parent[parent[x]];
- x = parent[x];
+ public int find(int x) {
+ if (parent[x] != x) {
+ parent[x] = find(parent[x]);
}
- return x;
+ return parent[x];
}
+ // 返回图中的连通分量个数
public int count() {
return count;
}
}
```
-Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点`union`、判断两个节点的连通性`connected`、计算连通分量`count`所需的时间复杂度均为 O(1)。
+Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点 `union`、判断两个节点的连通性 `connected`、计算连通分量 `count` 所需的时间复杂度均为 O(1)。
+
+到这里,相信你已经掌握了 Union-Find 算法的核心逻辑,总结一下我们优化算法的过程:
+
+1、用 `parent` 数组记录每个节点的父节点,相当于指向父节点的指针,所以 `parent` 数组内实际存储着一个森林(若干棵多叉树)。
+
+2、用 `size` 数组记录着每棵树的重量,目的是让 `union` 后树依然拥有平衡性,保证各个 API 时间复杂度为 O(logN),而不会退化成链表影响操作效率。
+
+3、在 `find` 函数中进行路径压缩,保证任意树的高度保持在常数,使得各个 API 时间复杂度为 O(1)。使用了路径压缩之后,可以不使用 `size` 数组的平衡优化。
+
+下面我们看一些具体的并查集题目。
+
+### 题目实践
+
+力扣第 323 题「无向图中连通分量的数目」就是最基本的连通分量题目:
+
+给你输入一个包含 `n` 个节点的图,用一个整数 `n` 和一个数组 `edges` 表示,其中 `edges[i] = [ai, bi]` 表示图中节点 `ai` 和 `bi` 之间有一条边。请你计算这幅图的连通分量个数。
+
+函数签名如下:
+
+```java
+int countComponents(int n, int[][] edges)
+```
+
+这道题我们可以直接套用 `UF` 类来解决:
+
+```java
+public int countComponents(int n, int[][] edges) {
+ UF uf = new UF(n);
+ // 将每个节点进行连通
+ for (int[] e : edges) {
+ uf.union(e[0], e[1]);
+ }
+ // 返回连通分量的个数
+ return uf.count();
+}
+
+class UF {
+ // 见上文
+}
+```
+
+**另外,一些使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决**。
+
+比如力扣第 130 题「被围绕的区域」:
+
+给你一个 M×N 的二维矩阵,其中包含字符 `X` 和 `O`,让你找到矩阵中**四面**被 `X` 围住的 `O`,并且把它们替换成 `X`。
+
+```java
+void solve(char[][] board);
+```
+
+注意哦,必须是四面被围的 `O` 才能被换成 `X`,也就是说边角上的 `O` 一定不会被围,进一步,与边角上的 `O` 相连的 `O` 也不会被 `X` 围四面,也不会被替换。
+
+
+
+> PS:这让我想起小时候玩的棋类游戏「黑白棋」,只要你用两个棋子把对方的棋子夹在中间,对方的子就被替换成你的子。可见,占据四角的棋子是无敌的,与其相连的边棋子也是无敌的(无法被夹掉)。
+
+其实这个问题应该归为 [岛屿系列问题](https://labuladong.github.io/article/fname.html?fname=岛屿题目) 使用 DFS 算法解决:
+
+先用 for 循环遍历棋盘的**四边**,用 DFS 算法把那些与边界相连的 `O` 换成一个特殊字符,比如 `#`;然后再遍历整个棋盘,把剩下的 `O` 换成 `X`,把 `#` 恢复成 `O`。这样就能完成题目的要求,时间复杂度 O(MN)。
+
+但这个问题也可以用 Union-Find 算法解决,虽然实现复杂一些,甚至效率也略低,但这是使用 Union-Find 算法的通用思想,值得一学。
+
+**你可以把那些不需要被替换的 `O` 看成一个拥有独门绝技的门派,它们有一个共同「祖师爷」叫 `dummy`,这些 `O` 和 `dummy` 互相连通,而那些需要被替换的 `O` 与 `dummy` 不连通**。
+
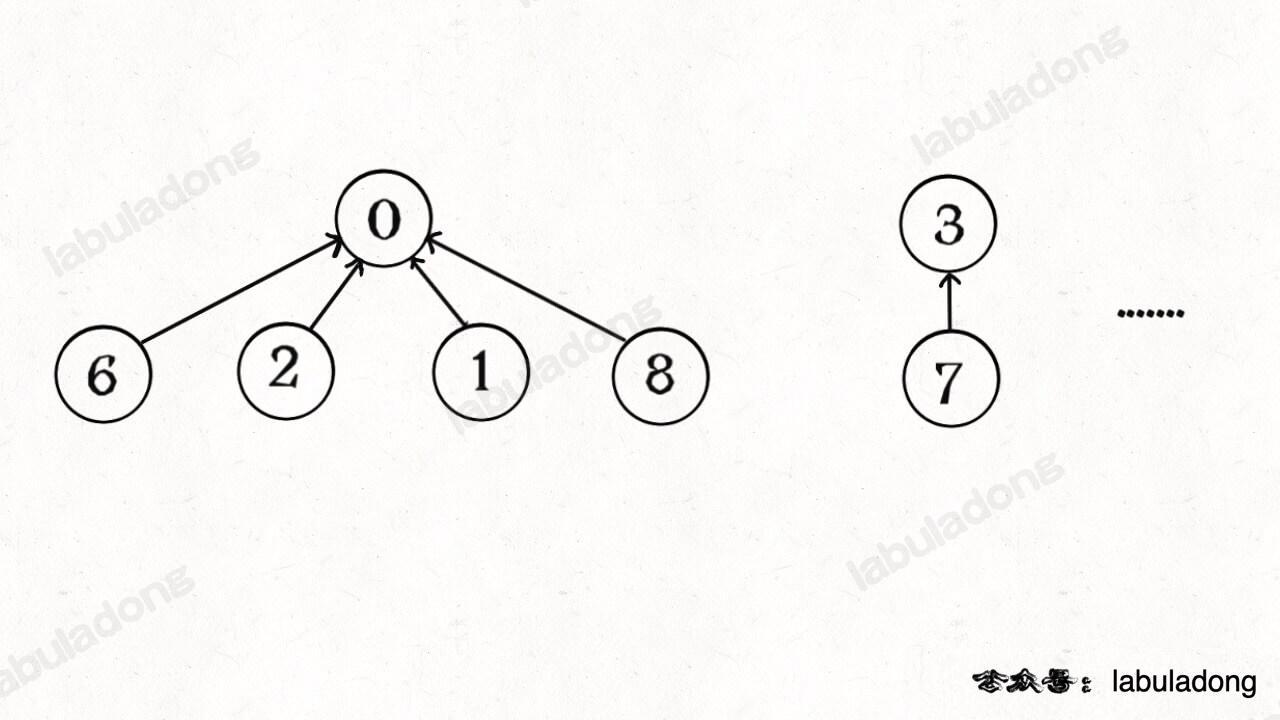
+
+
+这就是 Union-Find 的核心思路,明白这个图,就很容易看懂代码了。
+
+首先要解决的是,根据我们的实现,Union-Find 底层用的是一维数组,构造函数需要传入这个数组的大小,而题目给的是一个二维棋盘。
+
+这个很简单,二维坐标 `(x,y)` 可以转换成 `x * n + y` 这个数(`m` 是棋盘的行数,`n` 是棋盘的列数),**敲黑板,这是将二维坐标映射到一维的常用技巧**。
+
+其次,我们之前描述的「祖师爷」是虚构的,需要给他老人家留个位置。索引 `[0.. m*n-1]` 都是棋盘内坐标的一维映射,那就让这个虚拟的 `dummy` 节点占据索引 `m * n` 好了。
+
+看解法代码:
+
+```java
+void solve(char[][] board) {
+ if (board.length == 0) return;
+
+ int m = board.length;
+ int n = board[0].length;
+ // 给 dummy 留一个额外位置
+ UF uf = new UF(m * n + 1);
+ int dummy = m * n;
+ // 将首列和末列的 O 与 dummy 连通
+ for (int i = 0; i < m; i++) {
+ if (board[i][0] == 'O')
+ uf.union(i * n, dummy);
+ if (board[i][n - 1] == 'O')
+ uf.union(i * n + n - 1, dummy);
+ }
+ // 将首行和末行的 O 与 dummy 连通
+ for (int j = 0; j < n; j++) {
+ if (board[0][j] == 'O')
+ uf.union(j, dummy);
+ if (board[m - 1][j] == 'O')
+ uf.union(n * (m - 1) + j, dummy);
+ }
+ // 方向数组 d 是上下左右搜索的常用手法
+ int[][] d = new int[][]{{1,0}, {0,1}, {0,-1}, {-1,0}};
+ for (int i = 1; i < m - 1; i++)
+ for (int j = 1; j < n - 1; j++)
+ if (board[i][j] == 'O')
+ // 将此 O 与上下左右的 O 连通
+ for (int k = 0; k < 4; k++) {
+ int x = i + d[k][0];
+ int y = j + d[k][1];
+ if (board[x][y] == 'O')
+ uf.union(x * n + y, i * n + j);
+ }
+ // 所有不和 dummy 连通的 O,都要被替换
+ for (int i = 1; i < m - 1; i++)
+ for (int j = 1; j < n - 1; j++)
+ if (!uf.connected(dummy, i * n + j))
+ board[i][j] = 'X';
+}
+
+class UF {
+ // 见上文
+}
+```
+
+这段代码很长,其实就是刚才的思路实现,只有和边界 `O` 相连的 `O` 才具有和 `dummy` 的连通性,他们不会被替换。
+其实用 Union-Find 算法解决这个简单的问题有点杀鸡用牛刀,它可以解决更复杂,更具有技巧性的问题,**主要思路是适时增加虚拟节点,想办法让元素「分门别类」,建立动态连通关系**。
+力扣第 990 题「等式方程的可满足性」用 Union-Find 算法就显得十分优美了,题目是这样:
+
+给你一个数组 `equations`,装着若干字符串表示的算式。每个算式 `equations[i]` 长度都是 4,而且只有这两种情况:`a==b` 或者 `a!=b`,其中 `a,b` 可以是任意小写字母。你写一个算法,如果 `equations` 中所有算式都不会互相冲突,返回 true,否则返回 false。
+
+比如说,输入 `["a==b","b!=c","c==a"]`,算法返回 false,因为这三个算式不可能同时正确。
+
+再比如,输入 `["c==c","b==d","x!=z"]`,算法返回 true,因为这三个算式并不会造成逻辑冲突。
+
+我们前文说过,动态连通性其实就是一种等价关系,具有「自反性」「传递性」和「对称性」,其实 `==` 关系也是一种等价关系,具有这些性质。所以这个问题用 Union-Find 算法就很自然。
+
+**核心思想是,将 `equations` 中的算式根据 `==` 和 `!=` 分成两部分,先处理 `==` 算式,使得他们通过相等关系各自勾结成门派(连通分量);然后处理 `!=` 算式,检查不等关系是否破坏了相等关系的连通性**。
+
+```java
+boolean equationsPossible(String[] equations) {
+ // 26 个英文字母
+ UF uf = new UF(26);
+ // 先让相等的字母形成连通分量
+ for (String eq : equations) {
+ if (eq.charAt(1) == '=') {
+ char x = eq.charAt(0);
+ char y = eq.charAt(3);
+ uf.union(x - 'a', y - 'a');
+ }
+ }
+ // 检查不等关系是否打破相等关系的连通性
+ for (String eq : equations) {
+ if (eq.charAt(1) == '!') {
+ char x = eq.charAt(0);
+ char y = eq.charAt(3);
+ // 如果相等关系成立,就是逻辑冲突
+ if (uf.connected(x - 'a', y - 'a'))
+ return false;
+ }
+ }
+ return true;
+}
+
+class UF {
+ // 见上文
+}
+```
+
+至此,这道判断算式合法性的问题就解决了,借助 Union-Find 算法,是不是很简单呢?
+
+最后,Union-Find 算法也会在一些其他经典图论算法中用到,比如判断「图」和「树」,以及最小生成树的计算,详情见 [Kruskal 最小生成树算法](https://labuladong.github.io/article/fname.html?fname=kruskal)。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\350\257\246\350\247\243.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\350\257\246\350\247\243.md"
index 7fb0a6cad42efbe91918bdcba81e140c8bc38159..41138074d3caecfaac7a98ea7050a0600f087ac8 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\350\257\246\350\247\243.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\350\257\246\350\247\243.md"
@@ -1,40 +1,53 @@
-# 二分查找详解
+# 二分查找算法详解
+
+
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[704.二分查找](https://leetcode-cn.com/problems/binary-search)
-[34.在排序数组中查找元素的第一个和最后一个位置](https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array/)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [34. Find First and Last Position of Element in Sorted Array](https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/) | [34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/) | 🟠
+| [704. Binary Search](https://leetcode.com/problems/binary-search/) | [704. 二分查找](https://leetcode.cn/problems/binary-search/) | 🟢
+| - | [剑指 Offer 53 - I. 在排序数组中查找数字 I](https://leetcode.cn/problems/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof/) | 🟢
**-----------**
+> 本文有视频版:[二分搜索核心框架套路](https://www.bilibili.com/video/BV1Gt4y1b79Q/)
+
本文是前文 [二分搜索详解](https://mp.weixin.qq.com/s/uA2suoVykENmCQcKFMOSuQ) 的修订版,添加了对二分搜索算法更详细的分析。
先给大家讲个笑话乐呵一下:
有一天阿东到图书馆借了 N 本书,出图书馆的时候,警报响了,于是保安把阿东拦下,要检查一下哪本书没有登记出借。阿东正准备把每一本书在报警器下过一下,以找出引发警报的书,但是保安露出不屑的眼神:你连二分查找都不会吗?于是保安把书分成两堆,让第一堆过一下报警器,报警器响;于是再把这堆书分成两堆…… 最终,检测了 logN 次之后,保安成功的找到了那本引起警报的书,露出了得意和嘲讽的笑容。于是阿东背着剩下的书走了。
-从此,图书馆丢了 N - 1 本书。
+从此,图书馆丢了 N - 1 本书(手动狗头)。
二分查找并不简单,Knuth 大佬(发明 KMP 算法的那位)都说二分查找:**思路很简单,细节是魔鬼**。很多人喜欢拿整型溢出的 bug 说事儿,但是二分查找真正的坑根本就不是那个细节问题,而是在于到底要给 `mid` 加一还是减一,while 里到底用 `<=` 还是 `<`。
-你要是没有正确理解这些细节,写二分肯定就是玄学编程,有没有 bug 只能靠菩萨保佑。**我特意写了一首诗来歌颂该算法,概括本文的主要内容,建议保存**:
+你要是没有正确理解这些细节,写二分肯定就是玄学编程,有没有 bug 只能靠菩萨保佑(谁写谁知道)。我特意写了一首诗来歌颂该算法,概括本文的主要内容,建议保存(手动狗头):
-
+
-本文就来探究几个最常用的二分查找场景:寻找一个数、寻找左侧边界、寻找右侧边界。而且,我们就是要深入细节,比如不等号是否应该带等号,mid 是否应该加一等等。分析这些细节的差异以及出现这些差异的原因,保证你能灵活准确地写出正确的二分查找算法。
+本文就来探究几个最常用的二分查找场景:寻找一个数、寻找左侧边界、寻找右侧边界。而且,我们就是要深入细节,比如不等号是否应该带等号,`mid` 是否应该加一等等。分析这些细节的差异以及出现这些差异的原因,保证你能灵活准确地写出正确的二分查找算法。
+
+另外再声明一下,对于二分搜索的每一个场景,本文还会探讨多种代码写法,目的是为了让你理解出现这些细微差异的本质原因,最起码你看到别人的代码时不会懵逼。实际上这些写法没有优劣之分,你喜欢哪种就用哪种好了。
### 零、二分查找框架
@@ -60,8 +73,7 @@ int binarySearch(int[] nums, int target) {
其中 `...` 标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。后文用实例分析这些地方能有什么样的变化。
-另外声明一下,计算 mid 时需要防止溢出,代码中 `left + (right - left) / 2` 就和 `(left + right) / 2` 的结果相同,但是有效防止了 `left` 和 `right` 太大直接相加导致溢出。
-
+**另外提前说明一下,计算 `mid` 时需要防止溢出**,代码中 `left + (right - left) / 2` 就和 `(left + right) / 2` 的结果相同,但是有效防止了 `left` 和 `right` 太大,直接相加导致溢出的情况。
### 一、寻找一个数(基本的二分搜索)
@@ -85,6 +97,8 @@ int binarySearch(int[] nums, int target) {
}
```
+这段代码可以解决力扣第 704 题「二分查找」,但我们深入探讨一下其中的细节。
+
**1、为什么 while 循环的条件中是 <=,而不是 <**?
答:因为初始化 `right` 的赋值是 `nums.length - 1`,即最后一个元素的索引,而不是 `nums.length`。
@@ -116,14 +130,13 @@ int binarySearch(int[] nums, int target) {
return nums[left] == target ? left : -1;
```
-
**2、为什么 `left = mid + 1`,`right = mid - 1`?我看有的代码是 `right = mid` 或者 `left = mid`,没有这些加加减减,到底怎么回事,怎么判断**?
答:这也是二分查找的一个难点,不过只要你能理解前面的内容,就能够很容易判断。
刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即 `[left, right]`。那么当我们发现索引 `mid` 不是要找的 `target` 时,下一步应该去搜索哪里呢?
-当然是去搜索 `[left, mid-1]` 或者 `[mid+1, right]` 对不对?**因为 `mid` 已经搜索过,应该从搜索区间中去除**。
+当然是去搜索区间 `[left, mid-1]` 或者区间 `[mid+1, right]` 对不对?**因为 `mid` 已经搜索过,应该从搜索区间中去除**。
**3、此算法有什么缺陷**?
@@ -131,23 +144,21 @@ int binarySearch(int[] nums, int target) {
比如说给你有序数组 `nums = [1,2,2,2,3]`,`target` 为 2,此算法返回的索引是 2,没错。但是如果我想得到 `target` 的左侧边界,即索引 1,或者我想得到 `target` 的右侧边界,即索引 3,这样的话此算法是无法处理的。
-这样的需求很常见,**你也许会说,找到一个 target,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的复杂度了**。
+这样的需求很常见,**你也许会说,找到一个 `target`,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的复杂度了**。
我们后续的算法就来讨论这两种二分查找的算法。
-
### 二、寻找左侧边界的二分搜索
以下是最常见的代码形式,其中的标记是需要注意的细节:
```java
int left_bound(int[] nums, int target) {
- if (nums.length == 0) return -1;
int left = 0;
int right = nums.length; // 注意
while (left < right) { // 注意
- int mid = (left + right) / 2;
+ int mid = left + (right - left) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
@@ -166,37 +177,31 @@ int left_bound(int[] nums, int target) {
`while(left < right)` 终止的条件是 `left == right`,此时搜索区间 `[left, left)` 为空,所以可以正确终止。
-PS:这里先要说一个搜索左右边界和上面这个算法的一个区别,也是很多读者问的:**刚才的 `right` 不是 `nums.length - 1` 吗,为啥这里非要写成 `nums.length` 使得「搜索区间」变成左闭右开呢**?
-
-因为对于搜索左右侧边界的二分查找,这种写法比较普遍,我就拿这种写法举例了,保证你以后遇到这类代码可以理解。你非要用两端都闭的写法反而更简单,我会在后面写相关的代码,把三种二分搜索都用一种两端都闭的写法统一起来,你耐心往后看就行了。
+> PS:这里先要说一个搜索左右边界和上面这个算法的一个区别,也是很多读者问的:**刚才的 `right` 不是 `nums.length - 1` 吗,为啥这里非要写成 `nums.length` 使得「搜索区间」变成左闭右开呢**?
+>
+> 因为对于搜索左右侧边界的二分查找,这种写法比较普遍,我就拿这种写法举例了,保证你以后遇到这类代码可以理解。你非要用两端都闭的写法反而更简单,我会在后面写相关的代码,把三种二分搜索都用一种两端都闭的写法统一起来,你耐心往后看就行了。
**2、为什么没有返回 -1 的操作?如果 `nums` 中不存在 `target` 这个值,怎么办**?
-答:因为要一步一步来,先理解一下这个「左侧边界」有什么特殊含义:
-
-
-
-对于这个数组,算法会返回 1。这个 1 的含义可以这样解读:`nums` 中小于 2 的元素有 1 个。
+答:其实很简单,在返回的时候额外判断一下 `nums[left]` 是否等于 `target` 就行了,如果不等于,就说明 `target` 不存在。
-比如对于有序数组 `nums = [2,3,5,7]`, `target = 1`,算法会返回 0,含义是:`nums` 中小于 1 的元素有 0 个。
+不过我们得考察一下 `left` 的取值范围,免得索引越界。假如输入的 `target` 非常大,那么就会一直触发 `nums[mid] < target` 的 if 条件,`left` 会一直向右侧移动,直到等于 `right`,while 循环结束。
-再比如说 `nums = [2,3,5,7], target = 8`,算法会返回 4,含义是:`nums` 中小于 8 的元素有 4 个。
-
-综上可以看出,函数的返回值(即 `left` 变量的值)取值区间是闭区间 `[0, nums.length]`,所以我们简单添加两行代码就能在正确的时候 return -1:
+由于这里 `right` 初始化为 `nums.length`,所以 `left` 变量的取值区间是闭区间 `[0, nums.length]`,那么我们在检查 `nums[left]` 之前需要额外判断一下,防止索引越界:
```java
while (left < right) {
//...
}
-// target 比所有数都大
+// 此时 target 比所有数都大,返回 -1
if (left == nums.length) return -1;
-// 类似之前算法的处理方式
+// 判断一下 nums[left] 是不是 target
return nums[left] == target ? left : -1;
```
**3、为什么 `left = mid + 1`,`right = mid` ?和之前的算法不一样**?
-答:这个很好解释,因为我们的「搜索区间」是 `[left, right)` 左闭右开,所以当 `nums[mid]` 被检测之后,下一步的搜索区间应该去掉 `mid` 分割成两个区间,即 `[left, mid)` 或 `[mid + 1, right)`。
+答:这个很好解释,因为我们的「搜索区间」是 `[left, right)` 左闭右开,所以当 `nums[mid]` 被检测之后,下一步应该去 `mid` 的左侧或者右侧区间搜索,即 `[left, mid)` 或 `[mid + 1, right)`。
**4、为什么该算法能够搜索左侧边界**?
@@ -244,16 +249,13 @@ if (nums[mid] < target) {
}
```
-由于 while 的退出条件是 `left == right + 1`,所以当 `target` 比 `nums` 中所有元素都大时,会存在以下情况使得索引越界:
-
-
-
-因此,最后返回结果的代码应该检查越界情况:
+和刚才相同,如果想在找不到 `target` 的时候返回 -1,那么检查一下 `nums[left]` 和 `target` 是否相等即可:
```java
-if (left >= nums.length || nums[left] != target)
- return -1;
-return left;
+// 此时 target 比所有数都大,返回 -1
+if (left == nums.length) return -1;
+// 判断一下 nums[left] 是不是 target
+return nums[left] == target ? left : -1;
```
至此,整个算法就写完了,完整代码如下:
@@ -275,10 +277,11 @@ int left_bound(int[] nums, int target) {
right = mid - 1;
}
}
- // 检查出界情况
- if (left >= nums.length || nums[left] != target)
- return -1;
- return left;
+ // 判断 target 是否存在于 nums 中
+ // 此时 target 比所有数都大,返回 -1
+ if (left == nums.length) return -1;
+ // 判断一下 nums[left] 是不是 target
+ return nums[left] == target ? left : -1;
}
```
@@ -286,15 +289,14 @@ int left_bound(int[] nums, int target) {
### 三、寻找右侧边界的二分查找
-类似寻找左侧边界的算法,这里也会提供两种写法,还是先写常见的左闭右开的写法,只有两处和搜索左侧边界不同,已标注:
+类似寻找左侧边界的算法,这里也会提供两种写法,还是先写常见的左闭右开的写法,只有两处和搜索左侧边界不同:
```java
int right_bound(int[] nums, int target) {
- if (nums.length == 0) return -1;
int left = 0, right = nums.length;
while (left < right) {
- int mid = (left + right) / 2;
+ int mid = left + (right - left) / 2;
if (nums[mid] == target) {
left = mid + 1; // 注意
} else if (nums[mid] < target) {
@@ -316,36 +318,42 @@ if (nums[mid] == target) {
left = mid + 1;
```
-当 `nums[mid] == target` 时,不要立即返回,而是增大「搜索区间」的下界 `left`,使得区间不断向右收缩,达到锁定右侧边界的目的。
+当 `nums[mid] == target` 时,不要立即返回,而是增大「搜索区间」的左边界 `left`,使得区间不断向右靠拢,达到锁定右侧边界的目的。
**2、为什么最后返回 `left - 1` 而不像左侧边界的函数,返回 `left`?而且我觉得这里既然是搜索右侧边界,应该返回 `right` 才对**。
答:首先,while 循环的终止条件是 `left == right`,所以 `left` 和 `right` 是一样的,你非要体现右侧的特点,返回 `right - 1` 好了。
-至于为什么要减一,这是搜索右侧边界的一个特殊点,关键在这个条件判断:
+至于为什么要减一,这是搜索右侧边界的一个特殊点,关键在锁定右边界时的这个条件判断:
```java
+// 增大 left,锁定右侧边界
if (nums[mid] == target) {
left = mid + 1;
// 这样想: mid = left - 1
```
-
+
因为我们对 `left` 的更新必须是 `left = mid + 1`,就是说 while 循环结束时,`nums[left]` 一定不等于 `target` 了,而 `nums[left-1]` 可能是 `target`。
-至于为什么 `left` 的更新必须是 `left = mid + 1`,同左侧边界搜索,就不再赘述。
+至于为什么 `left` 的更新必须是 `left = mid + 1`,当然是为了把 `nums[mid]` 排除出搜索区间,这里就不再赘述。
**3、为什么没有返回 -1 的操作?如果 `nums` 中不存在 `target` 这个值,怎么办**?
-答:类似之前的左侧边界搜索,因为 while 的终止条件是 `left == right`,就是说 `left` 的取值范围是 `[0, nums.length]`,所以可以添加两行代码,正确地返回 -1:
+答:只要在最后判断一下 `nums[left-1]` 是不是 `target` 就行了。
+
+类似之前的左侧边界搜索,`left` 的取值范围是 `[0, nums.length]`,但由于我们最后返回的是 `left - 1`,所以 `left` 取值为 0 的时候会造成索引越界,额外处理一下即可正确地返回 -1:
```java
while (left < right) {
// ...
}
-if (left == 0) return -1;
-return nums[left-1] == target ? (left-1) : -1;
+// 判断 target 是否存在于 nums 中
+// 此时 left - 1 索引越界
+if (left - 1 < 0) return -1;
+// 判断一下 nums[left] 是不是 target
+return nums[left - 1] == target ? (left - 1) : -1;
```
**4、是否也可以把这个算法的「搜索区间」也统一成两端都闭的形式呢?这样这三个写法就完全统一了,以后就可以闭着眼睛写出来了**。
@@ -366,22 +374,21 @@ int right_bound(int[] nums, int target) {
left = mid + 1;
}
}
- // 这里改为检查 right 越界的情况,见下图
- if (right < 0 || nums[right] != target)
- return -1;
- return right;
+ // 最后改成返回 left - 1
+ if (left - 1 < 0) return -1;
+ return nums[left - 1] == target ? (left - 1) : -1;
}
```
-当 `target` 比所有元素都小时,`right` 会被减到 -1,所以需要在最后防止越界:
-
-
+当然,由于 while 的结束条件为 `right == left - 1`,所以你把上述代码中的 `left - 1` 都改成 `right` 也没有问题,这样可能更有利于看出来这是在「搜索右侧边界」。
至此,搜索右侧边界的二分查找的两种写法也完成了,其实将「搜索区间」统一成两端都闭反而更容易记忆,你说是吧?
### 四、逻辑统一
-来梳理一下这些细节差异的因果逻辑:
+有了搜索左右边界的二分搜索,你可以去解决力扣第 34 题「在排序数组中查找元素的第一个和最后一个位置」,
+
+接下来梳理一下这些细节差异的因果逻辑:
**第一个,最基本的二分查找算法**:
@@ -457,13 +464,13 @@ int left_bound(int[] nums, int target) {
right = mid - 1;
}
}
- // 最后要检查 left 越界的情况
- if (left >= nums.length || nums[left] != target)
- return -1;
- return left;
+ // 判断 target 是否存在于 nums 中
+ // 此时 target 比所有数都大,返回 -1
+ if (left == nums.length) return -1;
+ // 判断一下 nums[left] 是不是 target
+ return nums[left] == target ? left : -1;
}
-
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
@@ -477,16 +484,14 @@ int right_bound(int[] nums, int target) {
left = mid + 1;
}
}
- // 最后要检查 right 越界的情况
- if (right < 0 || nums[right] != target)
- return -1;
- return right;
+ // 此时 left - 1 索引越界
+ if (left - 1 < 0) return -1;
+ // 判断一下 nums[left] 是不是 target
+ return nums[left - 1] == target ? (left - 1) : -1;
}
```
-如果以上内容你都能理解,那么恭喜你,二分查找算法的细节不过如此。
-
-通过本文,你学会了:
+如果以上内容你都能理解,那么恭喜你,二分查找算法的细节不过如此。通过本文,你学会了:
1、分析二分查找代码时,不要出现 else,全部展开成 else if 方便理解。
@@ -494,19 +499,19 @@ int right_bound(int[] nums, int target) {
3、如需定义左闭右开的「搜索区间」搜索左右边界,只要在 `nums[mid] == target` 时做修改即可,搜索右侧时需要减一。
-4、如果将「搜索区间」全都统一成两端都闭,好记,只要稍改 `nums[mid] == target` 条件处的代码和返回的逻辑即可,**推荐拿小本本记下,作为二分搜索模板**。
+4、如果将「搜索区间」全都统一成两端都闭,好记,只要稍改 `nums[mid] == target` 条件处的代码和返回的逻辑即可,推荐拿小本本记下,作为二分搜索模板。
+最后我想说,以上二分搜索的框架属于「术」的范畴,如果上升到「道」的层面,**二分思维的精髓就是:通过已知信息尽可能多地收缩(折半)搜索空间**,从而增加穷举效率,快速找到目标。
+理解本文能保证你写出正确的二分查找的代码,但实际题目中不会直接让你写二分代码,我会在 [二分查找的变体](https://appktavsiei5995.pc.xiaoe-tech.com/detail/i_62a07736e4b01a485209b0b4/1) 和 [二分查找的运用](https://labuladong.github.io/article/fname.html?fname=二分运用) 中进一步讲解如何把二分思维运用到更多算法题中。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[704.二分查找](https://leetcode-cn.com/problems/binary-search)
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\211\215\347\274\200\345\222\214\346\212\200\345\267\247.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\211\215\347\274\200\345\222\214\346\212\200\345\267\247.md"
index 50161879bcdfc4258b95ac746a77abc737fe48a2..df9cf835463108e89ded2b56ddd7bb3b270f0d75 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\211\215\347\274\200\345\222\214\346\212\200\345\267\247.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\211\215\347\274\200\345\222\214\346\212\200\345\267\247.md"
@@ -1,161 +1,194 @@
-# 前缀和技巧
+# 经典数组技巧:前缀和数组
+
+
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-
-[560.和为K的子数组](https://leetcode-cn.com/problems/subarray-sum-equals-k)
-
-**-----------**
-今天来聊一道简单却十分巧妙的算法问题:算出一共有几个和为 `k` 的子数组。
-
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-那我把所有子数组都穷举出来,算它们的和,看看谁的和等于 `k` 不就行了。
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [303. Range Sum Query - Immutable](https://leetcode.com/problems/range-sum-query-immutable/) | [303. 区域和检索 - 数组不可变](https://leetcode.cn/problems/range-sum-query-immutable/) | 🟢
+| [304. Range Sum Query 2D - Immutable](https://leetcode.com/problems/range-sum-query-2d-immutable/) | [304. 二维区域和检索 - 矩阵不可变](https://leetcode.cn/problems/range-sum-query-2d-immutable/) | 🟠
+| - | [剑指 Offer II 013. 二维子矩阵的和](https://leetcode.cn/problems/O4NDxx/) | 🟠
-关键是,**如何快速得到某个子数组的和呢**,比如说给你一个数组 `nums`,让你实现一个接口 `sum(i, j)`,这个接口要返回 `nums[i..j]` 的和,而且会被多次调用,你怎么实现这个接口呢?
-
-因为接口要被多次调用,显然不能每次都去遍历 `nums[i..j]`,有没有一种快速的方法在 O(1) 时间内算出 `nums[i..j]` 呢?这就需要**前缀和**技巧了。
+**-----------**
-### 一、什么是前缀和
+> 本文有视频版:[前缀和/差分数组技巧精讲](https://www.bilibili.com/video/BV1NY4y1J7xQ/)
-前缀和的思路是这样的,对于一个给定的数组 `nums`,我们额外开辟一个前缀和数组进行预处理:
+前缀和技巧适用于快速、频繁地计算一个索引区间内的元素之和。
-```java
-int n = nums.length;
-// 前缀和数组
-int[] preSum = new int[n + 1];
-preSum[0] = 0;
-for (int i = 0; i < n; i++)
- preSum[i + 1] = preSum[i] + nums[i];
-```
+### 一维数组中的前缀和
-
+先看一道例题,力扣第 303 题「区域和检索 - 数组不可变」,让你计算数组区间内元素的和,这是一道标准的前缀和问题:
-这个前缀和数组 `preSum` 的含义也很好理解,`preSum[i]` 就是 `nums[0..i-1]` 的和。那么如果我们想求 `nums[i..j]` 的和,只需要一步操作 `preSum[j+1]-preSum[i]` 即可,而不需要重新去遍历数组了。
+
-回到这个子数组问题,我们想求有多少个子数组的和为 k,借助前缀和技巧很容易写出一个解法:
+题目要求你实现这样一个类:
```java
-int subarraySum(int[] nums, int k) {
- int n = nums.length;
- // 构造前缀和
- int[] sum = new int[n + 1];
- sum[0] = 0;
- for (int i = 0; i < n; i++)
- sum[i + 1] = sum[i] + nums[i];
-
- int ans = 0;
- // 穷举所有子数组
- for (int i = 1; i <= n; i++)
- for (int j = 0; j < i; j++)
- // sum of nums[j..i-1]
- if (sum[i] - sum[j] == k)
- ans++;
+class NumArray {
- return ans;
+ public NumArray(int[] nums) {}
+
+ /* 查询闭区间 [left, right] 的累加和 */
+ public int sumRange(int left, int right) {}
}
```
-这个解法的时间复杂度 `O(N^2)` 空间复杂度 `O(N)`,并不是最优的解法。不过通过这个解法理解了前缀和数组的工作原理之后,可以使用一些巧妙的办法把时间复杂度进一步降低。
+`sumRange` 函数需要计算并返回一个索引区间之内的元素和,没学过前缀和的人可能写出如下代码:
-### 二、优化解法
+```java
+class NumArray {
-前面的解法有嵌套的 for 循环:
+ private int[] nums;
-```java
-for (int i = 1; i <= n; i++)
- for (int j = 0; j < i; j++)
- if (sum[i] - sum[j] == k)
- ans++;
+ public NumArray(int[] nums) {
+ this.nums = nums;
+ }
+
+ public int sumRange(int left, int right) {
+ int res = 0;
+ for (int i = left; i <= right; i++) {
+ res += nums[i];
+ }
+ return res;
+ }
+}
```
-第二层 for 循环在干嘛呢?翻译一下就是,**在计算,有几个 `j` 能够使得 `sum[i]` 和 `sum[j]` 的差为 k。**毎找到一个这样的 `j`,就把结果加一。
+这样,可以达到效果,但是效率很差,因为 `sumRange` 方法会被频繁调用,而它的时间复杂度是 `O(N)`,其中 `N` 代表 `nums` 数组的长度。
-我们可以把 if 语句里的条件判断移项,这样写:
-
-```java
-if (sum[j] == sum[i] - k)
- ans++;
-```
+这道题的最优解法是使用前缀和技巧,将 `sumRange` 函数的时间复杂度降为 `O(1)`,说白了就是不要在 `sumRange` 里面用 for 循环,咋整?
-优化的思路是:**我直接记录下有几个 `sum[j]` 和 `sum[i] - k` 相等,直接更新结果,就避免了内层的 for 循环**。我们可以用哈希表,在记录前缀和的同时记录该前缀和出现的次数。
+直接看代码实现:
```java
-int subarraySum(int[] nums, int k) {
- int n = nums.length;
- // map:前缀和 -> 该前缀和出现的次数
- HashMap
- preSum = new HashMap<>();
- // base case
- preSum.put(0, 1);
-
- int ans = 0, sum0_i = 0;
- for (int i = 0; i < n; i++) {
- sum0_i += nums[i];
- // 这是我们想找的前缀和 nums[0..j]
- int sum0_j = sum0_i - k;
- // 如果前面有这个前缀和,则直接更新答案
- if (preSum.containsKey(sum0_j))
- ans += preSum.get(sum0_j);
- // 把前缀和 nums[0..i] 加入并记录出现次数
- preSum.put(sum0_i,
- preSum.getOrDefault(sum0_i, 0) + 1);
+class NumArray {
+ // 前缀和数组
+ private int[] preSum;
+
+ /* 输入一个数组,构造前缀和 */
+ public NumArray(int[] nums) {
+ // preSum[0] = 0,便于计算累加和
+ preSum = new int[nums.length + 1];
+ // 计算 nums 的累加和
+ for (int i = 1; i < preSum.length; i++) {
+ preSum[i] = preSum[i - 1] + nums[i - 1];
+ }
+ }
+
+ /* 查询闭区间 [left, right] 的累加和 */
+ public int sumRange(int left, int right) {
+ return preSum[right + 1] - preSum[left];
}
- return ans;
}
```
-比如说下面这个情况,需要前缀和 8 就能找到和为 k 的子数组了,之前的暴力解法需要遍历数组去数有几个 8,而优化解法借助哈希表可以直接得知有几个前缀和为 8。
+核心思路是我们 new 一个新的数组 `preSum` 出来,`preSum[i]` 记录 `nums[0..i-1]` 的累加和,看图 10 = 3 + 5 + 2:
-
+
-这样,就把时间复杂度降到了 `O(N)`,是最优解法了。
+看这个 `preSum` 数组,如果我想求索引区间 `[1, 4]` 内的所有元素之和,就可以通过 `preSum[5] - preSum[1]` 得出。
-### 三、总结
+这样,`sumRange` 函数仅仅需要做一次减法运算,避免了每次进行 for 循环调用,最坏时间复杂度为常数 `O(1)`。
-前缀和不难,却很有用,主要用于处理数组区间的问题。
+这个技巧在生活中运用也挺广泛的,比方说,你们班上有若干同学,每个同学有一个期末考试的成绩(满分 100 分),那么请你实现一个 API,输入任意一个分数段,返回有多少同学的成绩在这个分数段内。
-比如说,让你统计班上同学考试成绩在不同分数段的百分比,也可以利用前缀和技巧:
+那么,你可以先通过计数排序的方式计算每个分数具体有多少个同学,然后利用前缀和技巧来实现分数段查询的 API:
```java
int[] scores; // 存储着所有同学的分数
-// 试卷满分 150 分
-int[] count = new int[150 + 1]
+// 试卷满分 100 分
+int[] count = new int[100 + 1]
// 记录每个分数有几个同学
for (int score : scores)
count[score]++
// 构造前缀和
for (int i = 1; i < count.length; i++)
count[i] = count[i] + count[i-1];
+
+// 利用 count 这个前缀和数组进行分数段查询
+```
+
+接下来,我们看一看前缀和思路在二维数组中如何运用。
+
+### 二维矩阵中的前缀和
+
+这是力扣第 304 题「二维区域和检索 - 矩阵不可变」,其实和上一题类似,上一题是让你计算子数组的元素之和,这道题让你计算二维矩阵中子矩阵的元素之和:
+
+
+
+比如说输入的 `matrix` 如下图:
+
+
+
+按照题目要求,矩阵左上角为坐标原点 `(0, 0)`,那么 `sumRegion([2,1,4,3])` 就是图中红色的子矩阵,你需要返回该子矩阵的元素和 8。
+
+当然,你可以用一个嵌套 for 循环去遍历这个矩阵,但这样的话 `sumRegion` 函数的时间复杂度就高了,你算法的格局就低了。
+
+注意任意子矩阵的元素和可以转化成它周边几个大矩阵的元素和的运算:
+
+
+
+而这四个大矩阵有一个共同的特点,就是左上角都是 `(0, 0)` 原点。
+
+那么做这道题更好的思路和一维数组中的前缀和是非常类似的,我们可以维护一个二维 `preSum` 数组,专门记录以原点为顶点的矩阵的元素之和,就可以用几次加减运算算出任何一个子矩阵的元素和:
+
+```java
+class NumMatrix {
+ // 定义:preSum[i][j] 记录 matrix 中子矩阵 [0, 0, i-1, j-1] 的元素和
+ private int[][] preSum;
+
+ public NumMatrix(int[][] matrix) {
+ int m = matrix.length, n = matrix[0].length;
+ if (m == 0 || n == 0) return;
+ // 构造前缀和矩阵
+ preSum = new int[m + 1][n + 1];
+ for (int i = 1; i <= m; i++) {
+ for (int j = 1; j <= n; j++) {
+ // 计算每个矩阵 [0, 0, i, j] 的元素和
+ preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
+ }
+ }
+ }
+
+ // 计算子矩阵 [x1, y1, x2, y2] 的元素和
+ public int sumRegion(int x1, int y1, int x2, int y2) {
+ // 目标矩阵之和由四个相邻矩阵运算获得
+ return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
+ }
+}
```
-这样,给你任何一个分数段,你都能通过前缀和相减快速计算出这个分数段的人数,百分比也就很容易计算了。
+这样,`sumRegion` 函数的时间复杂度也用前缀和技巧优化到了 O(1),这是典型的「空间换时间」思路。
+
+前缀和技巧就讲到这里,应该说这个算法技巧是会者不难难者不会,实际运用中还是要多培养自己的思维灵活性,做到一眼看出题目是一个前缀和问题。
-但是,稍微复杂一些的算法问题,不止考察简单的前缀和技巧。比如本文探讨的这道题目,就需要借助前缀和的思路做进一步的优化,借助哈希表去除不必要的嵌套循环。可见对题目的理解和细节的分析能力对于算法的优化是至关重要的。
+除了本文举例的基本用法,前缀和数组经常和其他数据结构或算法技巧相结合,我会在 [前缀和技巧高频习题](https://appktavsiei5995.pc.xiaoe-tech.com/detail/i_627cd61de4b0cedf38b0f3a0/1) 中举例讲解。
-希望本文对你有帮助。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\217\214\346\214\207\351\222\210\346\212\200\345\267\247.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\217\214\346\214\207\351\222\210\346\212\200\345\267\247.md"
index ab67260eafa19d8422c308fa8570893875031a93..a0d8902501f05e606a1bf7e7fd37bdd4b6b7f249 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\217\214\346\214\207\351\222\210\346\212\200\345\267\247.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\217\214\346\214\207\351\222\210\346\212\200\345\267\247.md"
@@ -1,165 +1,243 @@
-# 双指针技巧总结
+# 数组双指针技巧汇总
+
+
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[141.环形链表](https://leetcode-cn.com/problems/linked-list-cycle)
-[142.环形链表II](https://leetcode-cn.com/problems/linked-list-cycle-ii)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-[167.两数之和 II - 输入有序数组](https://leetcode-cn.com/problems/two-sum-ii-input-array-is-sorted)
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [167. Two Sum II - Input Array Is Sorted](https://leetcode.com/problems/two-sum-ii-input-array-is-sorted/) | [167. 两数之和 II - 输入有序数组](https://leetcode.cn/problems/two-sum-ii-input-array-is-sorted/) | 🟢
+| [26. Remove Duplicates from Sorted Array](https://leetcode.com/problems/remove-duplicates-from-sorted-array/) | [26. 删除有序数组中的重复项](https://leetcode.cn/problems/remove-duplicates-from-sorted-array/) | 🟢
+| [27. Remove Element](https://leetcode.com/problems/remove-element/) | [27. 移除元素](https://leetcode.cn/problems/remove-element/) | 🟢
+| [283. Move Zeroes](https://leetcode.com/problems/move-zeroes/) | [283. 移动零](https://leetcode.cn/problems/move-zeroes/) | 🟢
+| [344. Reverse String](https://leetcode.com/problems/reverse-string/) | [344. 反转字符串](https://leetcode.cn/problems/reverse-string/) | 🟢
+| [5. Longest Palindromic Substring](https://leetcode.com/problems/longest-palindromic-substring/) | [5. 最长回文子串](https://leetcode.cn/problems/longest-palindromic-substring/) | 🟠
+| [83. Remove Duplicates from Sorted List](https://leetcode.com/problems/remove-duplicates-from-sorted-list/) | [83. 删除排序链表中的重复元素](https://leetcode.cn/problems/remove-duplicates-from-sorted-list/) | 🟢
+| - | [剑指 Offer 57. 和为s的两个数字](https://leetcode.cn/problems/he-wei-sde-liang-ge-shu-zi-lcof/) | 🟢
+| - | [剑指 Offer II 006. 排序数组中两个数字之和](https://leetcode.cn/problems/kLl5u1/) | 🟢
**-----------**
-我把双指针技巧再分为两类,一类是「快慢指针」,一类是「左右指针」。前者解决主要解决链表中的问题,比如典型的判定链表中是否包含环;后者主要解决数组(或者字符串)中的问题,比如二分查找。
+> 本文有视频版:[数组双指针技巧汇总](https://www.bilibili.com/video/BV1iG411W7Wm/)
-### 一、快慢指针的常见算法
+在处理数组和链表相关问题时,双指针技巧是经常用到的,双指针技巧主要分为两类:**左右指针**和**快慢指针**。
-快慢指针一般都初始化指向链表的头结点 head,前进时快指针 fast 在前,慢指针 slow 在后,巧妙解决一些链表中的问题。
+所谓左右指针,就是两个指针相向而行或者相背而行;而所谓快慢指针,就是两个指针同向而行,一快一慢。
-**1、判定链表中是否含有环**
+对于单链表来说,大部分技巧都属于快慢指针,前文 [单链表的六大解题套路](https://labuladong.github.io/article/fname.html?fname=链表技巧) 都涵盖了,比如链表环判断,倒数第 `K` 个链表节点等问题,它们都是通过一个 `fast` 快指针和一个 `slow` 慢指针配合完成任务。
-这应该属于链表最基本的操作了,如果读者已经知道这个技巧,可以跳过。
+在数组中并没有真正意义上的指针,但我们可以把索引当做数组中的指针,这样也可以在数组中施展双指针技巧,**本文主要讲数组相关的双指针算法**。
-单链表的特点是每个节点只知道下一个节点,所以一个指针的话无法判断链表中是否含有环的。
+### 一、快慢指针技巧
-如果链表中不含环,那么这个指针最终会遇到空指针 null 表示链表到头了,这还好说,可以判断该链表不含环。
-```java
+**数组问题中比较常见的快慢指针技巧,是让你原地修改数组**。
-boolean hasCycle(ListNode head) {
- while (head != null)
- head = head.next;
- return false;
-}
-```
+比如说看下力扣第 26 题「删除有序数组中的重复项」,让你在有序数组去重:
-但是如果链表中含有环,那么这个指针就会陷入死循环,因为环形数组中没有 null 指针作为尾部节点。
+
-经典解法就是用两个指针,一个跑得快,一个跑得慢。如果不含有环,跑得快的那个指针最终会遇到 null,说明链表不含环;如果含有环,快指针最终会超慢指针一圈,和慢指针相遇,说明链表含有环。
+函数签名如下:
```java
-boolean hasCycle(ListNode head) {
- ListNode fast, slow;
- fast = slow = head;
- while (fast != null && fast.next != null) {
- fast = fast.next.next;
- slow = slow.next;
-
- if (fast == slow) return true;
- }
- return false;
-}
+int removeDuplicates(int[] nums);
```
-**2、已知链表中含有环,返回这个环的起始位置**
+简单解释一下什么是原地修改:
-
+如果不是原地修改的话,我们直接 new 一个 `int[]` 数组,把去重之后的元素放进这个新数组中,然后返回这个新数组即可。
-这个问题一点都不困难,有点类似脑筋急转弯,先直接看代码:
+但是现在题目让你原地删除,不允许 new 新数组,只能在原数组上操作,然后返回一个长度,这样就可以通过返回的长度和原始数组得到我们去重后的元素有哪些了。
+
+由于数组已经排序,所以重复的元素一定连在一起,找出它们并不难。但如果毎找到一个重复元素就立即原地删除它,由于数组中删除元素涉及数据搬移,整个时间复杂度是会达到 `O(N^2)`。
+
+高效解决这道题就要用到快慢指针技巧:
+
+我们让慢指针 `slow` 走在后面,快指针 `fast` 走在前面探路,找到一个不重复的元素就赋值给 `slow` 并让 `slow` 前进一步。
+
+这样,就保证了 `nums[0..slow]` 都是无重复的元素,当 `fast` 指针遍历完整个数组 `nums` 后,`nums[0..slow]` 就是整个数组去重之后的结果。
+
+看代码:
```java
-ListNode detectCycle(ListNode head) {
- ListNode fast, slow;
- fast = slow = head;
- while (fast != null && fast.next != null) {
- fast = fast.next.next;
- slow = slow.next;
- if (fast == slow) break;
+int removeDuplicates(int[] nums) {
+ if (nums.length == 0) {
+ return 0;
}
- // 上面的代码类似 hasCycle 函数
- if (fast == null || fast.next == null) {
- // fast 遇到空指针说明没有环
- return null;
+ int slow = 0, fast = 0;
+ while (fast < nums.length) {
+ if (nums[fast] != nums[slow]) {
+ slow++;
+ // 维护 nums[0..slow] 无重复
+ nums[slow] = nums[fast];
+ }
+ fast++;
}
+ // 数组长度为索引 + 1
+ return slow + 1;
+}
+```
- slow = head;
- while (slow != fast) {
+算法执行的过程如下 GIF 图:
+
+
+
+再简单扩展一下,看看力扣第 83 题「删除排序链表中的重复元素」,如果给你一个有序的单链表,如何去重呢?
+
+其实和数组去重是一模一样的,唯一的区别是把数组赋值操作变成操作指针而已,你对照着之前的代码来看:
+
+```java
+ListNode deleteDuplicates(ListNode head) {
+ if (head == null) return null;
+ ListNode slow = head, fast = head;
+ while (fast != null) {
+ if (fast.val != slow.val) {
+ // nums[slow] = nums[fast];
+ slow.next = fast;
+ // slow++;
+ slow = slow.next;
+ }
+ // fast++
fast = fast.next;
- slow = slow.next;
}
- return slow;
+ // 断开与后面重复元素的连接
+ slow.next = null;
+ return head;
}
```
-可以看到,当快慢指针相遇时,让其中任一个指针指向头节点,然后让它俩以相同速度前进,再次相遇时所在的节点位置就是环开始的位置。这是为什么呢?
+算法执行的过程请看下面这个 GIF:
-第一次相遇时,假设慢指针 slow 走了 k 步,那么快指针 fast 一定走了 2k 步,也就是说比 slow 多走了 k 步(也就是环的长度)。
+
-
+这里可能有读者会问,链表中那些重复的元素并没有被删掉,就让这些节点在链表上挂着,合适吗?
-设相遇点距环的起点的距离为 m,那么环的起点距头结点 head 的距离为 k - m,也就是说如果从 head 前进 k - m 步就能到达环起点。
+这就要探讨不同语言的特性了,像 Java/Python 这类带有垃圾回收的语言,可以帮我们自动找到并回收这些「悬空」的链表节点的内存,而像 C++ 这类语言没有自动垃圾回收的机制,确实需要我们编写代码时手动释放掉这些节点的内存。
-巧的是,如果从相遇点继续前进 k - m 步,也恰好到达环起点。
+不过话说回来,就算法思维的培养来说,我们只需要知道这种快慢指针技巧即可。
-
+**除了让你在有序数组/链表中去重,题目还可能让你对数组中的某些元素进行「原地删除」**。
-所以,只要我们把快慢指针中的任一个重新指向 head,然后两个指针同速前进,k - m 步后就会相遇,相遇之处就是环的起点了。
+比如力扣第 27 题「移除元素」,看下题目:
-**3、寻找链表的中点**
+
-类似上面的思路,我们还可以让快指针一次前进两步,慢指针一次前进一步,当快指针到达链表尽头时,慢指针就处于链表的中间位置。
+函数签名如下:
```java
-while (fast != null && fast.next != null) {
- fast = fast.next.next;
- slow = slow.next;
+int removeElement(int[] nums, int val);
+```
+
+题目要求我们把 `nums` 中所有值为 `val` 的元素原地删除,依然需要使用快慢指针技巧:
+
+如果 `fast` 遇到值为 `val` 的元素,则直接跳过,否则就赋值给 `slow` 指针,并让 `slow` 前进一步。
+
+这和前面说到的数组去重问题解法思路是完全一样的,就不画 GIF 了,直接看代码:
+
+```java
+int removeElement(int[] nums, int val) {
+ int fast = 0, slow = 0;
+ while (fast < nums.length) {
+ if (nums[fast] != val) {
+ nums[slow] = nums[fast];
+ slow++;
+ }
+ fast++;
+ }
+ return slow;
}
-// slow 就在中间位置
-return slow;
```
-当链表的长度是奇数时,slow 恰巧停在中点位置;如果长度是偶数,slow 最终的位置是中间偏右:
+注意这里和有序数组去重的解法有一个细节差异,我们这里是先给 `nums[slow]` 赋值然后再给 `slow++`,这样可以保证 `nums[0..slow-1]` 是不包含值为 `val` 的元素的,最后的结果数组长度就是 `slow`。
-
+实现了这个 `removeElement` 函数,接下来看看力扣第 283 题「移动零」:
-寻找链表中点的一个重要作用是对链表进行归并排序。
+给你输入一个数组 `nums`,请你**原地修改**,将数组中的所有值为 0 的元素移到数组末尾,函数签名如下:
-回想数组的归并排序:求中点索引递归地把数组二分,最后合并两个有序数组。对于链表,合并两个有序链表是很简单的,难点就在于二分。
+```java
+void moveZeroes(int[] nums);
+```
-但是现在你学会了找到链表的中点,就能实现链表的二分了。关于归并排序的具体内容本文就不具体展开了。
+比如说给你输入 `nums = [0,1,4,0,2]`,你的算法没有返回值,但是会把 `nums` 数组原地修改成 `[1,4,2,0,0]`。
+结合之前说到的几个题目,你是否有已经有了答案呢?
-**4、寻找链表的倒数第 k 个元素**
+题目让我们将所有 0 移到最后,其实就相当于移除 `nums` 中的所有 0,然后再把后面的元素都赋值为 0 即可。
-我们的思路还是使用快慢指针,让快指针先走 k 步,然后快慢指针开始同速前进。这样当快指针走到链表末尾 null 时,慢指针所在的位置就是倒数第 k 个链表节点(为了简化,假设 k 不会超过链表长度):
+所以我们可以复用上一题的 `removeElement` 函数:
```java
-ListNode slow, fast;
-slow = fast = head;
-while (k-- > 0)
- fast = fast.next;
-
-while (fast != null) {
- slow = slow.next;
- fast = fast.next;
+void moveZeroes(int[] nums) {
+ // 去除 nums 中的所有 0,返回不含 0 的数组长度
+ int p = removeElement(nums, 0);
+ // 将 nums[p..] 的元素赋值为 0
+ for (; p < nums.length; p++) {
+ nums[p] = 0;
+ }
}
-return slow;
+
+// 见上文代码实现
+int removeElement(int[] nums, int val);
```
+到这里,原地修改数组的这些题目就已经差不多了。数组中另一大类快慢指针的题目就是「滑动窗口算法」。
-### 二、左右指针的常用算法
+我在另一篇文章 [滑动窗口算法核心框架详解](https://labuladong.github.io/article/fname.html?fname=滑动窗口技巧进阶) 给出了滑动窗口的代码框架:
+
+```cpp
+/* 滑动窗口算法框架 */
+void slidingWindow(string s, string t) {
+ unordered_map need, window;
+ for (char c : t) need[c]++;
+
+ int left = 0, right = 0;
+ int valid = 0;
+ while (right < s.size()) {
+ char c = s[right];
+ // 右移(增大)窗口
+ right++;
+ // 进行窗口内数据的一系列更新
+
+ while (window needs shrink) {
+ char d = s[left];
+ // 左移(缩小)窗口
+ left++;
+ // 进行窗口内数据的一系列更新
+ }
+ }
+}
+```
+
+具体的题目本文就不重复了,这里只强调滑动窗口算法的快慢指针特性:
-左右指针在数组中实际是指两个索引值,一般初始化为 left = 0, right = nums.length - 1 。
+`left` 指针在后,`right` 指针在前,两个指针中间的部分就是「窗口」,算法通过扩大和缩小「窗口」来解决某些问题。
+
+### 二、左右指针的常用算法
**1、二分查找**
-前文「二分查找」有详细讲解,这里只写最简单的二分算法,旨在突出它的双指针特性:
+我在另一篇文章 [二分查找框架详解](https://labuladong.github.io/article/fname.html?fname=二分查找详解) 中有详细探讨二分搜索代码的细节问题,这里只写最简单的二分算法,旨在突出它的双指针特性:
```java
int binarySearch(int[] nums, int target) {
- int left = 0;
- int right = nums.length - 1;
+ // 一左一右两个指针相向而行
+ int left = 0, right = nums.length - 1;
while(left <= right) {
int mid = (right + left) / 2;
if(nums[mid] == target)
@@ -175,14 +253,15 @@ int binarySearch(int[] nums, int target) {
**2、两数之和**
-直接看一道 LeetCode 题目吧:
+看下力扣第 167 题「两数之和 II」:
-
+
-只要数组有序,就应该想到双指针技巧。这道题的解法有点类似二分查找,通过调节 left 和 right 可以调整 sum 的大小:
+只要数组有序,就应该想到双指针技巧。这道题的解法有点类似二分查找,通过调节 `left` 和 `right` 就可以调整 `sum` 的大小:
```java
int[] twoSum(int[] nums, int target) {
+ // 一左一右两个指针相向而行
int left = 0, right = nums.length - 1;
while (left < right) {
int sum = nums[left] + nums[right];
@@ -199,39 +278,120 @@ int[] twoSum(int[] nums, int target) {
}
```
+我在另一篇文章 [一个函数秒杀所有 nSum 问题](https://labuladong.github.io/article/fname.html?fname=nSum) 中也运用类似的左右指针技巧给出了 `nSum` 问题的一种通用思路,这里就不做赘述了。
+
**3、反转数组**
+一般编程语言都会提供 `reverse` 函数,其实这个函数的原理非常简单,力扣第 344 题「反转字符串」就是类似的需求,让你反转一个 `char[]` 类型的字符数组,我们直接看代码吧:
+
```java
-void reverse(int[] nums) {
- int left = 0;
- int right = nums.length - 1;
+void reverseString(char[] s) {
+ // 一左一右两个指针相向而行
+ int left = 0, right = s.length - 1;
while (left < right) {
- // swap(nums[left], nums[right])
- int temp = nums[left];
- nums[left] = nums[right];
- nums[right] = temp;
- left++; right--;
+ // 交换 s[left] 和 s[right]
+ char temp = s[left];
+ s[left] = s[right];
+ s[right] = temp;
+ left++;
+ right--;
}
}
```
-**4、滑动窗口算法**
+**4、回文串判断**
+
+首先明确一下,回文串就是正着读和反着读都一样的字符串。
+
+比如说字符串 `aba` 和 `abba` 都是回文串,因为它们对称,反过来还是和本身一样;反之,字符串 `abac` 就不是回文串。
+
+现在你应该能感觉到回文串问题和左右指针肯定有密切的联系,比如让你判断一个字符串是不是回文串,你可以写出下面这段代码:
+
+```java
+boolean isPalindrome(String s) {
+ // 一左一右两个指针相向而行
+ int left = 0, right = s.length() - 1;
+ while (left < right) {
+ if (s.charAt(left) != s.charAt(right)) {
+ return false;
+ }
+ left++;
+ right--;
+ }
+ return true;
+}
+```
+
+那接下来我提升一点难度,给你一个字符串,让你用双指针技巧从中找出最长的回文串,你会做吗?
+
+这就是力扣第 5 题「最长回文子串」:
+
+
+
+函数签名如下:
+
+```java
+String longestPalindrome(String s);
+```
+
+找回文串的难点在于,回文串的的长度可能是奇数也可能是偶数,解决该问题的核心是**从中心向两端扩散的双指针技巧**。
+
+如果回文串的长度为奇数,则它有一个中心字符;如果回文串的长度为偶数,则可以认为它有两个中心字符。所以我们可以先实现这样一个函数:
+
+```java
+// 在 s 中寻找以 s[l] 和 s[r] 为中心的最长回文串
+String palindrome(String s, int l, int r) {
+ // 防止索引越界
+ while (l >= 0 && r < s.length()
+ && s.charAt(l) == s.charAt(r)) {
+ // 双指针,向两边展开
+ l--; r++;
+ }
+ // 返回以 s[l] 和 s[r] 为中心的最长回文串
+ return s.substring(l + 1, r);
+}
+```
-这也许是双指针技巧的最高境界了,如果掌握了此算法,可以解决一大类子字符串匹配的问题,不过「滑动窗口」稍微比上述的这些算法复杂些。
+这样,如果输入相同的 `l` 和 `r`,就相当于寻找长度为奇数的回文串,如果输入相邻的 `l` 和 `r`,则相当于寻找长度为偶数的回文串。
-幸运的是,这类算法是有框架模板的,而且[这篇文章](https://labuladong.gitee.io/algo/)就讲解了「滑动窗口」算法模板,帮大家秒杀几道 LeetCode 子串匹配的问题。
+那么回到最长回文串的问题,解法的大致思路就是:
+```python
+for 0 <= i < len(s):
+ 找到以 s[i] 为中心的回文串
+ 找到以 s[i] 和 s[i+1] 为中心的回文串
+ 更新答案
+```
+翻译成代码,就可以解决最长回文子串这个问题:
+
+```java
+String longestPalindrome(String s) {
+ String res = "";
+ for (int i = 0; i < s.length(); i++) {
+ // 以 s[i] 为中心的最长回文子串
+ String s1 = palindrome(s, i, i);
+ // 以 s[i] 和 s[i+1] 为中心的最长回文子串
+ String s2 = palindrome(s, i, i + 1);
+ // res = longest(res, s1, s2)
+ res = res.length() > s1.length() ? res : s1;
+ res = res.length() > s2.length() ? res : s2;
+ }
+ return res;
+}
+```
+
+你应该能发现最长回文子串使用的左右指针和之前题目的左右指针有一些不同:之前的左右指针都是从两端向中间相向而行,而回文子串问题则是让左右指针从中心向两端扩展。不过这种情况也就回文串这类问题会遇到,所以我也把它归为左右指针了。
+
+到这里,数组相关的双指针技巧就全部讲完了,这些技巧的更多扩展延伸见 [更多双指针经典高频题](https://appktavsiei5995.pc.xiaoe-tech.com/detail/i_62a1dd68e4b09dda1273a5f9/1)。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[141.环形链表](https://leetcode-cn.com/problems/linked-list-cycle)
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\233\236\346\272\257\347\256\227\346\263\225\350\257\246\350\247\243\344\277\256\350\256\242\347\211\210.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\233\236\346\272\257\347\256\227\346\263\225\350\257\246\350\247\243\344\277\256\350\256\242\347\211\210.md"
index 65392798477b87e07e42491d75c79f48197a45b0..370d288b4c6570eadbef8975870c2fb9b1fa8d87 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\233\236\346\272\257\347\256\227\346\263\225\350\257\246\350\247\243\344\277\256\350\256\242\347\211\210.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\233\236\346\272\257\347\256\227\346\263\225\350\257\246\350\247\243\344\277\256\350\256\242\347\211\210.md"
@@ -1,30 +1,43 @@
# 回溯算法详解
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[46.全排列](https://leetcode-cn.com/problems/permutations)
-[51.N皇后](https://leetcode-cn.com/problems/n-queens)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [46. Permutations](https://leetcode.com/problems/permutations/) | [46. 全排列](https://leetcode.cn/problems/permutations/) | 🟠
+| [51. N-Queens](https://leetcode.com/problems/n-queens/) | [51. N 皇后](https://leetcode.cn/problems/n-queens/) | 🔴
+| - | [剑指 Offer II 083. 没有重复元素集合的全排列](https://leetcode.cn/problems/VvJkup/) | 🟠
**-----------**
-本文有视频版:[回溯算法框架套路详解](https://www.bilibili.com/video/BV1P5411N7Xc)
+> 本文有视频版:[回溯算法框架套路详解](https://www.bilibili.com/video/BV1P5411N7Xc/)
这篇文章是很久之前的一篇 [回溯算法详解](https://mp.weixin.qq.com/s/trILKSiN9EoS58pXmvUtUQ) 的进阶版,之前那篇不够清楚,就不必看了,看这篇就行。把框架给你讲清楚,你会发现回溯算法问题都是一个套路。
-废话不多说,直接上回溯算法框架。**解决一个回溯问题,实际上就是一个决策树的遍历过程**。你只需要思考 3 个问题:
+本文解决几个问题:
+
+回溯算法是什么?解决回溯算法相关的问题有什么技巧?如何学习回溯算法?回溯算法代码是否有规律可循?
+
+其实回溯算法和我们常说的 DFS 算法非常类似,本质上就是一种暴力穷举算法。回溯算法和 DFS 算法的细微差别是:**回溯算法是在遍历「树枝」,DFS 算法是在遍历「节点」**,本文就是简单提一下,等你看到后文 [图论算法基础](https://labuladong.github.io/article/fname.html?fname=图) 时就能深刻理解这句话的含义了。
+
+废话不多说,直接上回溯算法框架,解决一个回溯问题,实际上就是一个决策树的遍历过程,站在回溯树的一个节点上,你只需要思考 3 个问题:
1、路径:也就是已经做出的选择。
@@ -55,54 +68,61 @@ def backtrack(路径, 选择列表):
### 一、全排列问题
-我们在高中的时候就做过排列组合的数学题,我们也知道 `n` 个不重复的数,全排列共有 n! 个。
+力扣第 46 题「全排列」就是给你输入一个数组 `nums`,让你返回这些数字的全排列。
+
+> **PS:我们这次讨论的全排列问题不包含重复的数字,包含重复数字的扩展场景我在后文 [回溯算法秒杀排列组合子集的九种题型](https://labuladong.github.io/article/fname.html?fname=子集排列组合) 中讲解**。
-PS:**为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字**。
+我们在高中的时候就做过排列组合的数学题,我们也知道 `n` 个不重复的数,全排列共有 `n!` 个。那么我们当时是怎么穷举全排列的呢?
-那么我们当时是怎么穷举全排列的呢?比方说给三个数 `[1,2,3]`,你肯定不会无规律地乱穷举,一般是这样:
+比方说给三个数 `[1,2,3]`,你肯定不会无规律地乱穷举,一般是这样:
先固定第一位为 1,然后第二位可以是 2,那么第三位只能是 3;然后可以把第二位变成 3,第三位就只能是 2 了;然后就只能变化第一位,变成 2,然后再穷举后两位……
其实这就是回溯算法,我们高中无师自通就会用,或者有的同学直接画出如下这棵回溯树:
-
+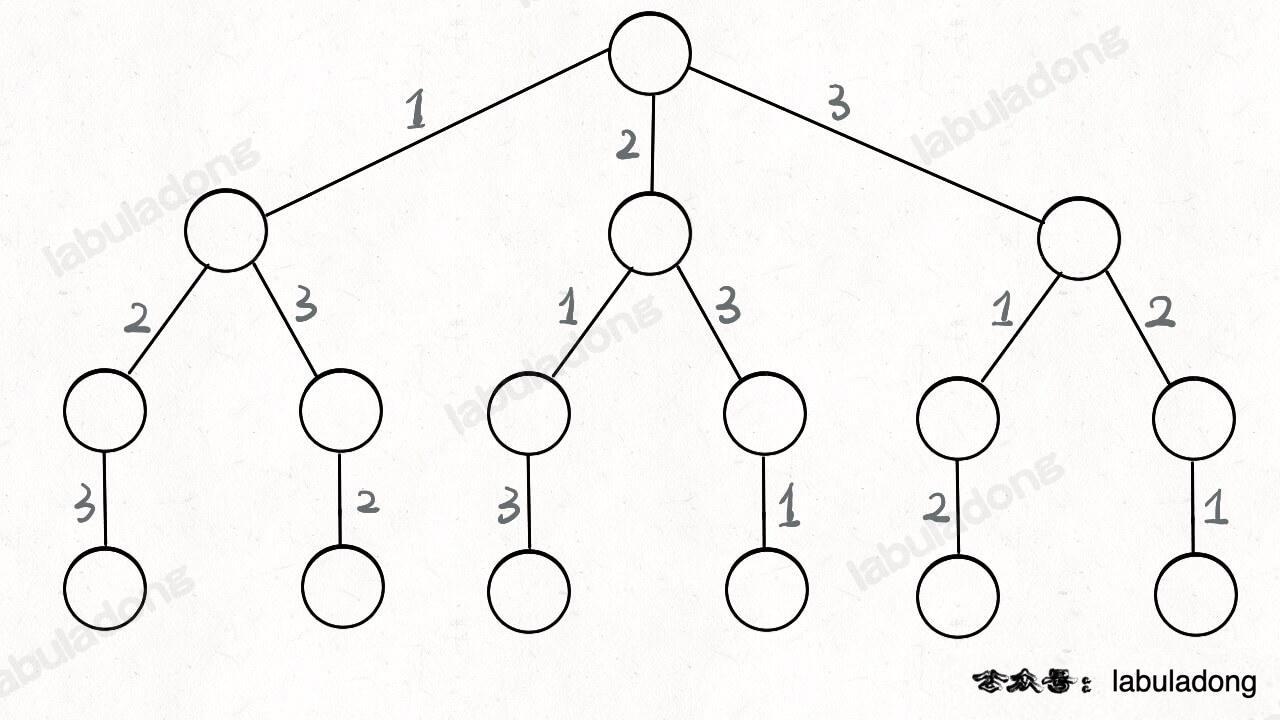
只要从根遍历这棵树,记录路径上的数字,其实就是所有的全排列。**我们不妨把这棵树称为回溯算法的「决策树」**。
**为啥说这是决策树呢,因为你在每个节点上其实都在做决策**。比如说你站在下图的红色节点上:
-
+
你现在就在做决策,可以选择 1 那条树枝,也可以选择 3 那条树枝。为啥只能在 1 和 3 之中选择呢?因为 2 这个树枝在你身后,这个选择你之前做过了,而全排列是不允许重复使用数字的。
-**现在可以解答开头的几个名词:`[2]` 就是「路径」,记录你已经做过的选择;`[1,3]` 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候**。
+**现在可以解答开头的几个名词:`[2]` 就是「路径」,记录你已经做过的选择;`[1,3]` 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层叶子节点,这里也就是选择列表为空的时候**。
-如果明白了这几个名词,**可以把「路径」和「选择」列表作为决策树上每个节点的属性**,比如下图列出了几个节点的属性:
+如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个蓝色节点的属性:
-
+
-**我们定义的 `backtrack` 函数其实就像一个指针,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其「路径」就是一个全排列**。
+**我们定义的 `backtrack` 函数其实就像一个指针,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层叶子节点,其「路径」就是一个全排列**。
-再进一步,如何遍历一棵树?这个应该不难吧。回忆一下之前「学习数据结构的框架思维」写过,各种搜索问题其实都是树的遍历问题,而多叉树的遍历框架就是这样:
+再进一步,如何遍历一棵树?这个应该不难吧。回忆一下之前 [学习数据结构的框架思维](https://labuladong.github.io/article/fname.html?fname=学习数据结构和算法的高效方法) 写过,各种搜索问题其实都是树的遍历问题,而多叉树的遍历框架就是这样:
```java
void traverse(TreeNode root) {
- for (TreeNode child : root.children)
- // 前序遍历需要的操作
+ for (TreeNode child : root.childern) {
+ // 前序位置需要的操作
traverse(child);
- // 后序遍历需要的操作
+ // 后序位置需要的操作
+ }
}
```
+> PS:细心的读者肯定会疑问:多叉树 DFS 遍历框架的前序位置和后序位置应该在 for 循环外面,并不应该是在 for 循环里面呀?为什么在回溯算法中跑到 for 循环里面了?
+>
+> 是的,DFS 算法的前序和后序位置应该在 for 循环外面,不过回溯算法和 DFS 算法略有不同,后文 [图论算法基础](https://labuladong.github.io/article/fname.html?fname=图) 会详细对比,这里可以暂且忽略这个问题。
+
而所谓的前序遍历和后序遍历,他们只是两个很有用的时间点,我给你画张图你就明白了:
-
+
**前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行**。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
-
+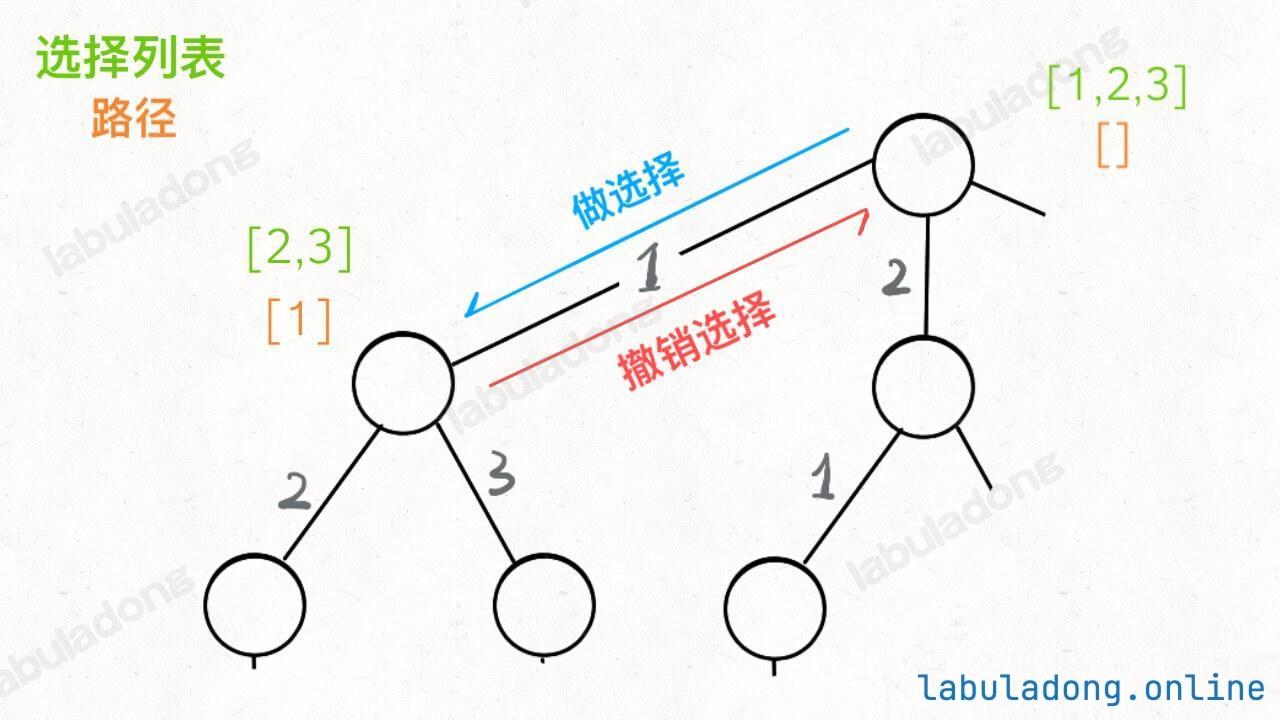
现在,你是否理解了回溯算法的这段核心框架?
@@ -128,14 +148,17 @@ List> res = new LinkedList<>();
List> permute(int[] nums) {
// 记录「路径」
LinkedList track = new LinkedList<>();
- backtrack(nums, track);
+ // 「路径」中的元素会被标记为 true,避免重复使用
+ boolean[] used = new boolean[nums.length];
+
+ backtrack(nums, track, used);
return res;
}
// 路径:记录在 track 中
-// 选择列表:nums 中不存在于 track 的那些元素
+// 选择列表:nums 中不存在于 track 的那些元素(used[i] 为 false)
// 结束条件:nums 中的元素全都在 track 中出现
-void backtrack(int[] nums, LinkedList track) {
+void backtrack(int[] nums, LinkedList track, boolean[] used) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
@@ -144,23 +167,27 @@ void backtrack(int[] nums, LinkedList track) {
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
- if (track.contains(nums[i]))
+ if (used[i]) {
+ // nums[i] 已经在 track 中,跳过
continue;
+ }
// 做选择
track.add(nums[i]);
+ used[i] = true;
// 进入下一层决策树
- backtrack(nums, track);
+ backtrack(nums, track, used);
// 取消选择
track.removeLast();
+ used[i] = false;
}
}
```
-我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 `nums` 和 `track` 推导出当前的选择列表:
+我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 `used` 数组排除已经存在 `track` 中的元素,从而推导出当前的选择列表:
-
+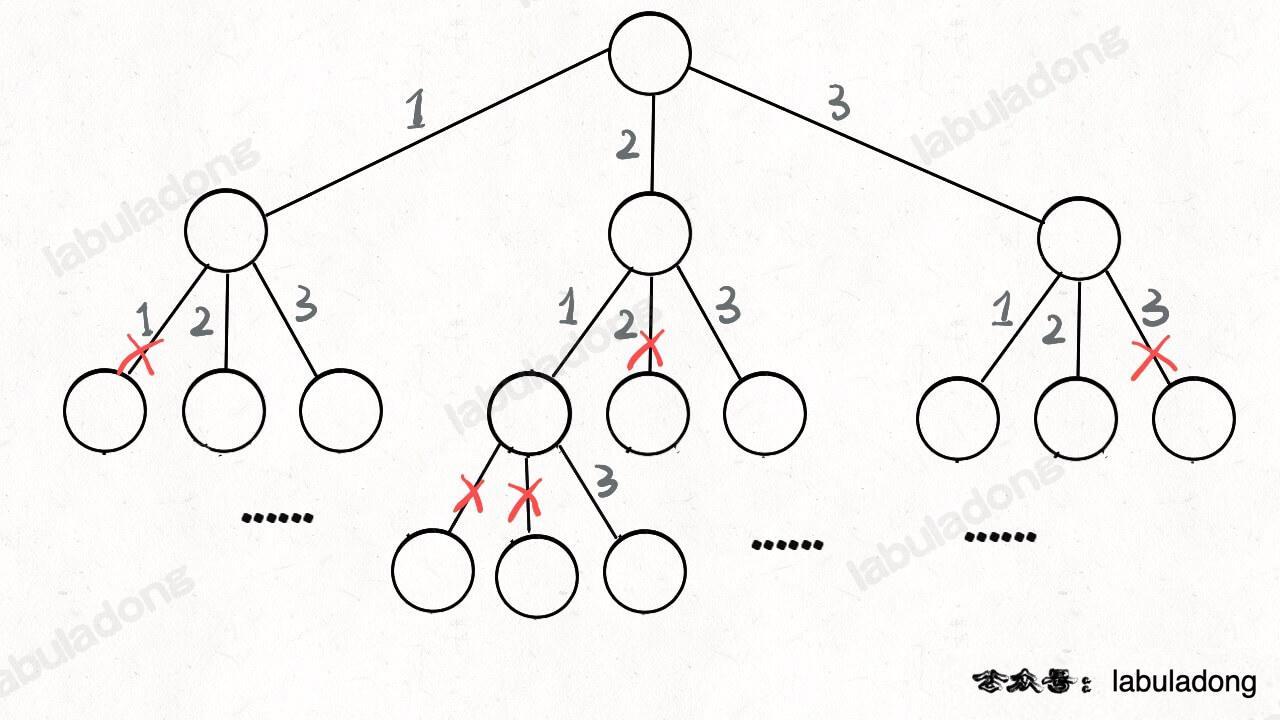
-至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是很高效,应为对链表使用 `contains` 方法需要 O(N) 的时间复杂度。有更好的方法通过交换元素达到目的,但是难理解一些,这里就不写了,有兴趣可以自行搜索一下。
+至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是最高效的,你可能看到有的解法连 `used` 数组都不使用,通过交换元素达到目的。但是那种解法稍微难理解一些,这里就不写了,有兴趣可以自行搜索一下。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。**这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高**。
@@ -168,20 +195,21 @@ void backtrack(int[] nums, LinkedList track) {
### 二、N 皇后问题
-这个问题很经典了,简单解释一下:给你一个 N×N 的棋盘,让你放置 N 个皇后,使得它们不能互相攻击。
+力扣第 51 题「N 皇后」就是这个经典问题,简单解释一下:给你一个 `N×N` 的棋盘,让你放置 `N` 个皇后,使得它们不能互相攻击。
-PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
+> PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
-直接套用框架:
+因为 C++ 代码对字符串的操作方便一些,所以这道题我用 C++ 来写解法,直接套用回溯算法框架:
```cpp
vector> res;
/* 输入棋盘边长 n,返回所有合法的放置 */
vector> solveNQueens(int n) {
- // '.' 表示空,'Q' 表示皇后,初始化空棋盘。
+ // vector 代表一个棋盘
+ // '.' 表示空,'Q' 表示皇后,初始化空棋盘
vector board(n, string(n, '.'));
backtrack(board, 0);
return res;
@@ -200,8 +228,9 @@ void backtrack(vector& board, int row) {
int n = board[row].size();
for (int col = 0; col < n; col++) {
// 排除不合法选择
- if (!isValid(board, row, col))
+ if (!isValid(board, row, col)) {
continue;
+ }
// 做选择
board[row][col] = 'Q';
// 进入下一行决策
@@ -219,7 +248,7 @@ void backtrack(vector& board, int row) {
bool isValid(vector& board, int row, int col) {
int n = board.size();
// 检查列是否有皇后互相冲突
- for (int i = 0; i < n; i++) {
+ for (int i = 0; i <= row; i++) {
if (board[i][col] == 'Q')
return false;
}
@@ -239,17 +268,25 @@ bool isValid(vector& board, int row, int col) {
}
```
+> PS:肯定有读者问,按照 N 皇后问题的描述,我们为什么不检查左下角,右下角和下方的格子,只检查了左上角,右上角和上方的格子呢?
+>
+> 因为皇后是一行一行从上往下放的,所以左下方,右下方和正下方不用检查(还没放皇后);因为一行只会放一个皇后,所以每行不用检查。也就是最后只用检查上面,左上,右上三个方向。
+
函数 `backtrack` 依然像个在决策树上游走的指针,通过 `row` 和 `col` 就可以表示函数遍历到的位置,通过 `isValid` 函数可以将不符合条件的情况剪枝:
-
+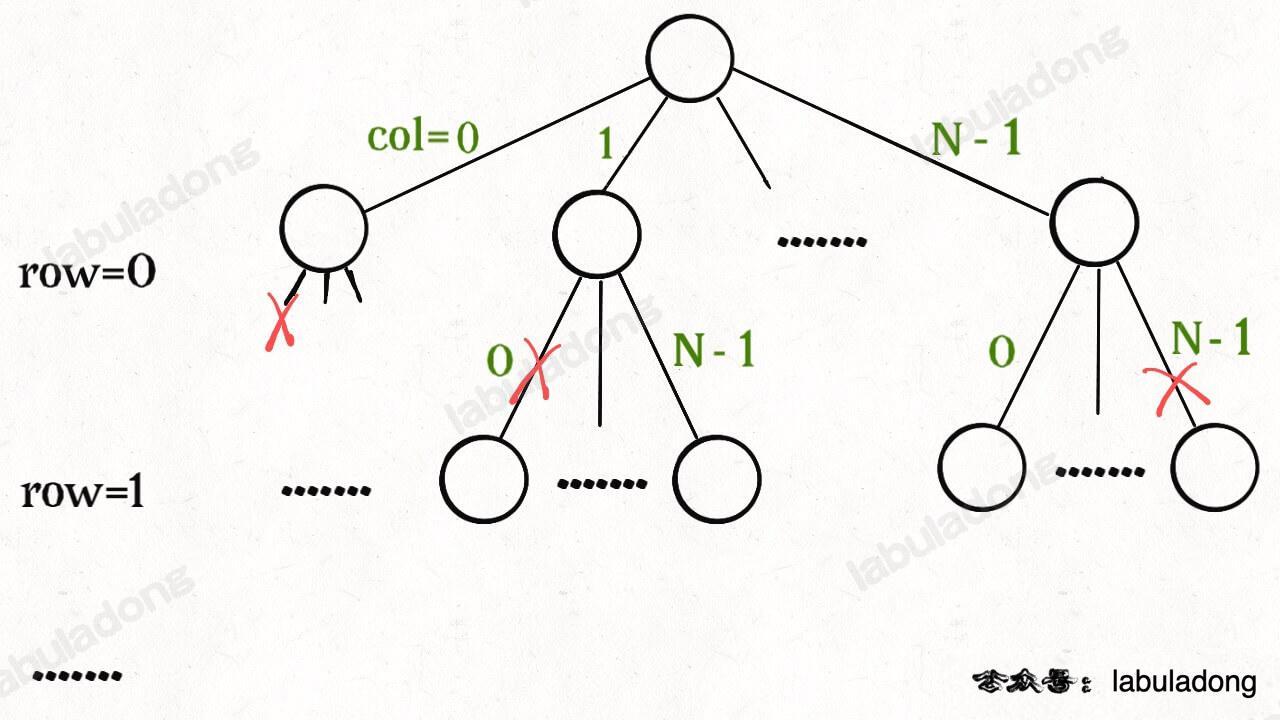
如果直接给你这么一大段解法代码,可能是懵逼的。但是现在明白了回溯算法的框架套路,还有啥难理解的呢?无非是改改做选择的方式,排除不合法选择的方式而已,只要框架存于心,你面对的只剩下小问题了。
当 `N = 8` 时,就是八皇后问题,数学大佬高斯穷尽一生都没有数清楚八皇后问题到底有几种可能的放置方法,但是我们的算法只需要一秒就可以算出来所有可能的结果。
-不过真的不怪高斯。这个问题的复杂度确实非常高,看看我们的决策树,虽然有 `isValid` 函数剪枝,但是最坏时间复杂度仍然是 O(N^(N+1)),而且无法优化。如果 `N = 10` 的时候,计算就已经很耗时了。
+不过真的不怪高斯,这个问题的复杂度确实非常高,粗略估算一下:
-**有的时候,我们并不想得到所有合法的答案,只想要一个答案,怎么办呢**?比如解数独的算法,找所有解法复杂度太高,只要找到一种解法就可以。
+`N` 行棋盘中,第一行有 `N` 个位置可能可以放皇后,第二行有 `N - 1` 个位置,第三行有 `N - 2` 个位置,以此类推,再叠加每次放皇后之前 `isValid` 函数所需的 O(N) 复杂度,所以总的时间复杂度上界是 O(N! * N),而且没有什么明显的冗余计算可以优化效率。你可以试试 `N = 10` 的时候,计算就已经很耗时了。
+
+当然,因为有 `isValid` 函数剪枝,并不会真的在每个位置都尝试放皇后,所以实际的执行效率会高一些。但正如前文 [算法时空复杂度分析实用指南](https://labuladong.github.io/article/fname.html?fname=时间复杂度) 所说,这个时间复杂度作为上界是没问题的。
+
+**有的时候,如果我们并不想得到所有合法的答案,只想要一个答案,怎么办呢**?比如解数独的算法,找所有解法复杂度太高,只要找到一种解法就可以。
其实特别简单,只要稍微修改一下回溯算法的代码即可:
@@ -294,19 +331,15 @@ def backtrack(...):
其实想想看,回溯算法和动态规划是不是有点像呢?我们在动态规划系列文章中多次强调,动态规划的三个需要明确的点就是「状态」「选择」和「base case」,是不是就对应着走过的「路径」,当前的「选择列表」和「结束条件」?
-某种程度上说,动态规划的暴力求解阶段就是回溯算法。只是有的问题具有重叠子问题性质,可以用 dp table 或者备忘录优化,将递归树大幅剪枝,这就变成了动态规划。而今天的两个问题,都没有重叠子问题,也就是回溯算法问题了,复杂度非常高是不可避免的。
-
-
+动态规划和回溯算法底层都把问题抽象成了树的结构,但这两种算法在思路上是完全不同的。在 [东哥带你刷二叉树(纲领篇)](https://labuladong.github.io/article/fname.html?fname=二叉树总结) 你将看到动态规划和回溯算法更深层次的区别和联系。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[46.全排列](https://leetcode-cn.com/problems/permutations)
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225.md"
index cf60092a82310e8cf082043509ea554298207708..0ecb325ccc90faecff3998aebe77494db719ff19 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\255\227\347\254\246\344\270\262\344\271\230\346\263\225.md"
@@ -1,32 +1,41 @@
# 字符串乘法
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[43.字符串相乘](https://leetcode-cn.com/problems/multiply-strings)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [43. Multiply Strings](https://leetcode.com/problems/multiply-strings/) | [43. 字符串相乘](https://leetcode.cn/problems/multiply-strings/) | 🟠
**-----------**
对于比较小的数字,做运算可以直接使用编程语言提供的运算符,但是如果相乘的两个因数非常大,语言提供的数据类型可能就会溢出。一种替代方案就是,运算数以字符串的形式输入,然后模仿我们小学学习的乘法算术过程计算出结果,并且也用字符串表示。
-
+看下力扣第 43 题「字符串相乘」:
+
+
需要注意的是,`num1` 和 `num2` 可以非常长,所以不可以把他们直接转成整型然后运算,唯一的思路就是模仿我们手算乘法。
比如说我们手算 `123 × 45`,应该会这样计算:
-
+
计算 `123 × 5`,再计算 `123 × 4`,最后错一位相加。这个流程恐怕小学生都可以熟练完成,但是你是否能**把这个运算过程进一步机械化**,写成一套算法指令让没有任何智商的计算机来执行呢?
@@ -34,21 +43,21 @@
首先,我们这种手算方式还是太「高级」了,我们要再「低级」一点,`123 × 5` 和 `123 × 4` 的过程还可以进一步分解,最后再相加:
-
+
现在 `123` 并不大,如果是个很大的数字的话,是无法直接计算乘积的。我们可以用一个数组在底下接收相加结果:
-
+
-整个计算过程大概是这样,**有两个指针 `i,j` 在 `num1` 和 `num2` 上游走,计算乘积,同时将乘积叠加到 `res` 的正确位置**:
+整个计算过程大概是这样,**有两个指针 `i,j` 在 `num1` 和 `num2` 上游走,计算乘积,同时将乘积叠加到 `res` 的正确位置**,如下 GIF 图所示:
-
+
现在还有一个关键问题,如何将乘积叠加到 `res` 的正确位置,或者说,如何通过 `i,j` 计算 `res` 的对应索引呢?
其实,细心观察之后就发现,**`num1[i]` 和 `num2[j]` 的乘积对应的就是 `res[i+j]` 和 `res[i+j+1]` 这两个位置**。
-
+
明白了这一点,就可以用代码模仿出这个计算过程了:
@@ -91,13 +100,10 @@ string multiply(string num1, string num2) {
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
[43.字符串相乘](https://leetcode-cn.com/problems/multiply-strings)
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\270\270\347\224\250\347\232\204\344\275\215\346\223\215\344\275\234.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\270\270\347\224\250\347\232\204\344\275\215\346\223\215\344\275\234.md"
index 5a44b9776a2f4988ea780d88d418932efbe57656..9b1efa09881fbbbb3d2d0c91e00f65f6a5fd812e 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\270\270\347\224\250\347\232\204\344\275\215\346\223\215\344\275\234.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\345\270\270\347\224\250\347\232\204\344\275\215\346\223\215\344\275\234.md"
@@ -1,26 +1,35 @@
-# 常用的位操作
+# 常用的位运算技巧
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[191.位1的个数](https://leetcode-cn.com/problems/number-of-1-bits)
-[231.2的幂](https://leetcode-cn.com/problems/power-of-two/)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [136. Single Number](https://leetcode.com/problems/single-number/) | [136. 只出现一次的数字](https://leetcode.cn/problems/single-number/) | 🟢
+| [191. Number of 1 Bits](https://leetcode.com/problems/number-of-1-bits/) | [191. 位1的个数](https://leetcode.cn/problems/number-of-1-bits/) | 🟢
+| [231. Power of Two](https://leetcode.com/problems/power-of-two/) | [231. 2 的幂](https://leetcode.cn/problems/power-of-two/) | 🟢
+| [268. Missing Number](https://leetcode.com/problems/missing-number/) | [268. 丢失的数字](https://leetcode.cn/problems/missing-number/) | 🟢
+| - | [剑指 Offer 15. 二进制中1的个数](https://leetcode.cn/problems/er-jin-zhi-zhong-1de-ge-shu-lcof/) | 🟢
**-----------**
-本文分两部分,第一部分列举几个有趣的位操作,第二部分讲解算法中常用的 `n & (n - 1)` 操作,顺便把用到这个技巧的算法题列出来讲解一下。因为位操作很简单,所以假设读者已经了解与、或、异或这三种基本操作。
+本文分两部分,第一部分列举几个有趣的位操作,第二部分讲解算法题中常用的位运算操作。因为位操作很简单,所以假设读者已经了解与、或、异或这三种基本操作。
位操作(Bit Manipulation)可以玩出很多奇技淫巧,但是这些技巧大部分都过于晦涩,没必要深究,读者只要记住一些有用的操作即可。
@@ -28,42 +37,42 @@
1. **利用或操作 `|` 和空格将英文字符转换为小写**
-```c
+```java
('a' | ' ') = 'a'
('A' | ' ') = 'a'
```
2. **利用与操作 `&` 和下划线将英文字符转换为大写**
-```c
+```java
('b' & '_') = 'B'
('B' & '_') = 'B'
```
3. **利用异或操作 `^` 和空格进行英文字符大小写互换**
-```c
+```java
('d' ^ ' ') = 'D'
('D' ^ ' ') = 'd'
```
-以上操作能够产生奇特效果的原因在于 ASCII 编码。字符其实就是数字,恰巧这些字符对应的数字通过位运算就能得到正确的结果,有兴趣的读者可以查 ASCII 码表自己算算,本文就不展开讲了。
+以上操作能够产生奇特效果的原因在于 ASCII 编码。ASCII 字符其实就是数字,恰巧这些字符对应的数字通过位运算就能得到正确的结果,有兴趣的读者可以查 ASCII 码表自己算算,本文就不展开讲了。
4. **判断两个数是否异号**
-```cpp
+```java
int x = -1, y = 2;
-bool f = ((x ^ y) < 0); // true
+boolean f = ((x ^ y) < 0); // true
int x = 3, y = 2;
-bool f = ((x ^ y) < 0); // false
+boolean f = ((x ^ y) < 0); // false
```
这个技巧还是很实用的,利用的是补码编码的符号位。如果不用位运算来判断是否异号,需要使用 if else 分支,还挺麻烦的。读者可能想利用乘积或者商来判断两个数是否异号,但是这种处理方式可能造成溢出,从而出现错误。
5. **不用临时变量交换两个数**
-```c
+```java
int a = 1, b = 2;
a ^= b;
b ^= a;
@@ -73,7 +82,7 @@ a ^= b;
6. **加一**
-```c
+```java
int n = 1;
n = -~n;
// 现在 n = 2
@@ -81,32 +90,34 @@ n = -~n;
7. **减一**
-```c
+```java
int n = 2;
n = ~-n;
// 现在 n = 1
```
-PS:上面这三个操作就纯属装逼用的,没啥实际用处,大家了解了解乐呵一下就行。
+> PS:上面这三个操作就纯属装逼用的,没啥实际用处,大家了解了解乐呵一下就行。
-### 二、算法常用操作
+### 二、`n & (n-1)` 的运用
- `n&(n-1)` 这个操作是算法中常见的,作用是消除数字 `n` 的二进制表示中的最后一个 1。
+**`n & (n-1)` 这个操作是算法中常见的,作用是消除数字 `n` 的二进制表示中的最后一个 1**。
看个图就很容易理解了:
-
+
其核心逻辑就是,`n - 1` 一定可以消除最后一个 1,同时把其后的 0 都变成 1,这样再和 `n` 做一次 `&` 运算,就可以仅仅把最后一个 1 变成 0 了。
-1. **计算汉明权重(Hamming Weight)**
+**1、计算汉明权重(Hamming Weight)**
-
+这是力扣第 191 题「位 1 的个数」:
-就是让你返回 n 的二进制表示中有几个 1。因为 n & (n - 1) 可以消除最后一个 1,所以可以用一个循环不停地消除 1 同时计数,直到 n 变成 0 为止。
+
-```cpp
-int hammingWeight(uint32_t n) {
+就是让你返回 `n` 的二进制表示中有几个 1。因为 `n & (n - 1)` 可以消除最后一个 1,所以可以用一个循环不停地消除 1 同时计数,直到 `n` 变成 0 为止。
+
+```java
+int hammingWeight(int n) {
int res = 0;
while (n != 0) {
n = n & (n - 1);
@@ -116,37 +127,43 @@ int hammingWeight(uint32_t n) {
}
```
-2. **判断一个数是不是 2 的指数**
+**2、判断一个数是不是 2 的指数**
+
+力扣第 231 题「2 的幂」就是这个问题。
一个数如果是 2 的指数,那么它的二进制表示一定只含有一个 1:
-```cpp
+```java
2^0 = 1 = 0b0001
2^1 = 2 = 0b0010
2^2 = 4 = 0b0100
```
-如果使用 `n&(n-1)` 的技巧就很简单了(注意运算符优先级,括号不可以省略):
+如果使用 `n & (n-1)` 的技巧就很简单了(注意运算符优先级,括号不可以省略):
-```cpp
-bool isPowerOfTwo(int n) {
+```java
+boolean isPowerOfTwo(int n) {
if (n <= 0) return false;
return (n & (n - 1)) == 0;
}
```
-**3、查找只出现一次的元素**
-
-
+### 三、`a ^ a = 0` 的运用
-这里就可以运用异或运算的性质:
+异或运算的性质是需要我们牢记的:
一个数和它本身做异或运算结果为 0,即 `a ^ a = 0`;一个数和 0 做异或运算的结果为它本身,即 `a ^ 0 = a`。
+**1、查找只出现一次的元素**
+
+这是力扣第 136 题「只出现一次的数字」:
+
+
+
对于这道题目,我们只要把所有数字进行异或,成对儿的数字就会变成 0,落单的数字和 0 做异或还是它本身,所以最后异或的结果就是只出现一次的元素:
-```cpp
-int singleNumber(vector& nums) {
+```java
+int singleNumber(int[] nums) {
int res = 0;
for (int n : nums) {
res ^= n;
@@ -155,6 +172,76 @@ int singleNumber(vector& nums) {
}
```
+**2、寻找缺失的元素**
+
+这是力扣第 268 题「丢失的数字」:
+
+
+
+给一个长度为 `n` 的数组,其索引应该在 `[0,n)`,但是现在你要装进去 `n + 1` 个元素 `[0,n]`,那么肯定有一个元素装不下嘛,请你找出这个缺失的元素。
+
+这道题不难的,我们应该很容易想到,把这个数组排个序,然后遍历一遍,不就很容易找到缺失的那个元素了吗?
+
+或者说,借助数据结构的特性,用一个 HashSet 把数组里出现的数字都储存下来,再遍历 `[0,n]` 之间的数字,去 HashSet 中查询,也可以很容易查出那个缺失的元素。
+
+排序解法的时间复杂度是 O(NlogN),HashSet 的解法时间复杂度是 O(N),但是还需要 O(N) 的空间复杂度存储 HashSet。
+
+这个问题其实还有一个特别简单的解法:等差数列求和公式。
+
+题目的意思可以这样理解:现在有个等差数列 `0, 1, 2,..., n`,其中少了某一个数字,请你把它找出来。那这个数字不就是 `sum(0,1,..n) - sum(nums)` 嘛?
+
+```java
+int missingNumber(int[] nums) {
+ int n = nums.length;
+ // 虽然题目给的数据范围不大,但严谨起见,用 long 类型防止整型溢出
+ // 求和公式:(首项 + 末项) * 项数 / 2
+ long expect = (0 + n) * (n + 1) / 2;
+ long sum = 0;
+ for (int x : nums) {
+ sum += x;
+ }
+ return (int)(expect - sum);
+}
+```
+
+不过,本文的主题是位运算,我们来讲讲如何利用位运算技巧来解决这道题。
+
+再回顾一下异或运算的性质:一个数和它本身做异或运算结果为 0,一个数和 0 做异或运算还是它本身。
+
+而且异或运算满足交换律和结合律,也就是说:
+
+```java
+2 ^ 3 ^ 2 = 3 ^ (2 ^ 2) = 3 ^ 0 = 3
+```
+
+而这道题索就可以通过这些性质巧妙算出缺失的那个元素,比如说 `nums = [0,3,1,4]`:
+
+
+
+为了容易理解,我们假设先把索引补一位,然后让每个元素和自己相等的索引相对应:
+
+
+
+这样做了之后,就可以发现除了缺失元素之外,所有的索引和元素都组成一对儿了,现在如果把这个落单的索引 2 找出来,也就找到了缺失的那个元素。
+
+如何找这个落单的数字呢,**只要把所有的元素和索引做异或运算,成对儿的数字都会消为 0,只有这个落单的元素会剩下**,也就达到了我们的目的:
+
+```java
+int missingNumber(int[] nums) {
+ int n = nums.length;
+ int res = 0;
+ // 先和新补的索引异或一下
+ res ^= n;
+ // 和其他的元素、索引做异或
+ for (int i = 0; i < n; i++)
+ res ^= i ^ nums[i];
+ return res;
+}
+```
+
+
+
+由于异或运算满足交换律和结合律,所以总是能把成对儿的数字消去,留下缺失的那个元素。
以上便是一些有趣/常用的位操作。其实位操作的技巧很多,有一个叫做 Bit Twiddling Hacks 的外国网站收集了几乎所有位操作的黑科技玩法,感兴趣的读者可以查看:
@@ -162,13 +249,11 @@ http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[191.位1的个数](https://leetcode-cn.com/problems/number-of-1-bits)
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\346\264\227\347\211\214\347\256\227\346\263\225.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\346\264\227\347\211\214\347\256\227\346\263\225.md"
index a9a219395acb7e64eed6ce1a2015a4a020b21e27..e8e44737c0b2201e75c2bdd9a21f7479ea43047f 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\346\264\227\347\211\214\347\256\227\346\263\225.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\346\264\227\347\211\214\347\256\227\346\263\225.md"
@@ -1,20 +1,25 @@
# 洗牌算法
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[384.打乱数组](https://leetcode-cn.com/problems/shuffle-an-array)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [384. Shuffle an Array](https://leetcode.com/problems/shuffle-an-array/) | [384. 打乱数组](https://leetcode.cn/problems/shuffle-an-array/) | 🟠
**-----------**
@@ -62,7 +67,7 @@ void shuffle(int[] arr) {
```
-**分析洗牌算法正确性的准则:产生的结果必须有 n! 种可能,否则就是错误的。**这个很好解释,因为一个长度为 n 的数组的全排列就有 n! 种,也就是说打乱结果总共有 n! 种。算法必须能够反映这个事实,才是正确的。
+**分析洗牌算法正确性的准则:产生的结果必须有 n! 种可能,否则就是错误的**。这个很好解释,因为一个长度为 n 的数组的全排列就有 n! 种,也就是说打乱结果总共有 n! 种。算法必须能够反映这个事实,才是正确的。
我们先用这个准则分析一下**第一种写法**的正确性:
@@ -81,15 +86,15 @@ void shuffle(int[] arr) {
for 循环第一轮迭代时,`i = 0`,`rand` 的取值范围是 `[0, 4]`,有 5 个可能的取值。
-
+
for 循环第二轮迭代时,`i = 1`,`rand` 的取值范围是 `[1, 4]`,有 4 个可能的取值。
-
+
后面以此类推,直到最后一次迭代,`i = 4`,`rand` 的取值范围是 `[4, 4]`,只有 1 个可能的取值。
-
+
可以看到,整个过程产生的所有可能结果有 `n! = 5! = 5*4*3*2*1` 种,所以这个算法是正确的。
@@ -128,13 +133,13 @@ void shuffle(int[] arr) {
### 二、蒙特卡罗方法验证正确性
-洗牌算法,或者说随机乱置算法的**正确性衡量标准是:对于每种可能的结果出现的概率必须相等,也就是说要足够随机。**
+洗牌算法,或者说随机乱置算法的**正确性衡量标准是:对于每种可能的结果出现的概率必须相等,也就是说要足够随机**。
如果不用数学严格证明概率相等,可以用蒙特卡罗方法近似地估计出概率是否相等,结果是否足够随机。
记得高中有道数学题:往一个正方形里面随机打点,这个正方形里紧贴着一个圆,告诉你打点的总数和落在圆里的点的数量,让你计算圆周率。
-
+
这其实就是利用了蒙特卡罗方法:当打的点足够多的时候,点的数量就可以近似代表图形的面积。通过面积公式,由正方形和圆的面积比值是可以很容易推出圆周率的。当然打的点越多,算出的圆周率越准确,充分体现了大力出奇迹的真理。
@@ -142,7 +147,7 @@ void shuffle(int[] arr) {
**第一种思路**,我们把数组 arr 的所有排列组合都列举出来,做成一个直方图(假设 arr = {1,2,3}):
-
+
每次进行洗牌算法后,就把得到的打乱结果对应的频数加一,重复进行 100 万次,如果每种结果出现的总次数差不多,那就说明每种结果出现的概率应该是相等的。写一下这个思路的伪代码:
@@ -187,7 +192,7 @@ for (int feq : count)
print(feq / N + " "); // 频率
```
-
+
这种思路也是可行的,而且避免了阶乘级的空间复杂度,但是多了嵌套 for 循环,时间复杂度高一点。不过由于我们的测试数据量不会有多大,这些问题都可以忽略。
@@ -201,13 +206,11 @@ for (int feq : count)
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[384.打乱数组](https://leetcode-cn.com/problems/shuffle-an-array)
diff --git "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\347\203\247\351\245\274\346\216\222\345\272\217.md" "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\347\203\247\351\245\274\346\216\222\345\272\217.md"
index 8b19a8e07e281ac59df0bfbf0bc98e9b75b76273..333653dc390688fb0b85eb02aaac9d3b5bcbfbf7 100644
--- "a/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\347\203\247\351\245\274\346\216\222\345\272\217.md"
+++ "b/\347\256\227\346\263\225\346\200\235\347\273\264\347\263\273\345\210\227/\347\203\247\351\245\274\346\216\222\345\272\217.md"
@@ -1,38 +1,45 @@
# 烧饼排序
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[969.煎饼排序](https://leetcode-cn.com/problems/pancake-sorting)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [969. Pancake Sorting](https://leetcode.com/problems/pancake-sorting/) | [969. 煎饼排序](https://leetcode.cn/problems/pancake-sorting/) | 🟠
**-----------**
-烧饼排序是个很有意思的实际问题:假设盘子上有 `n` 块**面积大小不一**的烧饼,你如何用一把锅铲进行若干次翻转,让这些烧饼的大小有序(小的在上,大的在下)?
+力扣第 969 题「煎饼排序」是个很有意思的实际问题:假设盘子上有 `n` 块**面积大小不一**的烧饼,你如何用一把锅铲进行若干次翻转,让这些烧饼的大小有序(小的在上,大的在下)?
-
+
设想一下用锅铲翻转一堆烧饼的情景,其实是有一点限制的,我们每次只能将最上面的若干块饼子翻转:
-
+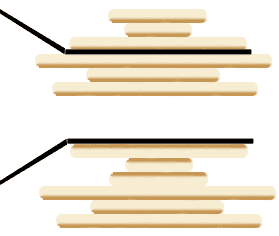
我们的问题是,**如何使用算法得到一个翻转序列,使得烧饼堆变得有序**?
首先,需要把这个问题抽象,用数组来表示烧饼堆:
-
+
-如何解决这个问题呢?其实类似上篇文章 [递归反转链表的一部分](https://labuladong.gitee.io/algo/),这也是需要**递归思想**的。
+如何解决这个问题呢?其实类似上篇文章 [递归反转链表的一部分](https://labuladong.github.io/article/fname.html?fname=递归反转链表的一部分),这也是需要**递归思想**的。
### 一、思路分析
@@ -45,11 +52,11 @@ void sort(int[] cakes, int n);
如果我们找到了前 `n` 个烧饼中最大的那个,然后设法将这个饼子翻转到最底下:
-
+
那么,原问题的规模就可以减小,递归调用 `pancakeSort(A, n-1)` 即可:
-
+
接下来,对于上面的这 `n - 1` 块饼,如何排序呢?还是先从中找到最大的一块饼,然后把这块饼放到底下,再递归调用 `pancakeSort(A, n-1-1)`……
@@ -128,10 +135,12 @@ void reverse(int[] arr, int i, int j) {
显然,这个结果不是最优的(最短的),比如说一堆煎饼 `[3,2,4,1]`,我们的算法得到的翻转序列是 `[3,4,2,3,1,2]`,但是最快捷的翻转方法应该是 `[2,3,4]`:
+```
初始状态 :[3,2,4,1]
翻前 2 个:[2,3,4,1]
翻前 3 个:[4,3,2,1]
翻前 4 个:[1,2,3,4]
+```
如果要求你的算法计算排序烧饼的**最短**操作序列,你该如何计算呢?或者说,解决这种求最优解法的问题,核心思路什么,一定需要使用什么算法技巧呢?
@@ -139,13 +148,11 @@ void reverse(int[] arr, int i, int j) {
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[969.煎饼排序](https://leetcode-cn.com/problems/pancake-sorting)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/LRU\347\256\227\346\263\225.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/LRU\347\256\227\346\263\225.md"
index 55ff22ab0fa9bd9613b7bd49646ce271c51d46f6..377e99ffe53ca15a29aae0f750082ddc4779ba93 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/LRU\347\256\227\346\263\225.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/LRU\347\256\227\346\263\225.md"
@@ -1,24 +1,34 @@
-# 层层拆解,带你手写 LRU 算法
+# LRU 缓存淘汰算法设计
+
+
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[146.LRU缓存机制](https://leetcode-cn.com/problems/lru-cache/)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [146. LRU Cache](https://leetcode.com/problems/lru-cache/) | [146. LRU 缓存](https://leetcode.cn/problems/lru-cache/) | 🟠
+| - | [剑指 Offer II 031. 最近最少使用缓存](https://leetcode.cn/problems/OrIXps/) | 🟠
**-----------**
-LRU 算法就是一种缓存淘汰策略,原理不难,但是面试中写出没有 bug 的算法比较有技巧,需要对数据结构进行层层抽象和拆解,本文 labuladong 就给你写一手漂亮的代码。
+LRU 算法就是一种缓存淘汰策略,原理不难,但是面试中写出没有 bug 的算法比较有技巧,需要对数据结构进行层层抽象和拆解,本文就带你写一手漂亮的代码。
计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么用的缓存,而把有用的数据继续留在缓存里,方便之后继续使用。那么,什么样的数据,我们判定为「有用的」的数据呢?
@@ -26,17 +36,17 @@ LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently
举个简单的例子,安卓手机都可以把软件放到后台运行,比如我先后打开了「设置」「手机管家」「日历」,那么现在他们在后台排列的顺序是这样的:
-
+
但是这时候如果我访问了一下「设置」界面,那么「设置」就会被提前到第一个,变成这样:
-
+
假设我的手机只允许我同时开 3 个应用程序,现在已经满了。那么如果我新开了一个应用「时钟」,就必须关闭一个应用为「时钟」腾出一个位置,关那个呢?
按照 LRU 的策略,就关最底下的「手机管家」,因为那是最久未使用的,然后把新开的应用放到最上面:
-
+
现在你应该理解 LRU(Least Recently Used)策略了。当然还有其他缓存淘汰策略,比如不要按访问的时序来淘汰,而是按访问频率(LFU 策略)来淘汰等等,各有应用场景。本文讲解 LRU 算法策略。
@@ -48,7 +58,7 @@ LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently
注意哦,`get` 和 `put` 方法必须都是 `O(1)` 的时间复杂度,我们举个具体例子来看看 LRU 算法怎么工作。
-```cpp
+```java
/* 缓存容量为 2 */
LRUCache cache = new LRUCache(2);
// 你可以把 cache 理解成一个队列
@@ -97,7 +107,7 @@ cache.put(1, 4);
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
-
+
借助这个结构,我们来逐一分析上面的 3 个条件:
@@ -180,7 +190,7 @@ class DoubleList {
到这里就能回答刚才「为什么必须要用双向链表」的问题了,因为我们需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
-**注意我们实现的双链表 API 只能从尾部插入,也就是说靠尾部的数据是最近使用的,靠头部的数据是最久为使用的**。
+**注意我们实现的双链表 API 只能从尾部插入,也就是说靠尾部的数据是最近使用的,靠头部的数据是最久未使用的**。
有了双向链表的实现,我们只需要在 LRU 算法中把它和哈希表结合起来即可,先搭出代码框架:
@@ -263,7 +273,7 @@ public int get(int key) {
`put` 方法稍微复杂一些,我们先来画个图搞清楚它的逻辑:
-
+
这样我们可以轻松写出 `put` 方法的代码:
@@ -332,17 +342,19 @@ class LRUCache {
}
```
-至此,LRU 算法就没有什么神秘的了,**敬请期待下文:LFU 算法拆解与实现**。
+至此,LRU 算法就没有什么神秘的了。
+
+接下来可阅读:
+
+* [手把手带你实现 LFU 算法](https://labuladong.github.io/article/fname.html?fname=LFU)
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[146.LRU缓存机制](https://leetcode-cn.com/problems/lru-cache/)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/k\344\270\252\344\270\200\347\273\204\345\217\215\350\275\254\351\223\276\350\241\250.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/k\344\270\252\344\270\200\347\273\204\345\217\215\350\275\254\351\223\276\350\241\250.md"
index 407b52b8cdd3952199900955d0f06319cda72212..392b650fc6d13417c23688753be502fa3c3b4167 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/k\344\270\252\344\270\200\347\273\204\345\217\215\350\275\254\351\223\276\350\241\250.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/k\344\270\252\344\270\200\347\273\204\345\217\215\350\275\254\351\223\276\350\241\250.md"
@@ -1,60 +1,67 @@
# 如何k个一组反转链表
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[25.K个一组翻转链表](https://leetcode-cn.com/problems/reverse-nodes-in-k-group)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [25. Reverse Nodes in k-Group](https://leetcode.com/problems/reverse-nodes-in-k-group/) | [25. K 个一组翻转链表](https://leetcode.cn/problems/reverse-nodes-in-k-group/) | 🔴
**-----------**
之前的文章「递归反转链表的一部分」讲了如何递归地反转一部分链表,有读者就问如何迭代地反转链表,这篇文章解决的问题也需要反转链表的函数,我们不妨就用迭代方式来解决。
-本文要解决「K 个一组反转链表」,不难理解:
+本文要解决力扣第 25 题「K 个一组翻转链表」,题目不难理解:
-
+
-这个问题经常在面经中看到,而且 LeetCode 上难度是 Hard,它真的有那么难吗?
+这个问题经常在面经中看到,而且力扣上难度是 Hard,它真的有那么难吗?
对于基本数据结构的算法问题其实都不难,只要结合特点一点点拆解分析,一般都没啥难点。下面我们就来拆解一下这个问题。
### 一、分析问题
-首先,前文[学习数据结构的框架思维](https://labuladong.gitee.io/algo/)提到过,链表是一种兼具递归和迭代性质的数据结构,认真思考一下可以发现**这个问题具有递归性质**。
+首先,前文 [学习数据结构的框架思维](https://labuladong.github.io/article/fname.html?fname=学习数据结构和算法的高效方法) 提到过,链表是一种兼具递归和迭代性质的数据结构,认真思考一下可以发现**这个问题具有递归性质**。
什么叫递归性质?直接上图理解,比如说我们对这个链表调用 `reverseKGroup(head, 2)`,即以 2 个节点为一组反转链表:
-
+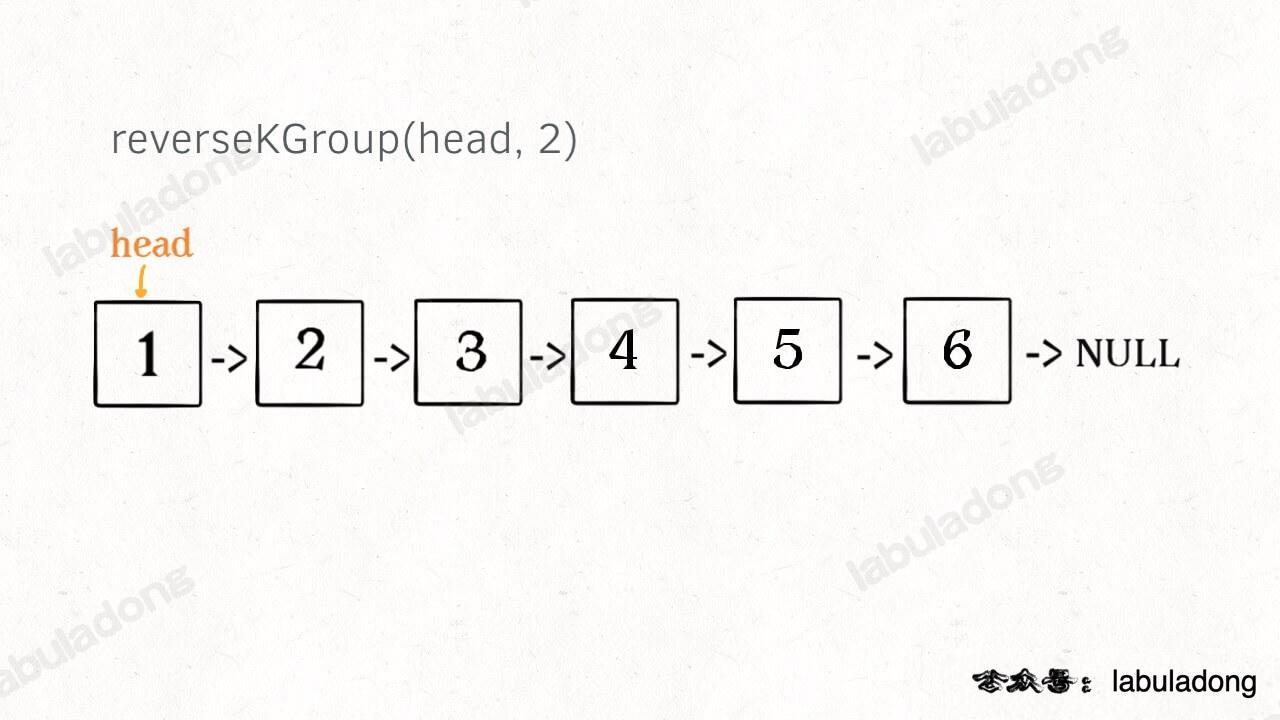
如果我设法把前 2 个节点反转,那么后面的那些节点怎么处理?后面的这些节点也是一条链表,而且规模(长度)比原来这条链表小,这就叫**子问题**。
-
+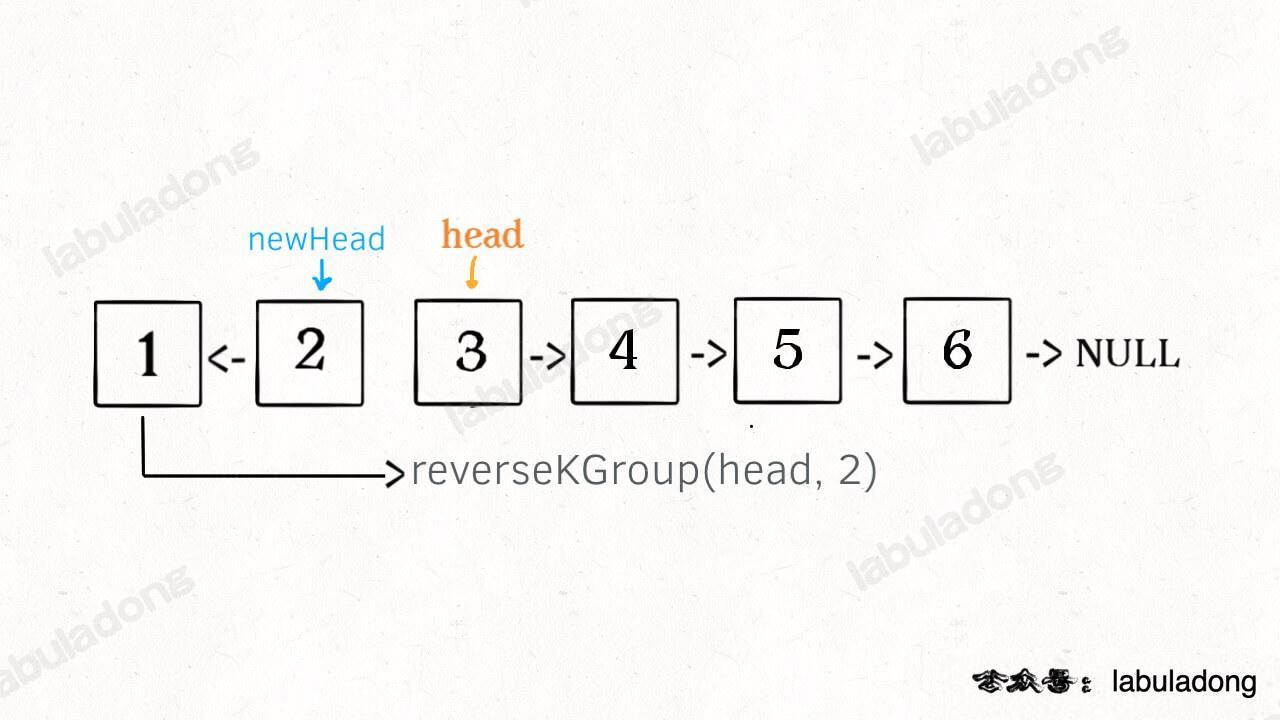
-我们可以直接递归调用 `reverseKGroup(cur, 2)`,因为子问题和原问题的结构完全相同,这就是所谓的递归性质。
+我们可以把原先的 `head` 指针移动到后面这一段链表的开头,然后继续递归调用 `reverseKGroup(head, 2)`,因为子问题(后面这部分链表)和原问题(整条链表)的结构完全相同,这就是所谓的递归性质。
发现了递归性质,就可以得到大致的算法流程:
**1、先反转以 `head` 开头的 `k` 个元素**。
-
+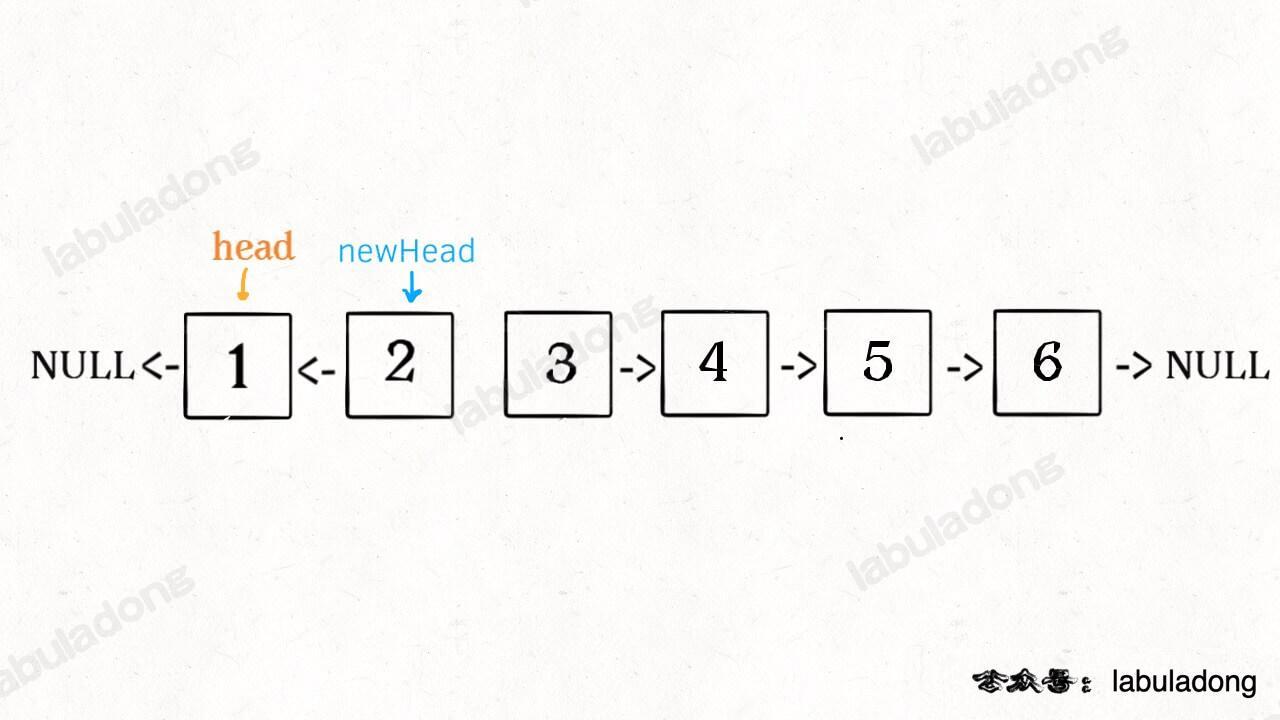
**2、将第 `k + 1` 个元素作为 `head` 递归调用 `reverseKGroup` 函数**。
-
+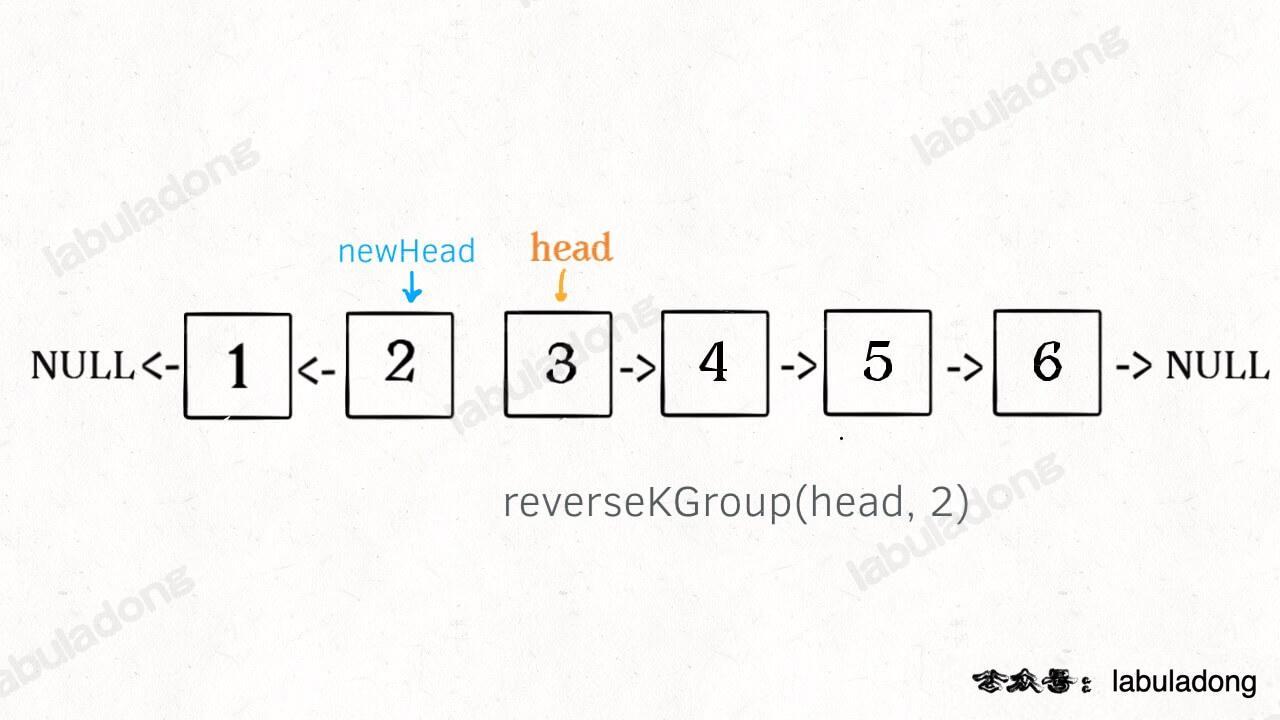
**3、将上述两个过程的结果连接起来**。
-
+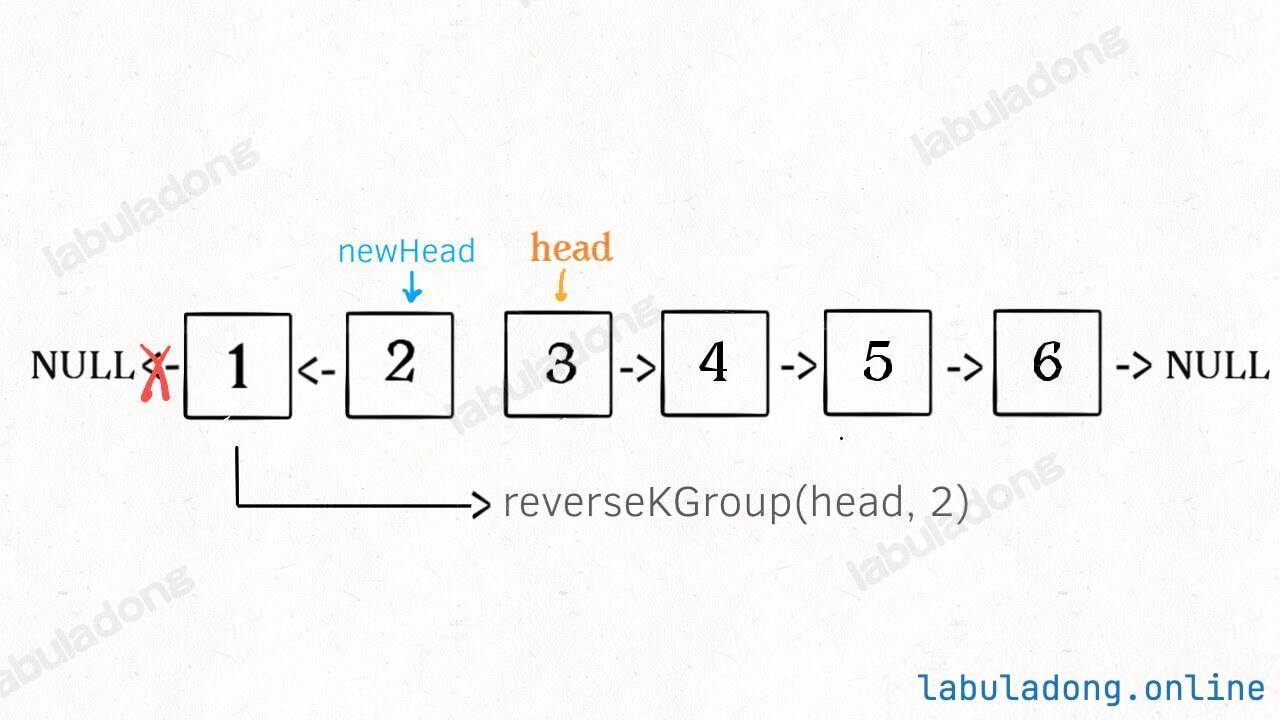
整体思路就是这样了,最后一点值得注意的是,递归函数都有个 base case,对于这个问题是什么呢?
@@ -82,7 +89,9 @@ ListNode reverse(ListNode a) {
}
```
-
+算法执行的过程如下 GIF 所示::
+
+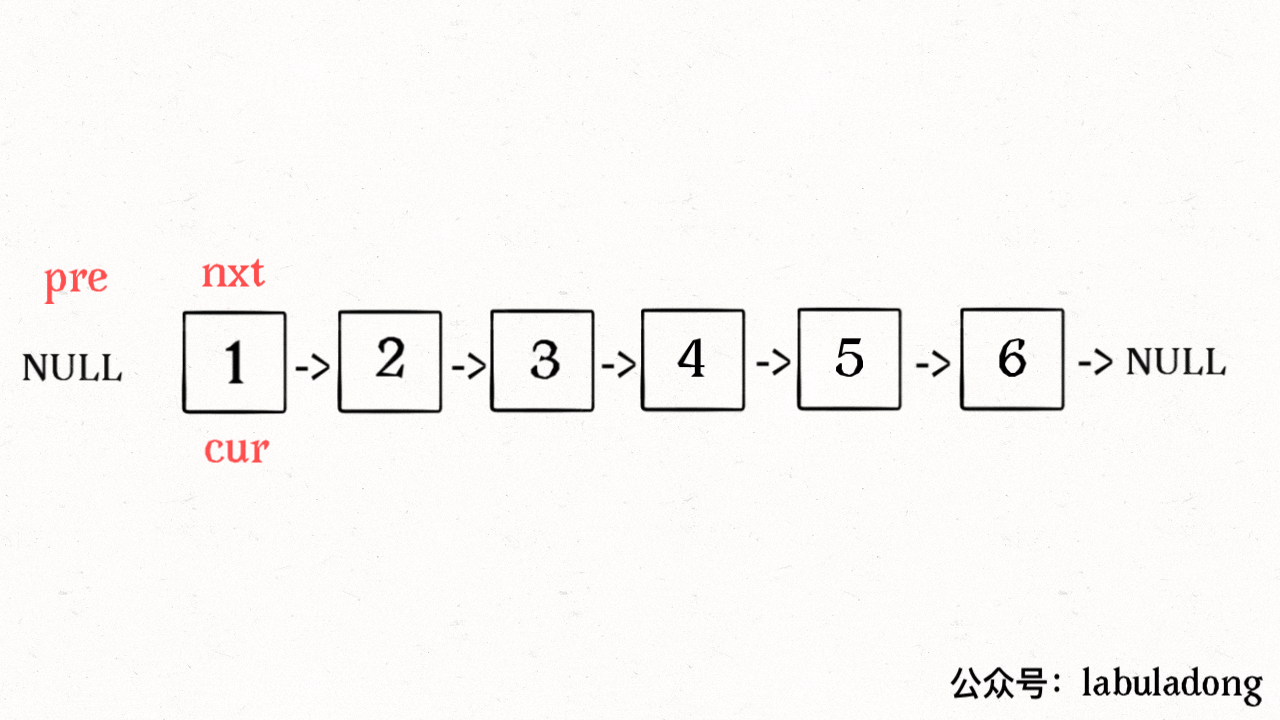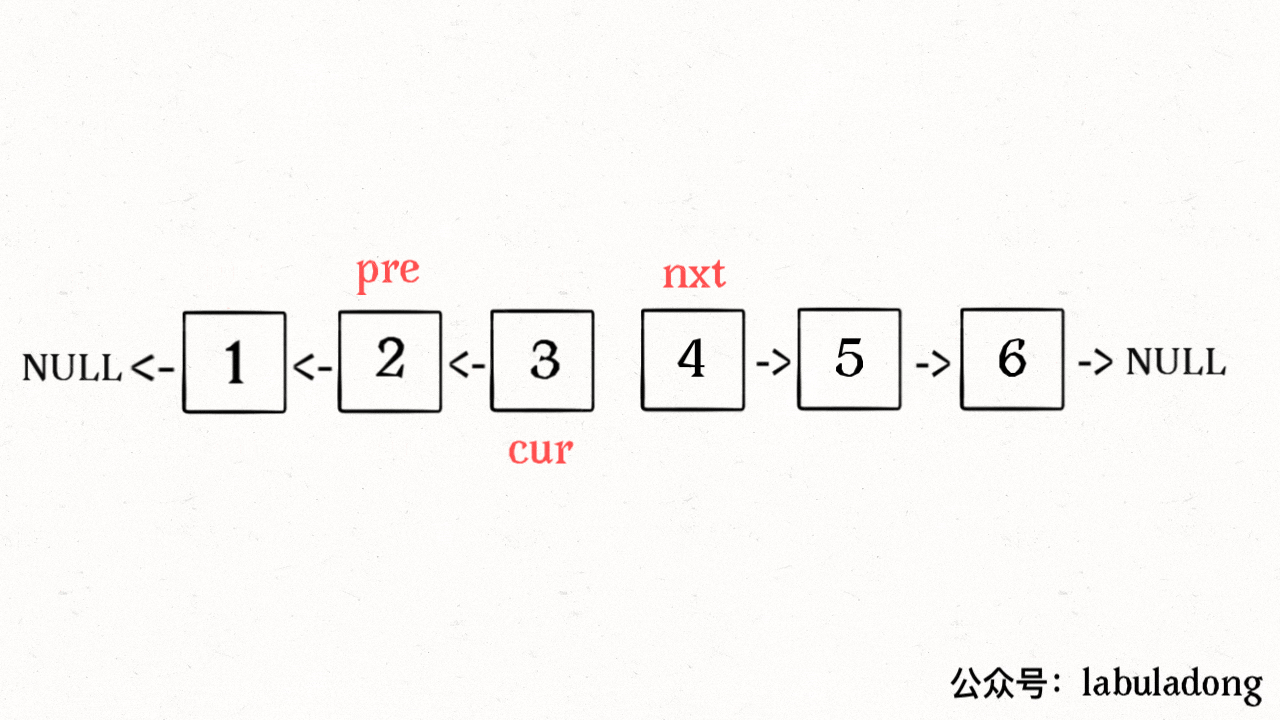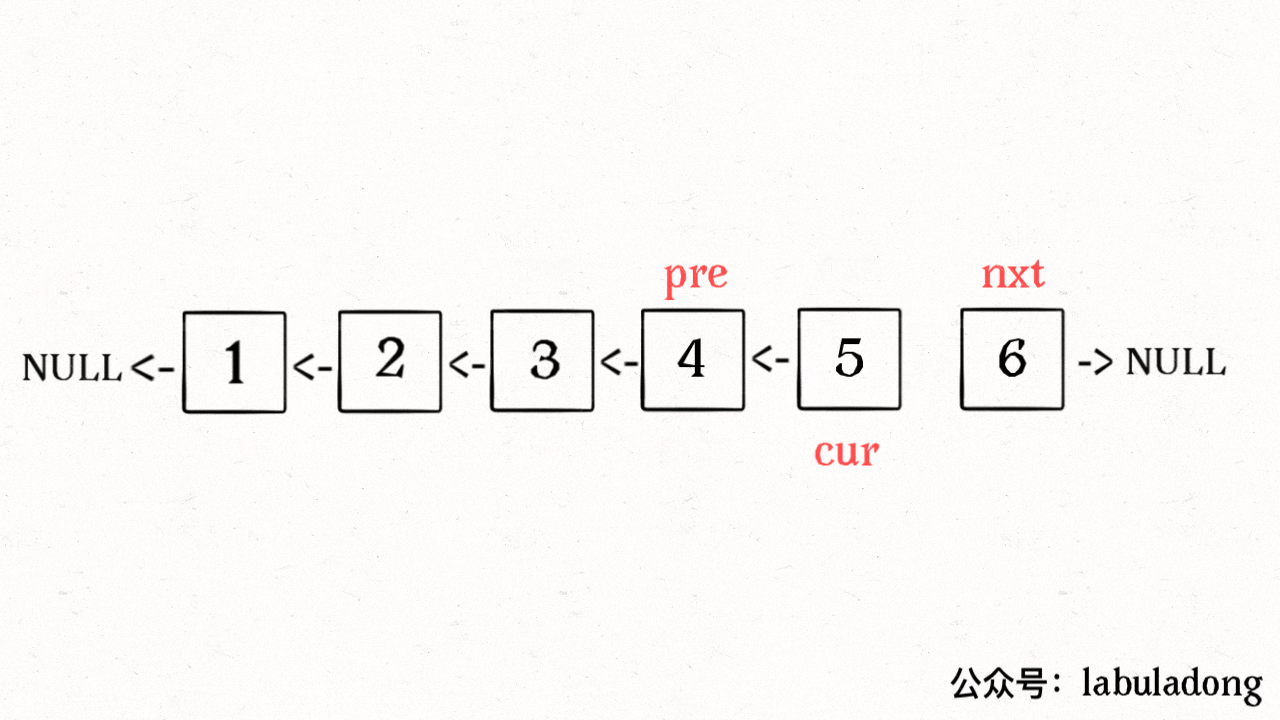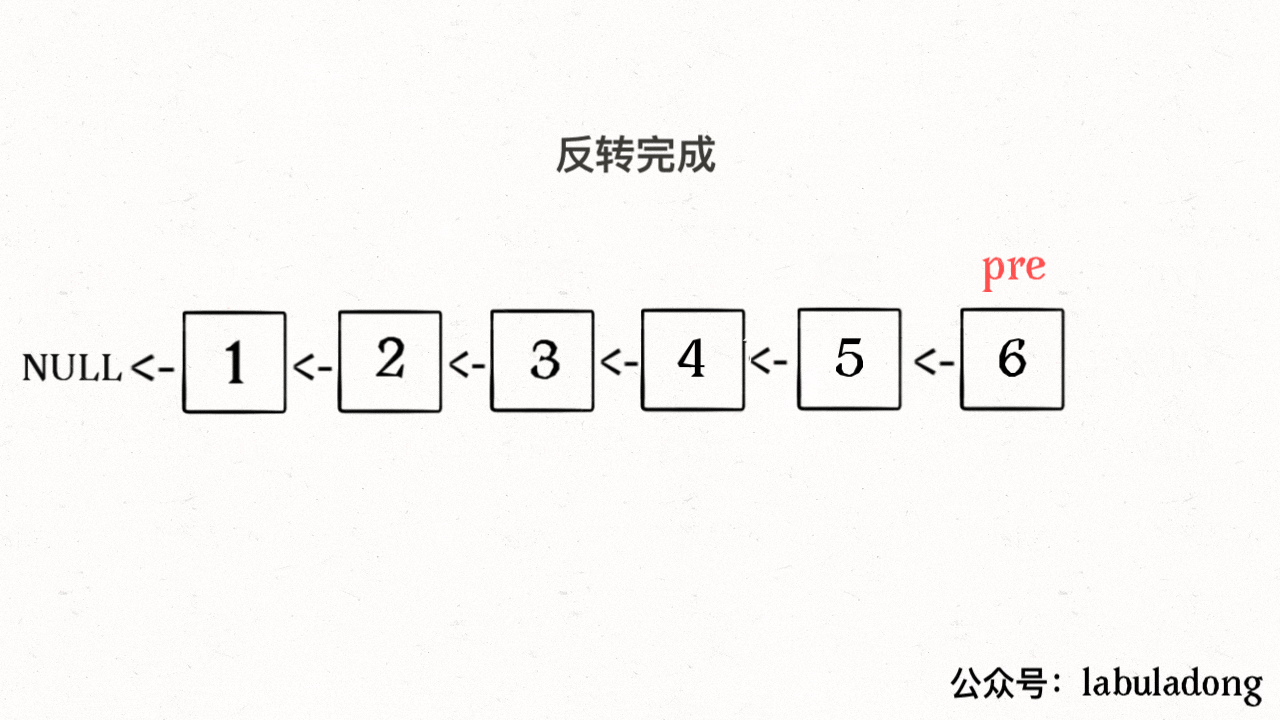
这次使用迭代思路来实现的,借助动画理解应该很容易。
@@ -130,29 +139,28 @@ ListNode reverseKGroup(ListNode head, int k) {
解释一下 `for` 循环之后的几句代码,注意 `reverse` 函数是反转区间 `[a, b)`,所以情形是这样的:
-
+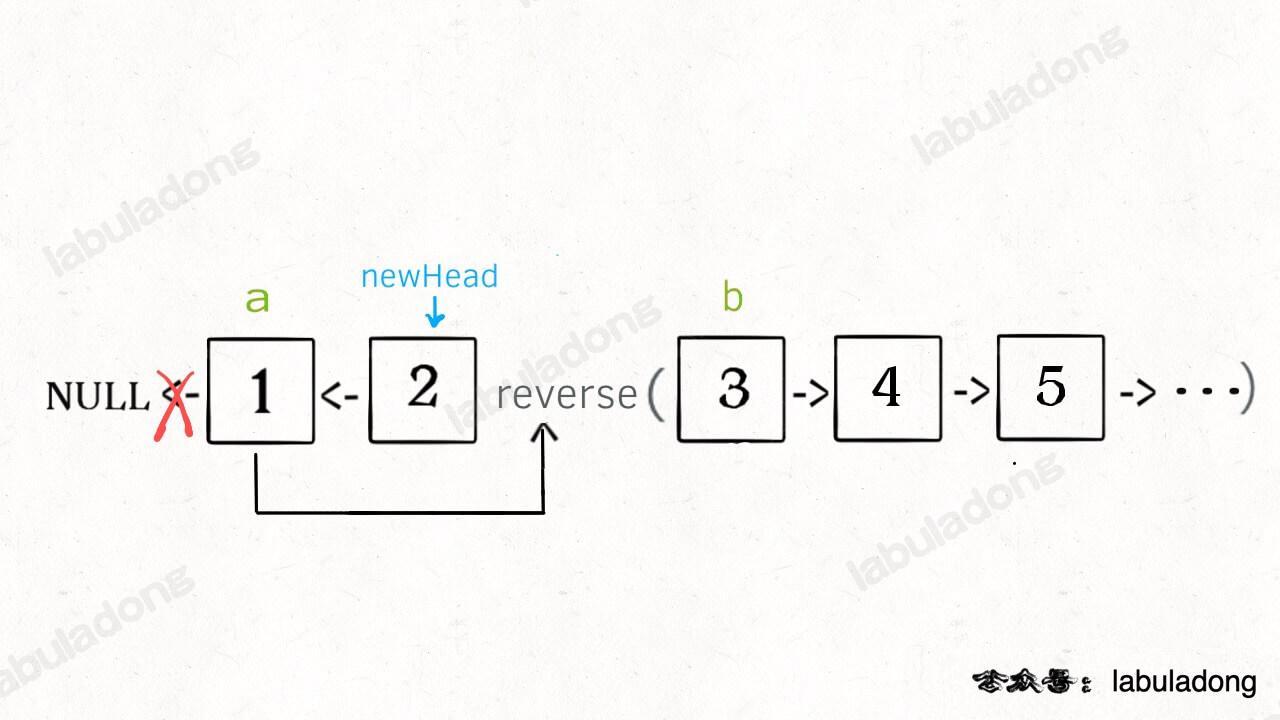
递归部分就不展开了,整个函数递归完成之后就是这个结果,完全符合题意:
-
+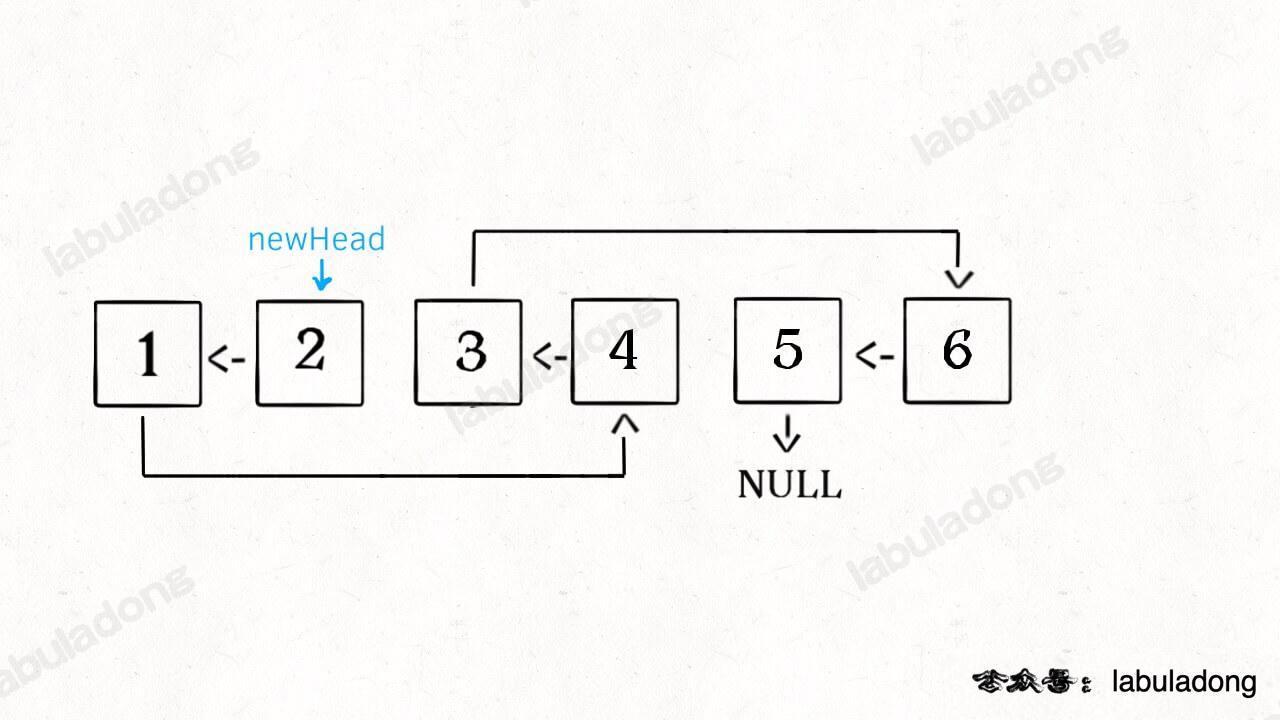
### 三、最后说两句
从阅读量上看,基本数据结构相关的算法文章看的人都不多,我想说这是要吃亏的。
-大家喜欢看动态规划相关的问题,可能因为面试很常见,但就我个人理解,很多算法思想都是源于数据结构的。我们公众号的成名之作之一,「学习数据结构的框架思维」就提过,什么动规、回溯、分治算法,其实都是树的遍历,树这种结构它不就是个多叉链表吗?你能处理基本数据结构的问题,解决一般的算法问题应该也不会太费事。
+大家喜欢看动态规划相关的问题,可能因为面试很常见,但就我个人理解,很多算法思想都是源于数据结构的。我们公众号的成名之作之一,[学习数据结构的框架思维](https://labuladong.github.io/article/fname.html?fname=学习数据结构和算法的高效方法) 就提过,什么动规、回溯、分治算法,其实都是树的遍历,树这种结构它不就是个多叉链表吗?你能处理基本数据结构的问题,解决一般的算法问题应该也不会太费事。
那么如何分解问题、发现递归性质呢?这个只能多练习,也许后续可以专门写一篇文章来探讨一下,本文就到此为止吧,希望对大家有帮助!
+> 最后打个广告,我亲自制作了一门 [数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO),以视频课为主,手把手带你实现常用的数据结构及相关算法,旨在帮助算法基础较为薄弱的读者深入理解常用数据结构的底层原理,在算法学习中少走弯路。
+
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\270\200\350\241\214\344\273\243\347\240\201\350\247\243\345\206\263\347\232\204\346\231\272\345\212\233\351\242\230.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\270\200\350\241\214\344\273\243\347\240\201\350\247\243\345\206\263\347\232\204\346\231\272\345\212\233\351\242\230.md"
index 99e92dda89b3f2836e62591b96083d574985b1df..2e156e296f2407dc5ff2e3f6bcf770d29f9b78fb 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\270\200\350\241\214\344\273\243\347\240\201\350\247\243\345\206\263\347\232\204\346\231\272\345\212\233\351\242\230.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\270\200\350\241\214\344\273\243\347\240\201\350\247\243\345\206\263\347\232\204\346\231\272\345\212\233\351\242\230.md"
@@ -1,34 +1,41 @@
# 一行代码就能解决的算法题
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[292.Nim游戏](https://leetcode-cn.com/problems/nim-game)
-[877.石子游戏](https://leetcode-cn.com/problems/stone-game)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-[319.灯泡开关](https://leetcode-cn.com/problems/bulb-switcher)
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [292. Nim Game](https://leetcode.com/problems/nim-game/) | [292. Nim 游戏](https://leetcode.cn/problems/nim-game/) | 🟢
+| [319. Bulb Switcher](https://leetcode.com/problems/bulb-switcher/) | [319. 灯泡开关](https://leetcode.cn/problems/bulb-switcher/) | 🟠
+| [877. Stone Game](https://leetcode.com/problems/stone-game/) | [877. 石子游戏](https://leetcode.cn/problems/stone-game/) | 🟠
**-----------**
-下文是我在 LeetCode 刷题过程中总结的三道有趣的「脑筋急转弯」题目,可以使用算法编程解决,但只要稍加思考,就能找到规律,直接想出答案。
+下文是我在刷题过程中总结的三道有趣的「脑筋急转弯」题目,可以使用算法编程解决,但只要稍加思考,就能找到规律,直接想出答案。
### 一、Nim 游戏
-游戏规则是这样的:你和你的朋友面前有一堆石子,你们轮流拿,一次至少拿一颗,最多拿三颗,谁拿走最后一颗石子谁获胜。
+力扣第 292 题「Nim 游戏」给了这样一个游戏规则:
+
+你和你的朋友面前有一堆石子,你们轮流拿,一次至少拿一颗,最多拿三颗,谁拿走最后一颗石子谁获胜。
-假设你们都很聪明,由你第一个开始拿,请你写一个算法,输入一个正整数 n,返回你是否能赢(true 或 false)。
+假设你们都很聪明,由你第一个开始拿,请你写一个算法,输入一个正整数 `n`,返回你是否能赢(true 或 false)。
比如现在有 4 颗石子,算法应该返回 false。因为无论你拿 1 颗 2 颗还是 3 颗,对方都能一次性拿完,拿走最后一颗石子,所以你一定会输。
@@ -46,20 +53,21 @@
这样一直循环下去,我们发现只要踩到 4 的倍数,就落入了圈套,永远逃不出 4 的倍数,而且一定会输。所以这道题的解法非常简单:
-```cpp
-bool canWinNim(int n) {
+```java
+boolean canWinNim(int n) {
// 如果上来就踩到 4 的倍数,那就认输吧
// 否则,可以把对方控制在 4 的倍数,必胜
return n % 4 != 0;
}
```
-
### 二、石头游戏
-游戏规则是这样的:你和你的朋友面前有一排石头堆,用一个数组 piles 表示,piles[i] 表示第 i 堆石子有多少个。你们轮流拿石头,一次拿一堆,但是只能拿走最左边或者最右边的石头堆。所有石头被拿完后,谁拥有的石头多,谁获胜。
+力扣第 877 题「石子游戏」的规则是这样的:
+
+你和你的朋友面前有一排石头堆,用一个数组 `piles` 表示,`piles[i]` 表示第 `i` 堆石子有多少个。你们轮流拿石头,一次拿一堆,但是只能拿走最左边或者最右边的石头堆。所有石头被拿完后,谁拥有的石头多,谁获胜。
-**假设你们都很聪明**,由你第一个开始拿,请你写一个算法,输入一个数组 piles,返回你是否能赢(true 或 false)。
+**假设你们都很聪明**,由你第一个开始拿,请你写一个算法,输入一个数组 `piles`,返回你是否能赢(true 或 false)。
注意,石头的堆的数量为偶数,所以你们两人拿走的堆数一定是相同的。石头的总数为奇数,也就是你们最后不可能拥有相同多的石头,一定有胜负之分。
@@ -97,7 +105,9 @@ boolean stoneGame(int[] piles) {
### 三、电灯开关问题
-这个问题是这样描述的:有 n 盏电灯,最开始时都是关着的。现在要进行 n 轮操作:
+力扣第 319 题「灯泡开关」的规则是这样的:
+
+有 `n` 盏电灯,最开始时都是关着的。现在要进行 `n` 轮操作:
第 1 轮操作是把每一盏电灯的开关按一下(全部打开)。
@@ -105,9 +115,9 @@ boolean stoneGame(int[] piles) {
第 3 轮操作是把每三盏灯的开关按一下(就是按第 3,6,9... 盏灯的开关,有的被关闭,比如 3,有的被打开,比如 6)...
-如此往复,直到第 n 轮,即只按一下第 n 盏灯的开关。
+如此往复,直到第 `n` 轮,即只按一下第 `n` 盏灯的开关。
-现在给你输入一个正整数 n 代表电灯的个数,问你经过 n 轮操作后,这些电灯有多少盏是亮的?
+现在给你输入一个正整数 `n` 代表电灯的个数,问你经过 `n` 轮操作后,这些电灯有多少盏是亮的?
我们当然可以用一个布尔数组表示这些灯的开关情况,然后模拟这些操作过程,最后去数一下就能出结果。但是这样显得没有灵性,最好的解法是这样的:
@@ -125,7 +135,7 @@ int bulbSwitch(int n) {
为什么第 1、2、3、6 轮会被按呢?因为 `6=1*6=2*3`。一般情况下,因子都是成对出现的,也就是说开关被按的次数一般是偶数次。但是有特殊情况,比如说总共有 16 盏灯,那么第 16 盏灯会被按几次?
-`16=1*16=2*8=4*4`
+`16 = 1*16 = 2*8 = 4*4`
其中因子 4 重复出现,所以第 16 盏灯会被按 5 次,奇数次。现在你应该理解这个问题为什么和平方根有关了吧?
@@ -133,19 +143,15 @@ int bulbSwitch(int n) {
就假设现在总共有 16 盏灯,我们求 16 的平方根,等于 4,这就说明最后会有 4 盏灯亮着,它们分别是第 `1*1=1` 盏、第 `2*2=4` 盏、第 `3*3=9` 盏和第 `4*4=16` 盏。
-就算有的 n 平方根结果是小数,强转成 int 型,也相当于一个最大整数上界,比这个上界小的所有整数,平方后的索引都是最后亮着的灯的索引。所以说我们直接把平方根转成整数,就是这个问题的答案。
-
-
+就算有的 `n` 平方根结果是小数,强转成 int 型,也相当于一个最大整数上界,比这个上界小的所有整数,平方后的索引都是最后亮着的灯的索引。所以说我们直接把平方根转成整数,就是这个问题的答案。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[292.Nim游戏](https://leetcode-cn.com/problems/nim-game)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\345\210\244\345\256\232\345\255\220\345\272\217\345\210\227.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\345\210\244\345\256\232\345\255\220\345\272\217\345\210\227.md"
index 9aecd329a9a68db6bf901252bd7165290edf25e9..de3353f4567ab56792af2ac2959812cff7d4dbb3 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\345\210\244\345\256\232\345\255\220\345\272\217\345\210\227.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\344\272\214\345\210\206\346\237\245\346\211\276\345\210\244\345\256\232\345\255\220\345\272\217\345\210\227.md"
@@ -1,30 +1,42 @@
# 二分查找高效判定子序列
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[392.判断子序列](https://leetcode-cn.com/problems/is-subsequence)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [392. Is Subsequence](https://leetcode.com/problems/is-subsequence/) | [392. 判断子序列](https://leetcode.cn/problems/is-subsequence/) | 🟢
+| [792. Number of Matching Subsequences](https://leetcode.com/problems/number-of-matching-subsequences/) | [792. 匹配子序列的单词数](https://leetcode.cn/problems/number-of-matching-subsequences/) | 🟠
**-----------**
-二分查找本身不难理解,难在巧妙地运用二分查找技巧。对于一个问题,你可能都很难想到它跟二分查找有关,比如前文 [最长递增子序列](https://labuladong.gitee.io/algo/) 就借助一个纸牌游戏衍生出二分查找解法。
+二分查找本身不难理解,难在巧妙地运用二分查找技巧。
-今天再讲一道巧用二分查找的算法问题:如何判定字符串 `s` 是否是字符串 `t` 的子序列(可以假定 `s` 长度比较小,且 `t` 的长度非常大)。举两个例子:
+对于一个问题,你可能都很难想到它跟二分查找有关,比如前文 [最长递增子序列](https://labuladong.github.io/article/fname.html?fname=动态规划设计:最长递增子序列) 就借助一个纸牌游戏衍生出二分查找解法。
+今天再讲一道巧用二分查找的算法问题,力扣第 392 题「判断子序列」:
-s = "abc", t = "**a**h**b**gd**c**", return true.
+请你判定字符串 `s` 是否是字符串 `t` 的子序列(可以假定 `s` 长度比较小,且 `t` 的长度非常大)。
+举两个例子:
+
+s = "abc", t = "**a**h**b**gd**c**", return true.
s = "axc", t = "ahbgdc", return false.
@@ -34,20 +46,22 @@ s = "axc", t = "ahbgdc", return false.
首先,一个很简单的解法是这样的:
-```cpp
-bool isSubsequence(string s, string t) {
+```java
+boolean isSubsequence(String s, String t) {
int i = 0, j = 0;
- while (i < s.size() && j < t.size()) {
- if (s[i] == t[j]) i++;
+ while (i < s.length() && j < t.length()) {
+ if (s.charAt(i) == t.charAt(j)) {
+ i++;
+ }
j++;
}
- return i == s.size();
+ return i == s.length();
}
```
其思路也非常简单,利用双指针 `i, j` 分别指向 `s, t`,一边前进一边匹配子序列:
-
+
读者也许会问,这不就是最优解法了吗,时间复杂度只需 O(N),N 为 `t` 的长度。
@@ -79,21 +93,21 @@ for (int i = 0; i < n; i++) {
}
```
-
+
比如对于这个情况,匹配了 "ab",应该匹配 "c" 了:
-
+
按照之前的解法,我们需要 `j` 线性前进扫描字符 "c",但借助 `index` 中记录的信息,**可以二分搜索 `index[c]` 中比 j 大的那个索引**,在上图的例子中,就是在 `[0,2,6]` 中搜索比 4 大的那个索引:
-
+
这样就可以直接得到下一个 "c" 的索引。现在的问题就是,如何用二分查找计算那个恰好比 4 大的索引呢?答案是,寻找左侧边界的二分搜索就可以做到。
### 三、再谈二分查找
-在前文 [二分查找详解](https://labuladong.gitee.io/algo/) 中,详解了如何正确写出三种二分查找算法的细节。二分查找返回目标值 `val` 的索引,对于搜索**左侧边界**的二分查找,有一个特殊性质:
+在前文 [二分查找详解](https://labuladong.github.io/article/fname.html?fname=二分查找详解) 中,详解了如何正确写出三种二分查找算法的细节。二分查找返回目标值 `val` 的索引,对于搜索**左侧边界**的二分查找,有一个特殊性质:
**当 `val` 不存在时,得到的索引恰好是比 `val` 大的最小元素索引**。
@@ -101,23 +115,24 @@ for (int i = 0; i < n; i++) {
```java
// 查找左侧边界的二分查找
-int left_bound(ArrayList arr, int tar) {
- int lo = 0, hi = arr.size();
- while (lo < hi) {
- int mid = lo + (hi - lo) / 2;
- if (tar > arr.get(mid)) {
- lo = mid + 1;
+int left_bound(ArrayList arr, int target) {
+ int left = 0, right = arr.size();
+ while (left < right) {
+ int mid = left + (right - left) / 2;
+ if (target > arr.get(mid)) {
+ left = mid + 1;
} else {
- hi = mid;
+ right = mid;
}
}
- return lo;
+ if (left == arr.size()) {
+ return -1;
+ }
+ return left;
}
```
-以上就是搜索左侧边界的二分查找,等会儿会用到,其中的细节可以参见前文《二分查找详解》,这里不再赘述。
-
-### 四、代码实现
+以上就是搜索左侧边界的二分查找,等会儿会用到,其中的细节可以参见前文 [二分查找详解](https://labuladong.github.io/article/fname.html?fname=二分查找详解),这里不再赘述。
这里以单个字符串 `s` 为例,对于多个字符串 `s`,可以把预处理部分抽出来。
@@ -142,7 +157,7 @@ boolean isSubsequence(String s, String t) {
if (index[c] == null) return false;
int pos = left_bound(index[c], j);
// 二分搜索区间中没有找到字符 c
- if (pos == index[c].size()) return false;
+ if (pos == -1) return false;
// 向前移动指针 j
j = index[c].get(pos) + 1;
}
@@ -152,19 +167,76 @@ boolean isSubsequence(String s, String t) {
算法执行的过程是这样的:
-
+
+
+可见借助二分查找,算法的效率是可以大幅提升的。
+
+明白了这个思路,我们可以直接拿下力扣第 792 题「匹配子序列的单词数」:给你输入一个字符串列表 `words` 和一个字符串 `s`,问你 `words` 中有多少字符串是 `s` 的子序列。
+
+函数签名如下:
+
+```java
+int numMatchingSubseq(String s, String[] words)
+```
+
+我们直接把上一道题的代码稍微改改即可完成这道题:
-可见借助二分查找,算法的效率是可以大幅提升的。
+```java
+int numMatchingSubseq(String s, String[] words) {
+ // 对 s 进行预处理
+ // char -> 该 char 的索引列表
+ ArrayList[] index = new ArrayList[256];
+ for (int i = 0; i < s.length(); i++) {
+ char c = s.charAt(i);
+ if (index[c] == null) {
+ index[c] = new ArrayList<>();
+ }
+ index[c].add(i);
+ }
+
+ int res = 0;
+ for (String word : words) {
+ // 字符串 word 上的指针
+ int i = 0;
+ // 串 s 上的指针
+ int j = 0;
+ // 借助 index 查找 word 中每个字符的索引
+ for (; i < word.length(); i++) {
+ char c = word.charAt(i);
+ // 整个 s 压根儿没有字符 c
+ if (index[c] == null) {
+ break;
+ }
+ int pos = left_bound(index[c], j);
+ // 二分搜索区间中没有找到字符 c
+ if (pos == -1) {
+ break;
+ }
+ // 向前移动指针 j
+ j = index[c].get(pos) + 1;
+ }
+ // 如果 word 完成匹配,则是子序列
+ if (i == word.length()) {
+ res++;
+ }
+ }
+
+ return res;
+}
+
+// 查找左侧边界的二分查找
+int left_bound(ArrayList arr, int target) {
+ // 见上文
+}
+```
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[392.判断子序列](https://leetcode-cn.com/problems/is-subsequence)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\210\244\346\226\255\345\233\236\346\226\207\351\223\276\350\241\250.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\210\244\346\226\255\345\233\236\346\226\207\351\223\276\350\241\250.md"
index c8702f972fc812bbcfa3996a4e9436be157aa1bc..ffce166d04b34550cf0c49ef4a023b3d51ddd7d8 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\210\244\346\226\255\345\233\236\346\226\207\351\223\276\350\241\250.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\210\244\346\226\255\345\233\236\346\226\207\351\223\276\350\241\250.md"
@@ -1,51 +1,64 @@
# 如何高效判断回文链表
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[234.回文链表](https://leetcode-cn.com/problems/palindrome-linked-list)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [234. Palindrome Linked List](https://leetcode.com/problems/palindrome-linked-list/) | [234. 回文链表](https://leetcode.cn/problems/palindrome-linked-list/) | 🟢
+| - | [剑指 Offer II 027. 回文链表](https://leetcode.cn/problems/aMhZSa/) | 🟢
**-----------**
-我们之前有两篇文章写了回文串和回文序列相关的问题。
+前文 [数组双指针技巧汇总](https://labuladong.github.io/article/fname.html?fname=双指针技巧) 和 [子序列问题解题思路](https://labuladong.github.io/article/fname.html?fname=子序列问题模板) 讲解了回文串和回文序列相关的问题,先来简单回顾下。
**寻找**回文串的核心思想是从中心向两端扩展:
-```cpp
-string palindrome(string& s, int l, int r) {
+```java
+// 在 s 中寻找以 s[left] 和 s[right] 为中心的最长回文串
+String palindrome(String s, int left, int right) {
// 防止索引越界
- while (l >= 0 && r < s.size()
- && s[l] == s[r]) {
- // 向两边展开
- l--; r++;
+ while (left >= 0 && right < s.length()
+ && s.charAt(left) == s.charAt(right)) {
+ // 双指针,向两边展开
+ left--;
+ right++;
}
- // 返回以 s[l] 和 s[r] 为中心的最长回文串
- return s.substr(l + 1, r - l - 1);
+ // 返回以 s[left] 和 s[right] 为中心的最长回文串
+ return s.substring(left + 1, right);
}
```
-因为回文串长度可能为奇数也可能是偶数,长度为奇数时只存在一个中心点,而长度为偶数时存在两个中心点,所以上面这个函数需要传入`l`和`r`。
+因为回文串长度可能为奇数也可能是偶数,长度为奇数时只存在一个中心点,而长度为偶数时存在两个中心点,所以上面这个函数需要传入 `l` 和 `r`。
-而**判断**一个字符串是不是回文串就简单很多,不需要考虑奇偶情况,只需要「双指针技巧」,从两端向中间逼近即可:
+而**判断**一个字符串是不是回文串就简单很多,不需要考虑奇偶情况,只需要[双指针技巧](https://labuladong.github.io/article/fname.html?fname=双指针技巧),从两端向中间逼近即可:
-```cpp
-bool isPalindrome(string s) {
- int left = 0, right = s.length - 1;
+```java
+boolean isPalindrome(String s) {
+ // 一左一右两个指针相向而行
+ int left = 0, right = s.length() - 1;
while (left < right) {
- if (s[left] != s[right])
+ if (s.charAt(left) != s.charAt(right)) {
return false;
- left++; right--;
+ }
+ left++;
+ right--;
}
return true;
}
@@ -57,19 +70,17 @@ bool isPalindrome(string s) {
### 一、判断回文单链表
-输入一个单链表的头结点,判断这个链表中的数字是不是回文:
+看下力扣第 234 题「回文链表」:
-```java
-/**
- * 单链表节点的定义:
- * public class ListNode {
- * int val;
- * ListNode next;
- * }
- */
+输入一个单链表的头结点,判断这个链表中的数字是不是回文,函数签名如下:
+```java
boolean isPalindrome(ListNode head);
+```
+比如说:
+
+```
输入: 1->2->null
输出: false
@@ -77,7 +88,9 @@ boolean isPalindrome(ListNode head);
输出: true
```
-这道题的关键在于,单链表无法倒着遍历,无法使用双指针技巧。那么最简单的办法就是,把原始链表反转存入一条新的链表,然后比较这两条链表是否相同。关于如何反转链表,可以参见前文「递归操作链表」。
+这道题的关键在于,单链表无法倒着遍历,无法使用双指针技巧。
+
+那么最简单的办法就是,把原始链表反转存入一条新的链表,然后比较这两条链表是否相同。关于如何反转链表,可以参见前文 [递归翻转链表的一部分](https://labuladong.github.io/article/fname.html?fname=递归反转链表的一部分)。
其实,**借助二叉树后序遍历的思路,不需要显式反转原始链表也可以倒序遍历链表**,下面来具体聊聊。
@@ -93,7 +106,7 @@ void traverse(TreeNode root) {
}
```
-在「学习数据结构的框架思维」中说过,链表兼具递归结构,树结构不过是链表的衍生。那么,**链表其实也可以有前序遍历和后序遍历**:
+在 [学习数据结构的框架思维](https://labuladong.github.io/article/fname.html?fname=学习数据结构和算法的高效方法) 中说过,链表兼具递归结构,树结构不过是链表的衍生。那么,**链表其实也可以有前序遍历和后序遍历**:
```java
void traverse(ListNode head) {
@@ -103,7 +116,7 @@ void traverse(ListNode head) {
}
```
-这个框架有什么指导意义呢?如果我想正序打印链表中的`val`值,可以在前序遍历位置写代码;反之,如果想倒序遍历链表,就可以在后序遍历位置操作:
+这个框架有什么指导意义呢?如果我想正序打印链表中的 `val` 值,可以在前序遍历位置写代码;反之,如果想倒序遍历链表,就可以在后序遍历位置操作:
```java
/* 倒序打印单链表中的元素值 */
@@ -136,17 +149,17 @@ boolean traverse(ListNode right) {
}
```
-这么做的核心逻辑是什么呢?**实际上就是把链表节点放入一个栈,然后再拿出来,这时候元素顺序就是反的**,只不过我们利用的是递归函数的堆栈而已。
+这么做的核心逻辑是什么呢?**实际上就是把链表节点放入一个栈,然后再拿出来,这时候元素顺序就是反的**,只不过我们利用的是递归函数的堆栈而已,如下 GIF 所示:
-
+
-当然,无论造一条反转链表还是利用后续遍历,算法的时间和空间复杂度都是 O(N)。下面我们想想,能不能不用额外的空间,解决这个问题呢?
+当然,无论造一条反转链表还是利用后序遍历,算法的时间和空间复杂度都是 O(N)。下面我们想想,能不能不用额外的空间,解决这个问题呢?
### 二、优化空间复杂度
更好的思路是这样的:
-**1、先通过「双指针技巧」中的快慢指针来找到链表的中点**:
+**1、先通过 [双指针技巧](https://labuladong.github.io/article/fname.html?fname=链表技巧) 中的快慢指针来找到链表的中点**:
```java
ListNode slow, fast;
@@ -158,7 +171,7 @@ while (fast != null && fast.next != null) {
// slow 指针现在指向链表中点
```
-
+
**2、如果`fast`指针没有指向`null`,说明链表长度为奇数,`slow`还要再前进一步**:
@@ -167,7 +180,7 @@ if (fast != null)
slow = slow.next;
```
-
+
**3、从`slow`开始反转后面的链表,现在就可以开始比较回文串了**:
@@ -184,11 +197,34 @@ while (right != null) {
return true;
```
-
+
-至此,把上面 3 段代码合在一起就高效地解决这个问题了,其中`reverse`函数很容易实现:
+至此,把上面 3 段代码合在一起就高效地解决这个问题了,其中 `reverse` 函数很容易实现:
```java
+boolean isPalindrome(ListNode head) {
+ ListNode slow, fast;
+ slow = fast = head;
+ while (fast != null && fast.next != null) {
+ slow = slow.next;
+ fast = fast.next.next;
+ }
+
+ if (fast != null)
+ slow = slow.next;
+
+ ListNode left = head;
+ ListNode right = reverse(slow);
+ while (right != null) {
+ if (left.val != right.val)
+ return false;
+ left = left.next;
+ right = right.next;
+ }
+
+ return true;
+}
+
ListNode reverse(ListNode head) {
ListNode pre = null, cur = head;
while (cur != null) {
@@ -201,7 +237,9 @@ ListNode reverse(ListNode head) {
}
```
-
+算法过程如下 GIF 所示:
+
+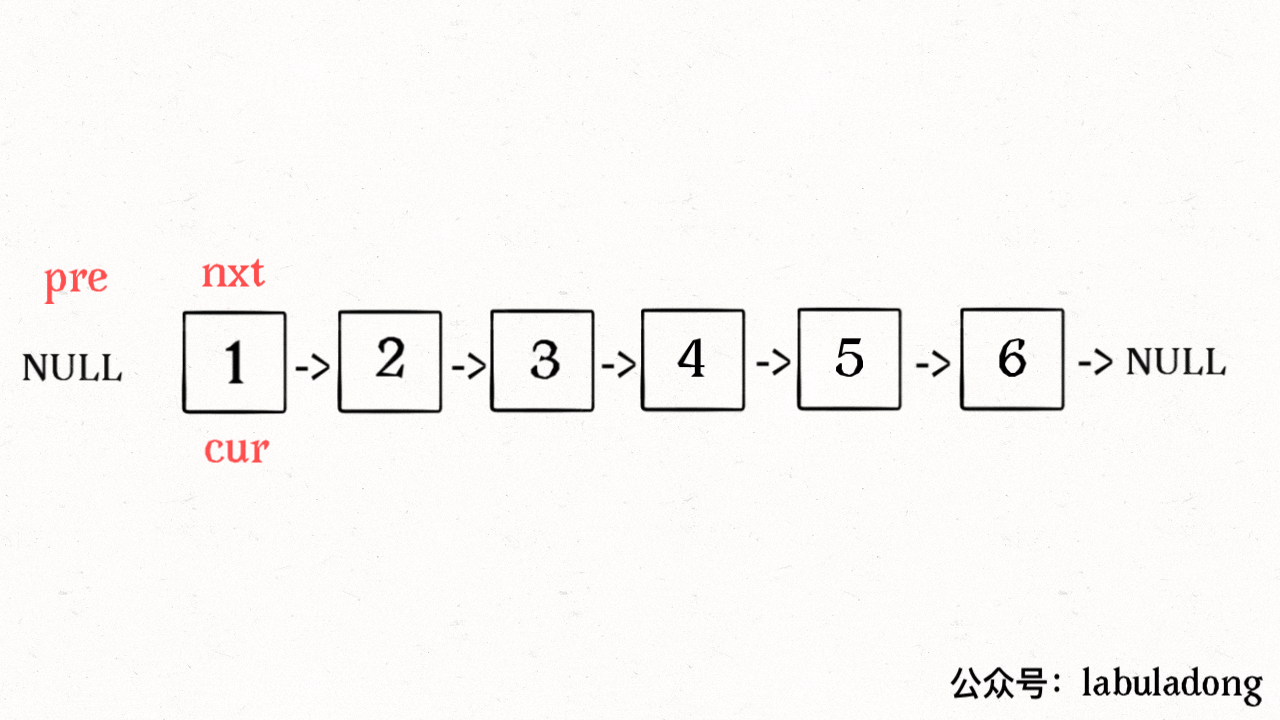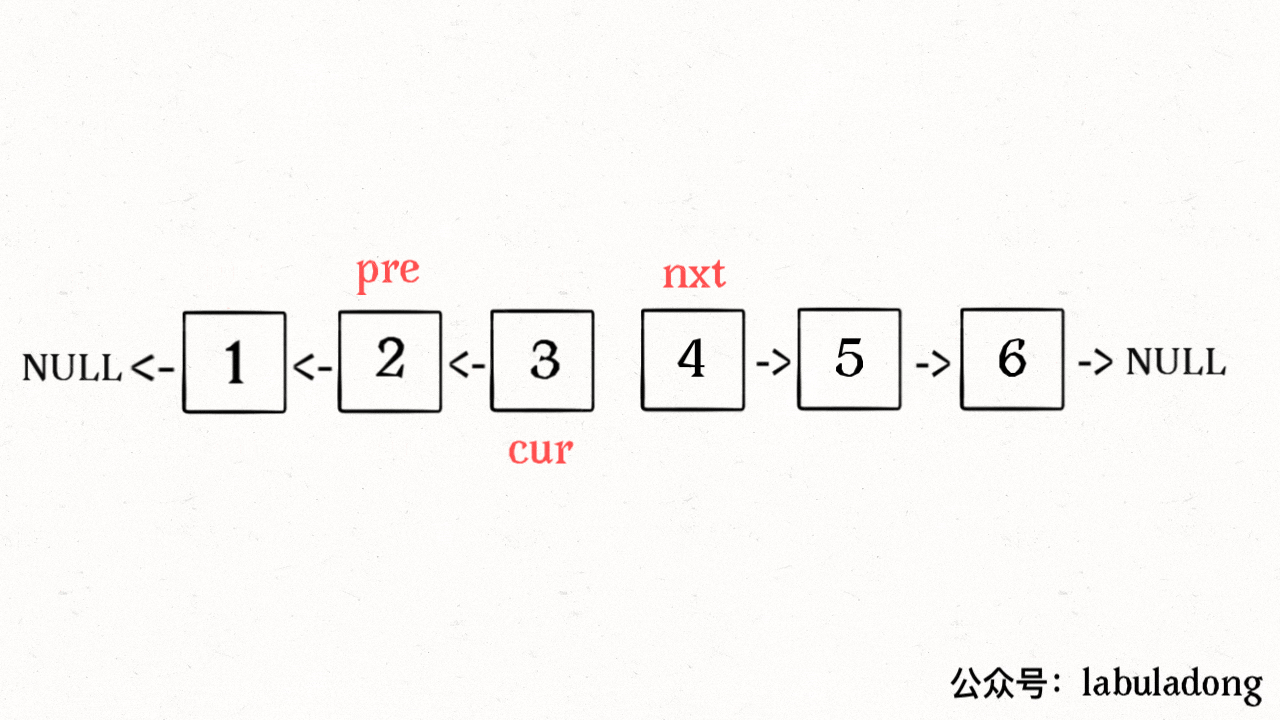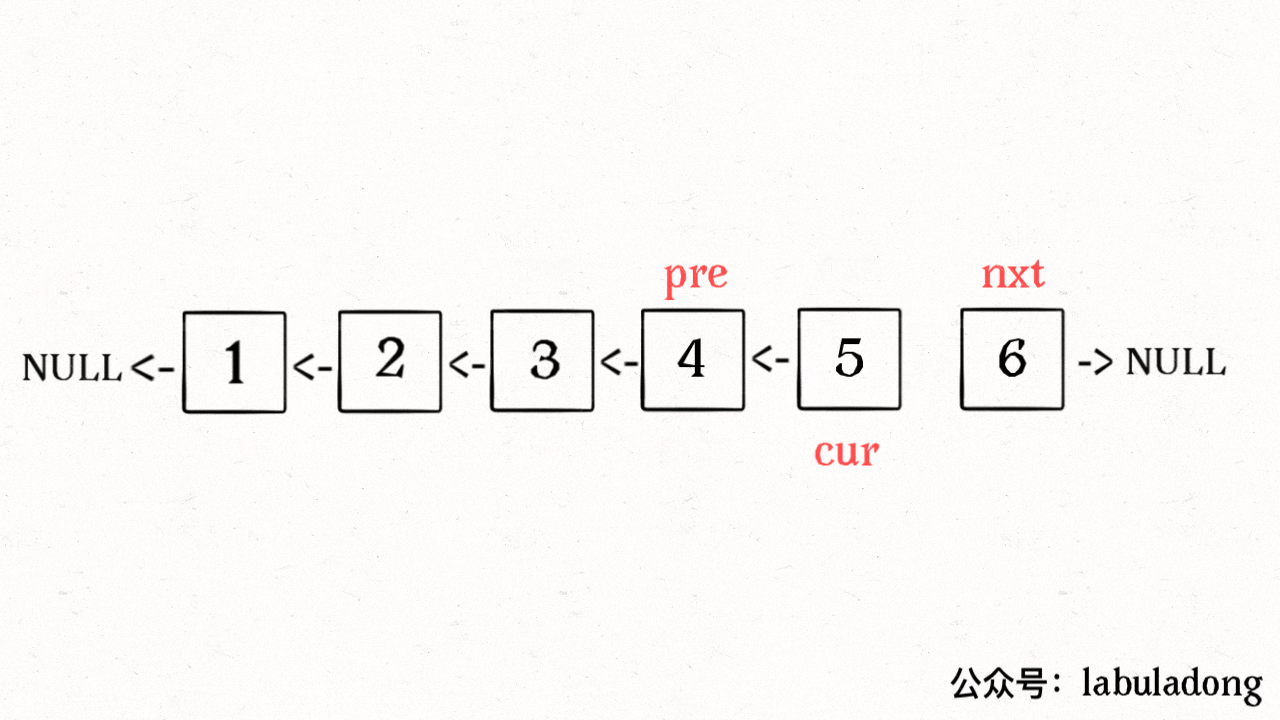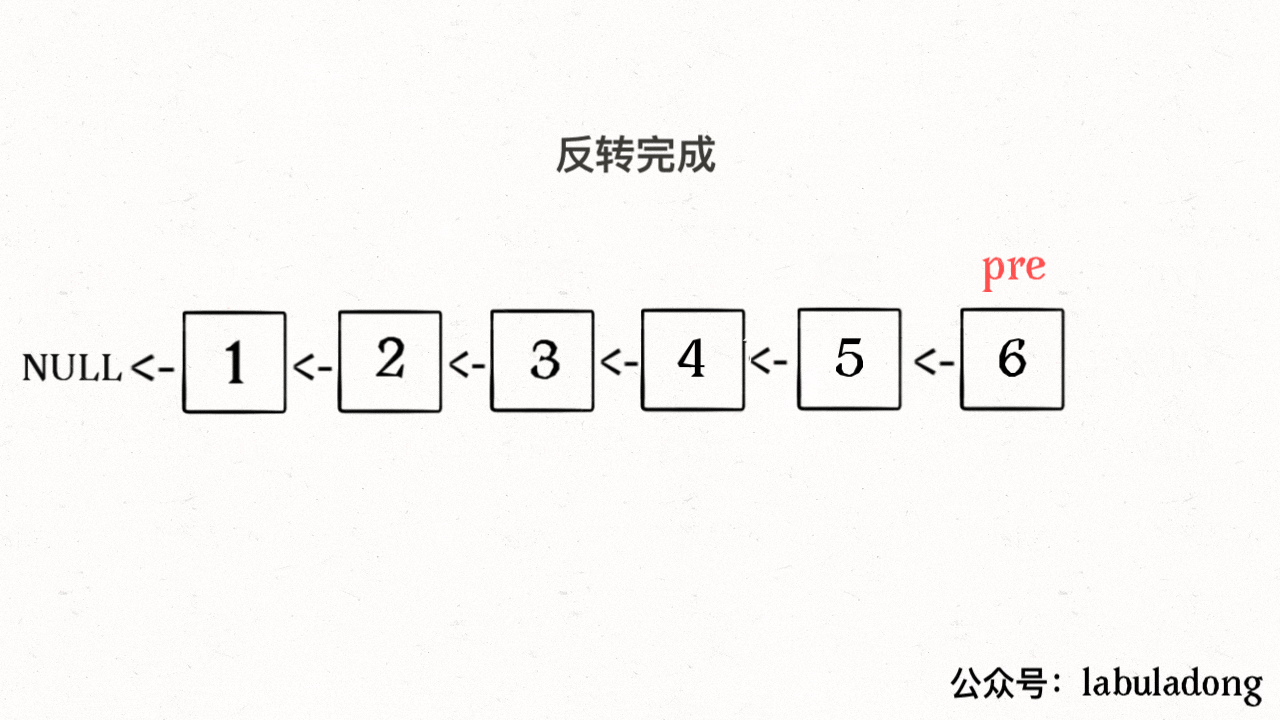
算法总体的时间复杂度 O(N),空间复杂度 O(1),已经是最优的了。
@@ -209,7 +247,7 @@ ListNode reverse(ListNode head) {
其实这个问题很好解决,关键在于得到`p, q`这两个指针位置:
-
+
这样,只要在函数 return 之前加一段代码即可恢复原先链表顺序:
@@ -225,15 +263,15 @@ p.next = reverse(q);
具体到回文链表的判断问题,由于回文的特殊性,可以不完全反转链表,而是仅仅反转部分链表,将空间复杂度降到 O(1)。
+> 最后打个广告,我亲自制作了一门 [数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO),以视频课为主,手把手带你实现常用的数据结构及相关算法,旨在帮助算法基础较为薄弱的读者深入理解常用数据结构的底层原理,在算法学习中少走弯路。
+
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[234.回文链表](https://leetcode-cn.com/problems/palindrome-linked-list)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\255\220\351\233\206\346\216\222\345\210\227\347\273\204\345\220\210.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\255\220\351\233\206\346\216\222\345\210\227\347\273\204\345\220\210.md"
index dad1a3e855a3a881ceb108604660d72b57a0afd9..708caa293709285cfa9facc74f8390d066bb8ffb 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\255\220\351\233\206\346\216\222\345\210\227\347\273\204\345\220\210.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\255\220\351\233\206\346\216\222\345\210\227\347\273\204\345\220\210.md"
@@ -1,286 +1,933 @@
-# 回溯算法团灭子集、排列、组合问题
+# 一文秒杀所有排列组合子集问题
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[78.子集](https://leetcode-cn.com/problems/subsets)
-[46.全排列](https://leetcode-cn.com/problems/permutations)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
-[77.组合](https://leetcode-cn.com/problems/combinations)
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [216. Combination Sum III](https://leetcode.com/problems/combination-sum-iii/) | [216. 组合总和 III](https://leetcode.cn/problems/combination-sum-iii/) | 🟠
+| [39. Combination Sum](https://leetcode.com/problems/combination-sum/) | [39. 组合总和](https://leetcode.cn/problems/combination-sum/) | 🟠
+| [40. Combination Sum II](https://leetcode.com/problems/combination-sum-ii/) | [40. 组合总和 II](https://leetcode.cn/problems/combination-sum-ii/) | 🟠
+| [46. Permutations](https://leetcode.com/problems/permutations/) | [46. 全排列](https://leetcode.cn/problems/permutations/) | 🟠
+| [47. Permutations II](https://leetcode.com/problems/permutations-ii/) | [47. 全排列 II](https://leetcode.cn/problems/permutations-ii/) | 🟠
+| [77. Combinations](https://leetcode.com/problems/combinations/) | [77. 组合](https://leetcode.cn/problems/combinations/) | 🟠
+| [78. Subsets](https://leetcode.com/problems/subsets/) | [78. 子集](https://leetcode.cn/problems/subsets/) | 🟠
+| [90. Subsets II](https://leetcode.com/problems/subsets-ii/) | [90. 子集 II](https://leetcode.cn/problems/subsets-ii/) | 🟠
+| - | [剑指 Offer II 079. 所有子集](https://leetcode.cn/problems/TVdhkn/) | 🟠
+| - | [剑指 Offer II 080. 含有 k 个元素的组合](https://leetcode.cn/problems/uUsW3B/) | 🟠
+| - | [剑指 Offer II 081. 允许重复选择元素的组合](https://leetcode.cn/problems/Ygoe9J/) | 🟠
+| - | [剑指 Offer II 082. 含有重复元素集合的组合](https://leetcode.cn/problems/4sjJUc/) | 🟠
+| - | [剑指 Offer II 083. 没有重复元素集合的全排列](https://leetcode.cn/problems/VvJkup/) | 🟠
+| - | [剑指 Offer II 084. 含有重复元素集合的全排列](https://leetcode.cn/problems/7p8L0Z/) | 🟠
**-----------**
-今天就来聊三道考察频率高,而且容易让人搞混的算法问题,分别是求子集(subset),求排列(permutation),求组合(combination)。
+> 本文有视频版:[回溯算法秒杀所有排列/组合/子集问题](https://www.bilibili.com/video/BV1Yt4y1t7dK/)
+
+虽然排列、组合、子集系列问题是高中就学过的,但如果想编写算法解决它们,还是非常考验计算机思维的,本文就讲讲编程解决这几个问题的核心思路,以后再有什么变体,你也能手到擒来,以不变应万变。
+
+无论是排列、组合还是子集问题,简单说无非就是让你从序列 `nums` 中以给定规则取若干元素,主要有以下几种变体:
+
+**形式一、元素无重不可复选,即 `nums` 中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式**。
+
+以组合为例,如果输入 `nums = [2,3,6,7]`,和为 7 的组合应该只有 `[7]`。
+
+**形式二、元素可重不可复选,即 `nums` 中的元素可以存在重复,每个元素最多只能被使用一次**。
+
+以组合为例,如果输入 `nums = [2,5,2,1,2]`,和为 7 的组合应该有两种 `[2,2,2,1]` 和 `[5,2]`。
+
+**形式三、元素无重可复选,即 `nums` 中的元素都是唯一的,每个元素可以被使用若干次**。
+
+以组合为例,如果输入 `nums = [2,3,6,7]`,和为 7 的组合应该有两种 `[2,2,3]` 和 `[7]`。
-这几个问题都可以用回溯算法模板解决,同时子集问题还可以用数学归纳思想解决。读者可以记住这几个问题的回溯套路,就不怕搞不清了。
+当然,也可以说有第四种形式,即元素可重可复选。但既然元素可复选,那又何必存在重复元素呢?元素去重之后就等同于形式三,所以这种情况不用考虑。
-### 一、子集
+上面用组合问题举的例子,但排列、组合、子集问题都可以有这三种基本形式,所以共有 9 种变化。
-问题很简单,输入一个**不包含重复数字**的数组,要求算法输出这些数字的所有子集。
+除此之外,题目也可以再添加各种限制条件,比如让你求和为 `target` 且元素个数为 `k` 的组合,那这么一来又可以衍生出一堆变体,怪不得面试笔试中经常考到排列组合这种基本题型。
-```cpp
-vector> subsets(vector& nums);
+**但无论形式怎么变化,其本质就是穷举所有解,而这些解呈现树形结构,所以合理使用回溯算法框架,稍改代码框架即可把这些问题一网打尽**。
+
+具体来说,你需要先阅读并理解前文 [回溯算法核心套路](https://labuladong.github.io/article/fname.html?fname=回溯算法详解修订版),然后记住如下子集问题和排列问题的回溯树,就可以解决所有排列组合子集相关的问题:
+
+
+
+
+
+为什么只要记住这两种树形结构就能解决所有相关问题呢?
+
+**首先,组合问题和子集问题其实是等价的,这个后面会讲;至于之前说的三种变化形式,无非是在这两棵树上剪掉或者增加一些树枝罢了**。
+
+那么,接下来我们就开始穷举,把排列/组合/子集问题的 9 种形式都过一遍,学学如何用回溯算法把它们一套带走。
+
+### 子集(元素无重不可复选)
+
+力扣第 78 题「子集」就是这个问题:
+
+题目给你输入一个无重复元素的数组 `nums`,其中每个元素最多使用一次,请你返回 `nums` 的所有子集。
+
+函数签名如下:
+
+```java
+List> subsets(int[] nums)
```
-比如输入 `nums = [1,2,3]`,你的算法应输出 8 个子集,包含空集和本身,顺序可以不同:
+比如输入 `nums = [1,2,3]`,算法应该返回如下子集:
-[ [],[1],[2],[3],[1,3],[2,3],[1,2],[1,2,3] ]
+```java
+[ [],[1],[2],[3],[1,2],[1,3],[2,3],[1,2,3] ]
+```
-**第一个解法是利用数学归纳的思想**:假设我现在知道了规模更小的子问题的结果,如何推导出当前问题的结果呢?
+好,我们暂时不考虑如何用代码实现,先回忆一下我们的高中知识,如何手推所有子集?
-具体来说就是,现在让你求 `[1,2,3]` 的子集,如果你知道了 `[1,2]` 的子集,是否可以推导出 `[1,2,3]` 的子集呢?先把 `[1,2]` 的子集写出来瞅瞅:
+首先,生成元素个数为 0 的子集,即空集 `[]`,为了方便表示,我称之为 `S_0`。
-[ [],[1],[2],[1,2] ]
+然后,在 `S_0` 的基础上生成元素个数为 1 的所有子集,我称为 `S_1`:
-你会发现这样一个规律:
+
-subset(`[1,2,3]`) - subset(`[1,2]`)
+接下来,我们可以在 `S_1` 的基础上推导出 `S_2`,即元素个数为 2 的所有子集:
-= [3],[1,3],[2,3],[1,2,3]
+
-而这个结果,就是把 sebset(`[1,2]`) 的结果中每个集合再添加上 3。
+为什么集合 `[2]` 只需要添加 `3`,而不添加前面的 `1` 呢?
-换句话说,如果 `A = subset([1,2])` ,那么:
+因为集合中的元素不用考虑顺序, `[1,2,3]` 中 `2` 后面只有 `3`,如果你向前考虑 `1`,那么 `[2,1]` 会和之前已经生成的子集 `[1,2]` 重复。
-subset(`[1,2,3]`)
+**换句话说,我们通过保证元素之间的相对顺序不变来防止出现重复的子集**。
-= A + [A[i].add(3) for i = 1..len(A)]
+接着,我们可以通过 `S_2` 推出 `S_3`,实际上 `S_3` 中只有一个集合 `[1,2,3]`,它是通过 `[1,2]` 推出的。
-这就是一个典型的递归结构嘛,`[1,2,3]` 的子集可以由 `[1,2]` 追加得出,`[1,2]` 的子集可以由 `[1]` 追加得出,base case 显然就是当输入集合为空集时,输出子集也就是一个空集。
+整个推导过程就是这样一棵树:
-翻译成代码就很容易理解了:
+
-```cpp
-vector> subsets(vector& nums) {
- // base case,返回一个空集
- if (nums.empty()) return {{}};
- // 把最后一个元素拿出来
- int n = nums.back();
- nums.pop_back();
- // 先递归算出前面元素的所有子集
- vector> res = subsets(nums);
+注意这棵树的特性:
- int size = res.size();
- for (int i = 0; i < size; i++) {
- // 然后在之前的结果之上追加
- res.push_back(res[i]);
- res.back().push_back(n);
- }
+**如果把根节点作为第 0 层,将每个节点和根节点之间树枝上的元素作为该节点的值,那么第 `n` 层的所有节点就是大小为 `n` 的所有子集**。
+
+你比如大小为 2 的子集就是这一层节点的值:
+
+
+
+> **PS:注意,本文之后所说「节点的值」都是指节点和根节点之间树枝上的元素,且将根节点认为是第 0 层**。
+
+那么再进一步,如果想计算所有子集,那只要遍历这棵多叉树,把所有节点的值收集起来不就行了?
+
+直接看代码:
+
+```java
+List> res = new LinkedList<>();
+// 记录回溯算法的递归路径
+LinkedList track = new LinkedList<>();
+
+// 主函数
+public List> subsets(int[] nums) {
+ backtrack(nums, 0);
return res;
}
+
+// 回溯算法核心函数,遍历子集问题的回溯树
+void backtrack(int[] nums, int start) {
+
+ // 前序位置,每个节点的值都是一个子集
+ res.add(new LinkedList<>(track));
+
+ // 回溯算法标准框架
+ for (int i = start; i < nums.length; i++) {
+ // 做选择
+ track.addLast(nums[i]);
+ // 通过 start 参数控制树枝的遍历,避免产生重复的子集
+ backtrack(nums, i + 1);
+ // 撤销选择
+ track.removeLast();
+ }
+}
```
-**这个问题的时间复杂度计算比较容易坑人**。我们之前说的计算递归算法时间复杂度的方法,是找到递归深度,然后乘以每次递归中迭代的次数。对于这个问题,递归深度显然是 N,但我们发现每次递归 for 循环的迭代次数取决于 `res` 的长度,并不是固定的。
+看过前文 [回溯算法核心框架](https://labuladong.github.io/article/fname.html?fname=回溯算法详解修订版) 的读者应该很容易理解这段代码吧,我们使用 `start` 参数控制树枝的生长避免产生重复的子集,用 `track` 记录根节点到每个节点的路径的值,同时在前序位置把每个节点的路径值收集起来,完成回溯树的遍历就收集了所有子集:
-根据刚才的思路,`res` 的长度应该是每次递归都翻倍,所以说总的迭代次数应该是 2^N。或者不用这么麻烦,你想想一个大小为 N 的集合的子集总共有几个?2^N 个对吧,所以说至少要对 `res` 添加 2^N 次元素。
+
-那么算法的时间复杂度就是 O(2^N) 吗?还是不对,2^N 个子集是 `push_back` 添加进 `res` 的,所以要考虑 `push_back` 这个操作的效率:
+最后,`backtrack` 函数开头看似没有 base case,会不会进入无限递归?
-```cpp
-for (int i = 0; i < size; i++) {
- res.push_back(res[i]); // O(N)
- res.back().push_back(n); // O(1)
-}
-```
+其实不会的,当 `start == nums.length` 时,叶子节点的值会被装入 `res`,但 for 循环不会执行,也就结束了递归。
-因为 `res[i]` 也是一个数组呀,`push_back` 是把 `res[i]` copy 一份然后添加到数组的最后,所以一次操作的时间是 O(N)。
+### 组合(元素无重不可复选)
-综上,总的时间复杂度就是 O(N*2^N),还是比较耗时的。
+如果你能够成功的生成所有无重子集,那么你稍微改改代码就能生成所有无重组合了。
-空间复杂度的话,如果不计算储存返回结果所用的空间的,只需要 O(N) 的递归堆栈空间。如果计算 `res` 所需的空间,应该是 O(N*2^N)。
+你比如说,让你在 `nums = [1,2,3]` 中拿 2 个元素形成所有的组合,你怎么做?
-**第二种通用方法就是回溯算法**。旧文「回溯算法详解」写过回溯算法的模板:
+稍微想想就会发现,大小为 2 的所有组合,不就是所有大小为 2 的子集嘛。
-```python
-result = []
-def backtrack(路径, 选择列表):
- if 满足结束条件:
- result.add(路径)
- return
- for 选择 in 选择列表:
- 做选择
- backtrack(路径, 选择列表)
- 撤销选择
+**所以我说组合和子集是一样的:大小为 `k` 的组合就是大小为 `k` 的子集**。
+
+比如力扣第 77 题「组合」:
+
+给定两个整数 `n` 和 `k`,返回范围 `[1, n]` 中所有可能的 `k` 个数的组合。
+
+函数签名如下:
+
+```java
+List> combine(int n, int k)
+```
+
+比如 `combine(3, 2)` 的返回值应该是:
+
+```java
+[ [1,2],[1,3],[2,3] ]
```
-只要改造回溯算法的模板就行了:
+这是标准的组合问题,但我给你翻译一下就变成子集问题了:
+
+**给你输入一个数组 `nums = [1,2..,n]` 和一个正整数 `k`,请你生成所有大小为 `k` 的子集**。
+
+还是以 `nums = [1,2,3]` 为例,刚才让你求所有子集,就是把所有节点的值都收集起来;**现在你只需要把第 2 层(根节点视为第 0 层)的节点收集起来,就是大小为 2 的所有组合**:
+
+
-```cpp
-vector> res;
+反映到代码上,只需要稍改 base case,控制算法仅仅收集第 `k` 层节点的值即可:
-vector> subsets(vector& nums) {
- // 记录走过的路径
- vector track;
- backtrack(nums, 0, track);
+```java
+List> res = new LinkedList<>();
+// 记录回溯算法的递归路径
+LinkedList track = new LinkedList<>();
+
+// 主函数
+public List> combine(int n, int k) {
+ backtrack(1, n, k);
return res;
}
-void backtrack(vector& nums, int start, vector& track) {
- res.push_back(track);
- for (int i = start; i < nums.size(); i++) {
- // 做选择
- track.push_back(nums[i]);
- // 回溯
- backtrack(nums, i + 1, track);
+void backtrack(int start, int n, int k) {
+ // base case
+ if (k == track.size()) {
+ // 遍历到了第 k 层,收集当前节点的值
+ res.add(new LinkedList<>(track));
+ return;
+ }
+
+ // 回溯算法标准框架
+ for (int i = start; i <= n; i++) {
+ // 选择
+ track.addLast(i);
+ // 通过 start 参数控制树枝的遍历,避免产生重复的子集
+ backtrack(i + 1, n, k);
// 撤销选择
- track.pop_back();
+ track.removeLast();
}
}
```
-可以看见,对 `res` 更新的位置处在前序遍历,也就是说,**`res` 就是树上的所有节点**:
+这样,标准的子集问题也解决了。
+
+### 排列(元素无重不可复选)
-
+排列问题在前文 [回溯算法核心框架](https://labuladong.github.io/article/fname.html?fname=回溯算法详解修订版) 讲过,这里就简单过一下。
+力扣第 46 题「全排列」就是标准的排列问题:
-### 二、组合
+给定一个**不含重复数字**的数组 `nums`,返回其所有可能的**全排列**。
-输入两个数字 `n, k`,算法输出 `[1..n]` 中 k 个数字的所有组合。
+函数签名如下:
-```cpp
-vector> combine(int n, int k);
+```java
+List> permute(int[] nums)
```
-比如输入 `n = 4, k = 2`,输出如下结果,顺序无所谓,但是不能包含重复(按照组合的定义,`[1,2]` 和 `[2,1]` 也算重复):
+比如输入 `nums = [1,2,3]`,函数的返回值应该是:
+```java
[
- [1,2],
- [1,3],
- [1,4],
- [2,3],
- [2,4],
- [3,4]
+ [1,2,3],[1,3,2],
+ [2,1,3],[2,3,1],
+ [3,1,2],[3,2,1]
]
+```
-这也是典型的回溯算法,`k` 限制了树的高度,`n` 限制了树的宽度,继续套我们以前讲过的回溯算法模板框架就行了:
+刚才讲的组合/子集问题使用 `start` 变量保证元素 `nums[start]` 之后只会出现 `nums[start+1..]` 中的元素,通过固定元素的相对位置保证不出现重复的子集。
-
+**但排列问题本身就是让你穷举元素的位置,`nums[i]` 之后也可以出现 `nums[i]` 左边的元素,所以之前的那一套玩不转了,需要额外使用 `used` 数组来标记哪些元素还可以被选择**。
-```cpp
-vector>res;
+标准全排列可以抽象成如下这棵多叉树:
-vector> combine(int n, int k) {
- if (k <= 0 || n <= 0) return res;
- vector track;
- backtrack(n, k, 1, track);
+
+
+我们用 `used` 数组标记已经在路径上的元素避免重复选择,然后收集所有叶子节点上的值,就是所有全排列的结果:
+
+```java
+List> res = new LinkedList<>();
+// 记录回溯算法的递归路径
+LinkedList track = new LinkedList<>();
+// track 中的元素会被标记为 true
+boolean[] used;
+
+/* 主函数,输入一组不重复的数字,返回它们的全排列 */
+public List> permute(int[] nums) {
+ used = new boolean[nums.length];
+ backtrack(nums);
return res;
}
-void backtrack(int n, int k, int start, vector& track) {
- // 到达树的底部
- if (k == track.size()) {
- res.push_back(track);
+// 回溯算法核心函数
+void backtrack(int[] nums) {
+ // base case,到达叶子节点
+ if (track.size() == nums.length) {
+ // 收集叶子节点上的值
+ res.add(new LinkedList(track));
return;
}
- // 注意 i 从 start 开始递增
- for (int i = start; i <= n; i++) {
+
+ // 回溯算法标准框架
+ for (int i = 0; i < nums.length; i++) {
+ // 已经存在 track 中的元素,不能重复选择
+ if (used[i]) {
+ continue;
+ }
// 做选择
- track.push_back(i);
- backtrack(n, k, i + 1, track);
- // 撤销选择
- track.pop_back();
+ used[i] = true;
+ track.addLast(nums[i]);
+ // 进入下一层回溯树
+ backtrack(nums);
+ // 取消选择
+ track.removeLast();
+ used[i] = false;
}
}
```
-`backtrack` 函数和计算子集的差不多,区别在于,更新 `res` 的时机是树到达底端时。
+这样,全排列问题就解决了。
-### 三、排列
+但如果题目不让你算全排列,而是让你算元素个数为 `k` 的排列,怎么算?
-输入一个**不包含重复数字**的数组 `nums`,返回这些数字的全部排列。
+也很简单,改下 `backtrack` 函数的 base case,仅收集第 `k` 层的节点值即可:
-```cpp
-vector> permute(vector& nums);
+```java
+// 回溯算法核心函数
+void backtrack(int[] nums, int k) {
+ // base case,到达第 k 层,收集节点的值
+ if (track.size() == k) {
+ // 第 k 层节点的值就是大小为 k 的排列
+ res.add(new LinkedList(track));
+ return;
+ }
+
+ // 回溯算法标准框架
+ for (int i = 0; i < nums.length; i++) {
+ // ...
+ backtrack(nums, k);
+ // ...
+ }
+}
```
-比如说输入数组 `[1,2,3]`,输出结果应该如下,顺序无所谓,不能有重复:
+### 子集/组合(元素可重不可复选)
-[
- [1,2,3],
- [1,3,2],
- [2,1,3],
- [2,3,1],
- [3,1,2],
- [3,2,1]
+刚才讲的标准子集问题输入的 `nums` 是没有重复元素的,但如果存在重复元素,怎么处理呢?
+
+力扣第 90 题「子集 II」就是这样一个问题:
+
+给你一个整数数组 `nums`,其中可能包含重复元素,请你返回该数组所有可能的子集。
+
+函数签名如下:
+
+```java
+List> subsetsWithDup(int[] nums)
+```
+
+比如输入 `nums = [1,2,2]`,你应该输出:
+
+```java
+[ [],[1],[2],[1,2],[2,2],[1,2,2] ]
+```
+
+当然,按道理说「集合」不应该包含重复元素的,但既然题目这样问了,我们就忽略这个细节吧,仔细思考一下这道题怎么做才是正事。
+
+就以 `nums = [1,2,2]` 为例,为了区别两个 `2` 是不同元素,后面我们写作 `nums = [1,2,2']`。
+
+按照之前的思路画出子集的树形结构,显然,两条值相同的相邻树枝会产生重复:
+
+
+
+```
+[
+ [],
+ [1],[2],[2'],
+ [1,2],[1,2'],[2,2'],
+ [1,2,2']
]
+```
+
+所以我们需要进行剪枝,如果一个节点有多条值相同的树枝相邻,则只遍历第一条,剩下的都剪掉,不要去遍历:
-「回溯算法详解」中就是拿这个问题来解释回溯模板的。这里又列出这个问题,是将「排列」和「组合」这两个回溯算法的代码拿出来对比。
+
-首先画出回溯树来看一看:
+**体现在代码上,需要先进行排序,让相同的元素靠在一起,如果发现 `nums[i] == nums[i-1]`,则跳过**:
-
+```java
+List> res = new LinkedList<>();
+LinkedList track = new LinkedList<>();
+
+public List> subsetsWithDup(int[] nums) {
+ // 先排序,让相同的元素靠在一起
+ Arrays.sort(nums);
+ backtrack(nums, 0);
+ return res;
+}
+
+void backtrack(int[] nums, int start) {
+ // 前序位置,每个节点的值都是一个子集
+ res.add(new LinkedList<>(track));
+
+ for (int i = start; i < nums.length; i++) {
+ // 剪枝逻辑,值相同的相邻树枝,只遍历第一条
+ if (i > start && nums[i] == nums[i - 1]) {
+ continue;
+ }
+ track.addLast(nums[i]);
+ backtrack(nums, i + 1);
+ track.removeLast();
+ }
+}
+```
+
+这段代码和之前标准的子集问题的代码几乎相同,就是添加了排序和剪枝的逻辑。
+
+至于为什么要这样剪枝,结合前面的图应该也很容易理解,这样带重复元素的子集问题也解决了。
+
+**我们说了组合问题和子集问题是等价的**,所以我们直接看一道组合的题目吧,这是力扣第 40 题「组合总和 II」:
+
+给你输入 `candidates` 和一个目标和 `target`,从 `candidates` 中找出中所有和为 `target` 的组合。
+
+`candidates` 可能存在重复元素,且其中的每个数字最多只能使用一次。
-我们当时使用 Java 代码写的解法:
+说这是一个组合问题,其实换个问法就变成子集问题了:请你计算 `candidates` 中所有和为 `target` 的子集。
+
+所以这题怎么做呢?
+
+对比子集问题的解法,只要额外用一个 `trackSum` 变量记录回溯路径上的元素和,然后将 base case 改一改即可解决这道题:
```java
List> res = new LinkedList<>();
+// 记录回溯的路径
+LinkedList track = new LinkedList<>();
+// 记录 track 中的元素之和
+int trackSum = 0;
+
+public List> combinationSum2(int[] candidates, int target) {
+ if (candidates.length == 0) {
+ return res;
+ }
+ // 先排序,让相同的元素靠在一起
+ Arrays.sort(candidates);
+ backtrack(candidates, 0, target);
+ return res;
+}
-/* 主函数,输入一组不重复的数字,返回它们的全排列 */
-List> permute(int[] nums) {
- // 记录「路径」
- LinkedList track = new LinkedList<>();
- backtrack(nums, track);
+// 回溯算法主函数
+void backtrack(int[] nums, int start, int target) {
+ // base case,达到目标和,找到符合条件的组合
+ if (trackSum == target) {
+ res.add(new LinkedList<>(track));
+ return;
+ }
+ // base case,超过目标和,直接结束
+ if (trackSum > target) {
+ return;
+ }
+
+ // 回溯算法标准框架
+ for (int i = start; i < nums.length; i++) {
+ // 剪枝逻辑,值相同的树枝,只遍历第一条
+ if (i > start && nums[i] == nums[i - 1]) {
+ continue;
+ }
+ // 做选择
+ track.add(nums[i]);
+ trackSum += nums[i];
+ // 递归遍历下一层回溯树
+ backtrack(nums, i + 1, target);
+ // 撤销选择
+ track.removeLast();
+ trackSum -= nums[i];
+ }
+}
+```
+
+### 排列(元素可重不可复选)
+
+排列问题的输入如果存在重复,比子集/组合问题稍微复杂一点,我们看看力扣第 47 题「全排列 II」:
+
+给你输入一个可包含重复数字的序列 `nums`,请你写一个算法,返回所有可能的全排列,函数签名如下:
+
+```java
+List> permuteUnique(int[] nums)
+```
+
+比如输入 `nums = [1,2,2]`,函数返回:
+
+```java
+[ [1,2,2],[2,1,2],[2,2,1] ]
+```
+
+先看解法代码:
+
+```java
+List> res = new LinkedList<>();
+LinkedList track = new LinkedList<>();
+boolean[] used;
+
+public List> permuteUnique(int[] nums) {
+ // 先排序,让相同的元素靠在一起
+ Arrays.sort(nums);
+ used = new boolean[nums.length];
+ backtrack(nums);
return res;
}
+void backtrack(int[] nums) {
+ if (track.size() == nums.length) {
+ res.add(new LinkedList(track));
+ return;
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ if (used[i]) {
+ continue;
+ }
+ // 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置
+ if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
+ continue;
+ }
+ track.add(nums[i]);
+ used[i] = true;
+ backtrack(nums);
+ track.removeLast();
+ used[i] = false;
+ }
+}
+```
+
+你对比一下之前的标准全排列解法代码,这段解法代码只有两处不同:
+
+1、对 `nums` 进行了排序。
+
+2、添加了一句额外的剪枝逻辑。
+
+类比输入包含重复元素的子集/组合问题,你大概应该理解这么做是为了防止出现重复结果。
+
+但是注意排列问题的剪枝逻辑,和子集/组合问题的剪枝逻辑略有不同:新增了 `!used[i - 1]` 的逻辑判断。
+
+这个地方理解起来就需要一些技巧性了,且听我慢慢到来。为了方便研究,依然把相同的元素用上标 `'` 以示区别。
+
+假设输入为 `nums = [1,2,2']`,标准的全排列算法会得出如下答案:
+
+```
+[
+ [1,2,2'],[1,2',2],
+ [2,1,2'],[2,2',1],
+ [2',1,2],[2',2,1]
+]
+```
+
+显然,这个结果存在重复,比如 `[1,2,2']` 和 `[1,2',2]` 应该只被算作同一个排列,但被算作了两个不同的排列。
+
+所以现在的关键在于,如何设计剪枝逻辑,把这种重复去除掉?
+
+**答案是,保证相同元素在排列中的相对位置保持不变**。
+
+比如说 `nums = [1,2,2']` 这个例子,我保持排列中 `2` 一直在 `2'` 前面。
+
+这样的话,你从上面 6 个排列中只能挑出 3 个排列符合这个条件:
+
+```
+[ [1,2,2'],[2,1,2'],[2,2',1] ]
+```
+
+这也就是正确答案。
+
+进一步,如果 `nums = [1,2,2',2'']`,我只要保证重复元素 `2` 的相对位置固定,比如说 `2 -> 2' -> 2''`,也可以得到无重复的全排列结果。
+
+仔细思考,应该很容易明白其中的原理:
+
+**标准全排列算法之所以出现重复,是因为把相同元素形成的排列序列视为不同的序列,但实际上它们应该是相同的;而如果固定相同元素形成的序列顺序,当然就避免了重复**。
+
+那么反映到代码上,你注意看这个剪枝逻辑:
+
+```java
+// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置
+if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
+ // 如果前面的相邻相等元素没有用过,则跳过
+ continue;
+}
+// 选择 nums[i]
+```
+
+**当出现重复元素时,比如输入 `nums = [1,2,2',2'']`,`2'` 只有在 `2` 已经被使用的情况下才会被选择,同理,`2''` 只有在 `2'` 已经被使用的情况下才会被选择,这就保证了相同元素在排列中的相对位置保证固定**。
+
+这里拓展一下,如果你把上述剪枝逻辑中的 `!used[i - 1]` 改成 `used[i - 1]`,其实也可以通过所有测试用例,但效率会有所下降,这是为什么呢?
+
+之所以这样修改不会产生错误,是因为这种写法相当于维护了 `2'' -> 2' -> 2` 的相对顺序,最终也可以实现去重的效果。
+
+但为什么这样写效率会下降呢?因为这个写法剪掉的树枝不够多。
+
+比如输入 `nums = [2,2',2'']`,产生的回溯树如下:
+
+
+
+如果用绿色树枝代表 `backtrack` 函数遍历过的路径,红色树枝代表剪枝逻辑的触发,那么 `!used[i - 1]` 这种剪枝逻辑得到的回溯树长这样:
+
+
+
+而 `used[i - 1]` 这种剪枝逻辑得到的回溯树如下:
+
+
+
+可以看到,`!used[i - 1]` 这种剪枝逻辑剪得干净利落,而 `used[i - 1]` 这种剪枝逻辑虽然也能得到无重结果,但它剪掉的树枝较少,存在的无效计算较多,所以效率会差一些。
+
+当然,关于排列去重,也有读者提出别的剪枝思路:
+
+```java
void backtrack(int[] nums, LinkedList track) {
- // 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
-
+
+ // 记录之前树枝上元素的值
+ // 题目说 -10 <= nums[i] <= 10,所以初始化为特殊值
+ int prevNum = -666;
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
- if (track.contains(nums[i]))
+ if (used[i]) {
continue;
- // 做选择
+ }
+ if (nums[i] == prevNum) {
+ continue;
+ }
+
track.add(nums[i]);
- // 进入下一层决策树
+ used[i] = true;
+ // 记录这条树枝上的值
+ prevNum = nums[i];
+
backtrack(nums, track);
+
+ track.removeLast();
+ used[i] = false;
+ }
+}
+```
+
+这个思路也是对的,设想一个节点出现了相同的树枝:
+
+
+
+如果不作处理,这些相同树枝下面的子树也会长得一模一样,所以会出现重复的排列。
+
+因为排序之后所有相等的元素都挨在一起,所以只要用 `prevNum` 记录前一条树枝的值,就可以避免遍历值相同的树枝,从而避免产生相同的子树,最终避免出现重复的排列。
+
+好了,这样包含重复输入的排列问题也解决了。
+
+### 子集/组合(元素无重可复选)
+
+终于到了最后一种类型了:输入数组无重复元素,但每个元素可以被无限次使用。
+
+直接看力扣第 39 题「组合总和」:
+
+给你一个无重复元素的整数数组 `candidates` 和一个目标和 `target`,找出 `candidates` 中可以使数字和为目标数 `target` 的所有组合。`candidates` 中的每个数字可以无限制重复被选取。
+
+函数签名如下:
+
+```java
+List> combinationSum(int[] candidates, int target)
+```
+
+比如输入 `candidates = [1,2,3], target = 3`,算法应该返回:
+
+```
+[ [1,1,1],[1,2],[3] ]
+```
+
+这道题说是组合问题,实际上也是子集问题:`candidates` 的哪些子集的和为 `target`?
+
+想解决这种类型的问题,也得回到回溯树上,**我们不妨先思考思考,标准的子集/组合问题是如何保证不重复使用元素的**?
+
+答案在于 `backtrack` 递归时输入的参数 `start`:
+
+```java
+// 无重组合的回溯算法框架
+void backtrack(int[] nums, int start) {
+ for (int i = start; i < nums.length; i++) {
+ // ...
+ // 递归遍历下一层回溯树,注意参数
+ backtrack(nums, i + 1);
+ // ...
+ }
+}
+```
+
+这个 `i` 从 `start` 开始,那么下一层回溯树就是从 `start + 1` 开始,从而保证 `nums[start]` 这个元素不会被重复使用:
+
+
+
+那么反过来,如果我想让每个元素被重复使用,我只要把 `i + 1` 改成 `i` 即可:
+
+```java
+// 可重组合的回溯算法框架
+void backtrack(int[] nums, int start) {
+ for (int i = start; i < nums.length; i++) {
+ // ...
+ // 递归遍历下一层回溯树,注意参数
+ backtrack(nums, i);
+ // ...
+ }
+}
+```
+
+这相当于给之前的回溯树添加了一条树枝,在遍历这棵树的过程中,一个元素可以被无限次使用:
+
+
+
+当然,这样这棵回溯树会永远生长下去,所以我们的递归函数需要设置合适的 base case 以结束算法,即路径和大于 `target` 时就没必要再遍历下去了。
+
+这道题的解法代码如下:
+
+```java
+List> res = new LinkedList<>();
+// 记录回溯的路径
+LinkedList track = new LinkedList<>();
+// 记录 track 中的路径和
+int trackSum = 0;
+
+public List> combinationSum(int[] candidates, int target) {
+ if (candidates.length == 0) {
+ return res;
+ }
+ backtrack(candidates, 0, target);
+ return res;
+}
+
+// 回溯算法主函数
+void backtrack(int[] nums, int start, int target) {
+ // base case,找到目标和,记录结果
+ if (trackSum == target) {
+ res.add(new LinkedList<>(track));
+ return;
+ }
+ // base case,超过目标和,停止向下遍历
+ if (trackSum > target) {
+ return;
+ }
+
+ // 回溯算法标准框架
+ for (int i = start; i < nums.length; i++) {
+ // 选择 nums[i]
+ trackSum += nums[i];
+ track.add(nums[i]);
+ // 递归遍历下一层回溯树
+ // 同一元素可重复使用,注意参数
+ backtrack(nums, i, target);
+ // 撤销选择 nums[i]
+ trackSum -= nums[i];
+ track.removeLast();
+ }
+}
+```
+
+### 排列(元素无重可复选)
+
+力扣上没有类似的题目,我们不妨先想一下,`nums` 数组中的元素无重复且可复选的情况下,会有哪些排列?
+
+比如输入 `nums = [1,2,3]`,那么这种条件下的全排列共有 3^3 = 27 种:
+
+```java
+[
+ [1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3],
+ [2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3],
+ [3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3]
+]
+```
+
+**标准的全排列算法利用 `used` 数组进行剪枝,避免重复使用同一个元素。如果允许重复使用元素的话,直接放飞自我,去除所有 `used` 数组的剪枝逻辑就行了**。
+
+那这个问题就简单了,代码如下:
+
+```java
+List> res = new LinkedList<>();
+LinkedList track = new LinkedList<>();
+
+public List> permuteRepeat(int[] nums) {
+ backtrack(nums);
+ return res;
+}
+
+// 回溯算法核心函数
+void backtrack(int[] nums) {
+ // base case,到达叶子节点
+ if (track.size() == nums.length) {
+ // 收集叶子节点上的值
+ res.add(new LinkedList(track));
+ return;
+ }
+
+ // 回溯算法标准框架
+ for (int i = 0; i < nums.length; i++) {
+ // 做选择
+ track.add(nums[i]);
+ // 进入下一层回溯树
+ backtrack(nums);
// 取消选择
track.removeLast();
}
}
```
-回溯模板依然没有变,但是根据排列问题和组合问题画出的树来看,排列问题的树比较对称,而组合问题的树越靠右节点越少。
+至此,排列/组合/子集问题的九种变化就都讲完了。
+
+### 最后总结
+
+来回顾一下排列/组合/子集问题的三种形式在代码上的区别。
+
+由于子集问题和组合问题本质上是一样的,无非就是 base case 有一些区别,所以把这两个问题放在一起看。
+
+**形式一、元素无重不可复选,即 `nums` 中的元素都是唯一的,每个元素最多只能被使用一次**,`backtrack` 核心代码如下:
+
+```java
+/* 组合/子集问题回溯算法框架 */
+void backtrack(int[] nums, int start) {
+ // 回溯算法标准框架
+ for (int i = start; i < nums.length; i++) {
+ // 做选择
+ track.addLast(nums[i]);
+ // 注意参数
+ backtrack(nums, i + 1);
+ // 撤销选择
+ track.removeLast();
+ }
+}
+
+/* 排列问题回溯算法框架 */
+void backtrack(int[] nums) {
+ for (int i = 0; i < nums.length; i++) {
+ // 剪枝逻辑
+ if (used[i]) {
+ continue;
+ }
+ // 做选择
+ used[i] = true;
+ track.addLast(nums[i]);
+
+ backtrack(nums);
+ // 撤销选择
+ track.removeLast();
+ used[i] = false;
+ }
+}
+```
+
+**形式二、元素可重不可复选,即 `nums` 中的元素可以存在重复,每个元素最多只能被使用一次**,其关键在于排序和剪枝,`backtrack` 核心代码如下:
+
+```java
+Arrays.sort(nums);
+/* 组合/子集问题回溯算法框架 */
+void backtrack(int[] nums, int start) {
+ // 回溯算法标准框架
+ for (int i = start; i < nums.length; i++) {
+ // 剪枝逻辑,跳过值相同的相邻树枝
+ if (i > start && nums[i] == nums[i - 1]) {
+ continue;
+ }
+ // 做选择
+ track.addLast(nums[i]);
+ // 注意参数
+ backtrack(nums, i + 1);
+ // 撤销选择
+ track.removeLast();
+ }
+}
+
+
+Arrays.sort(nums);
+/* 排列问题回溯算法框架 */
+void backtrack(int[] nums) {
+ for (int i = 0; i < nums.length; i++) {
+ // 剪枝逻辑
+ if (used[i]) {
+ continue;
+ }
+ // 剪枝逻辑,固定相同的元素在排列中的相对位置
+ if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
+ continue;
+ }
+ // 做选择
+ used[i] = true;
+ track.addLast(nums[i]);
-在代码中的体现就是,排列问题每次通过 `contains` 方法来排除在 `track` 中已经选择过的数字;而组合问题通过传入一个 `start` 参数,来排除 `start` 索引之前的数字。
+ backtrack(nums);
+ // 撤销选择
+ track.removeLast();
+ used[i] = false;
+ }
+}
+```
-**以上,就是排列组合和子集三个问题的解法,总结一下**:
+**形式三、元素无重可复选,即 `nums` 中的元素都是唯一的,每个元素可以被使用若干次**,只要删掉去重逻辑即可,`backtrack` 核心代码如下:
-子集问题可以利用数学归纳思想,假设已知一个规模较小的问题的结果,思考如何推导出原问题的结果。也可以用回溯算法,要用 `start` 参数排除已选择的数字。
+```java
+/* 组合/子集问题回溯算法框架 */
+void backtrack(int[] nums, int start) {
+ // 回溯算法标准框架
+ for (int i = start; i < nums.length; i++) {
+ // 做选择
+ track.addLast(nums[i]);
+ // 注意参数
+ backtrack(nums, i);
+ // 撤销选择
+ track.removeLast();
+ }
+}
-组合问题利用的是回溯思想,结果可以表示成树结构,我们只要套用回溯算法模板即可,关键点在于要用一个 `start` 排除已经选择过的数字。
-排列问题是回溯思想,也可以表示成树结构套用算法模板,关键点在于使用 `contains` 方法排除已经选择的数字,前文有详细分析,这里主要是和组合问题作对比。
+/* 排列问题回溯算法框架 */
+void backtrack(int[] nums) {
+ for (int i = 0; i < nums.length; i++) {
+ // 做选择
+ track.addLast(nums[i]);
+ backtrack(nums);
+ // 撤销选择
+ track.removeLast();
+ }
+}
+```
-记住这几种树的形状,就足以应对大部分回溯算法问题了,无非就是 `start` 或者 `contains` 剪枝,也没啥别的技巧了。
+只要从树的角度思考,这些问题看似复杂多变,实则改改 base case 就能解决,这也是为什么我在 [学习算法和数据结构的框架思维](https://labuladong.github.io/article/fname.html?fname=学习数据结构和算法的高效方法) 和 [手把手刷二叉树(纲领篇)](https://labuladong.github.io/article/fname.html?fname=二叉树总结) 中强调树类型题目重要性的原因。
+如果你能够看到这里,真得给你鼓掌,相信你以后遇到各种乱七八糟的算法题,也能一眼看透它们的本质,以不变应万变。另外,考虑到篇幅,本文并没有对这些算法进行复杂度的分析,你可以使用我在 [算法时空复杂度分析实用指南](https://labuladong.github.io/article/fname.html?fname=时间复杂度) 讲到的复杂度分析方法尝试自己分析它们的复杂度。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
+
-
-
-
======其他语言代码======
[78.子集](https://leetcode-cn.com/problems/subsets)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\272\247\344\275\215\350\260\203\345\272\246.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\272\247\344\275\215\350\260\203\345\272\246.md"
index d95b521b4bdc6b41d3f8642aa6a809321c30db8b..c917443743048e8e262785b1607e1477867aadcd 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\272\247\344\275\215\350\260\203\345\272\246.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\345\272\247\344\275\215\350\260\203\345\272\246.md"
@@ -1,24 +1,31 @@
# 如何调度考生的座位
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[855.考场就座](https://leetcode-cn.com/problems/exam-room)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [855. Exam Room](https://leetcode.com/problems/exam-room/) | [855. 考场就座](https://leetcode.cn/problems/exam-room/) | 🟠
**-----------**
-这是 LeetCode 第 855 题,有趣且具有一定技巧性。这种题目并不像动态规划这类算法拼智商,而是看你对常用数据结构的理解和写代码的水平,个人认为值得重视和学习。
+本文讲一讲力扣第 855 题「考场就座」,有趣且具有一定技巧性。这种题目并不像动态规划这类算法拼智商,而是看你对常用数据结构的理解和写代码的水平,个人认为值得重视和学习。
另外说句题外话,很多读者都问,算法框架是如何总结出来的,其实框架反而是慢慢从细节里抠出来的。希望大家看了我们的文章之后,最好能抽时间把相关的问题亲自做一做,纸上得来终觉浅,绝知此事要躬行嘛。
@@ -128,7 +135,7 @@ private int distance(int[] intv) {
「虚拟线段」其实就是为了将所有座位表示为一个线段:
-
+
有了上述铺垫,主要 API `seat` 和 `leave` 就可以写了:
@@ -167,7 +174,7 @@ public void leave(int p) {
}
```
-
+
至此,算法就基本实现了,代码虽多,但思路很简单:找最长的线段,从中间分隔成两段,中点就是 `seat()` 的返回值;找 `p` 的左右线段,合并成一个线段,这就是 `leave(p)` 的逻辑。
@@ -175,11 +182,11 @@ public void leave(int p) {
但是,题目要求多个选择时选择索引最小的那个座位,我们刚才忽略了这个问题。比如下面这种情况会出错:
-
+
现在有序集合里有线段 `[0,4]` 和 `[4,9]`,那么最长线段 `longest` 就是后者,按照 `seat` 的逻辑,就会分割 `[4,9]`,也就是返回座位 6。但正确答案应该是座位 2,因为 2 和 6 都满足最大化相邻考生距离的条件,二者应该取较小的。
-
+
**遇到题目的这种要求,解决方式就是修改有序数据结构的排序方式**。具体到这个问题,就是修改 `TreeMap` 的比较函数逻辑:
@@ -207,7 +214,7 @@ private int distance(int[] intv) {
}
```
-
+
这样,`[0,4]` 和 `[4,9]` 的 `distance` 值就相等了,算法会比较二者的索引,取较小的线段进行分割。到这里,这道算法题目算是完全解决了。
@@ -217,19 +224,17 @@ private int distance(int[] intv) {
处理动态问题一般都会用到有序数据结构,比如平衡二叉搜索树和二叉堆,二者的时间复杂度差不多,但前者支持的操作更多。
-既然平衡二叉搜索树这么好用,还用二叉堆干嘛呢?因为二叉堆底层就是数组,实现简单啊,详见旧文「二叉堆详解」。你实现个红黑树试试?操作复杂,而且消耗的空间相对来说会多一些。具体问题,还是要选择恰当的数据结构来解决。
+既然平衡二叉搜索树这么好用,还用二叉堆干嘛呢?因为二叉堆底层就是数组,实现简单啊,详见前文 [二叉堆详解](https://labuladong.github.io/article/fname.html?fname=二叉堆详解实现优先级队列)。你实现个红黑树试试?操作复杂,而且消耗的空间相对来说会多一些。具体问题,还是要选择恰当的数据结构来解决。
希望本文对大家有帮助。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[855.考场就座](https://leetcode-cn.com/problems/exam-room)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\211\223\345\215\260\347\264\240\346\225\260.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\211\223\345\215\260\347\264\240\346\225\260.md"
index 12820634b36ddf53ca69adbb9ea352a78b2ac829..27bfa2de953d6bdc8abc19ea846d5ea0e97ddbf7 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\211\223\345\215\260\347\264\240\346\225\260.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\211\223\345\215\260\347\264\240\346\225\260.md"
@@ -1,26 +1,35 @@
# 如何高效寻找素数
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[204.计数质数](https://leetcode-cn.com/problems/count-primes)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [204. Count Primes](https://leetcode.com/problems/count-primes/) | [204. 计数质数](https://leetcode.cn/problems/count-primes/) | 🟠
**-----------**
素数的定义看起来很简单,如果一个数如果只能被 1 和它本身整除,那么这个数就是素数。
-不要觉得素数的定义简单,恐怕没多少人真的能把素数相关的算法写得高效。比如让你写这样一个函数:
+虽然素数的定义并不复杂,恐怕没多少人真的能把素数相关的算法写得高效。
+
+比如力扣第 204 题「计数质数」,让你写这样一个函数:
```java
// 返回区间 [2, n) 中有几个素数
@@ -36,7 +45,7 @@ int countPrimes(int n)
int countPrimes(int n) {
int count = 0;
for (int i = 2; i < n; i++)
- if (isPrim(i)) count++;
+ if (isPrime(i)) count++;
return count;
}
@@ -52,7 +61,7 @@ boolean isPrime(int n) {
这样写的话时间复杂度 O(n^2),问题很大。**首先你用 isPrime 函数来辅助的思路就不够高效;而且就算你要用 isPrime 函数,这样写算法也是存在计算冗余的**。
-先来简单说下**如果你要判断一个数是不是素数,应该如何写算法**。只需稍微修改一下上面的 isPrim 代码中的 for 循环条件:
+先来简单说下**如果你要判断一个数是不是素数,应该如何写算法**。只需稍微修改一下上面的 isPrime 代码中的 for 循环条件:
```java
boolean isPrime(int n) {
@@ -77,32 +86,37 @@ boolean isPrime(int n) {
现在,`isPrime` 函数的时间复杂度降为 O(sqrt(N)),**但是我们实现 `countPrimes` 函数其实并不需要这个函数**,以上只是希望读者明白 `sqrt(n)` 的含义,因为等会还会用到。
-
### 高效实现 `countPrimes`
-高效解决这个问题的核心思路是和上面的常规思路反着来:
+接下来介绍的方法叫做「素数筛选法」,这个方法是古希腊一位名叫埃拉托色尼的大佬发明的,我们在中学的教课书上见过他的大名,因为他就是第一个通过物体的影子正确计算地球周长的人,被推崇为「地理学之父」。
+
+回到正题,素数筛选法的核心思路是和上面的常规思路反着来:
首先从 2 开始,我们知道 2 是一个素数,那么 2 × 2 = 4, 3 × 2 = 6, 4 × 2 = 8... 都不可能是素数了。
然后我们发现 3 也是素数,那么 3 × 2 = 6, 3 × 3 = 9, 3 × 4 = 12... 也都不可能是素数了。
+Wikipedia 的这个 GIF 很形象:
+
+
+
看到这里,你是否有点明白这个排除法的逻辑了呢?先看我们的第一版代码:
```java
int countPrimes(int n) {
- boolean[] isPrim = new boolean[n];
+ boolean[] isPrime = new boolean[n];
// 将数组都初始化为 true
- Arrays.fill(isPrim, true);
+ Arrays.fill(isPrime, true);
for (int i = 2; i < n; i++)
- if (isPrim[i])
+ if (isPrime[i])
// i 的倍数不可能是素数了
for (int j = 2 * i; j < n; j += i)
- isPrim[j] = false;
+ isPrime[j] = false;
int count = 0;
for (int i = 2; i < n; i++)
- if (isPrim[i]) count++;
+ if (isPrime[i]) count++;
return count;
}
@@ -114,7 +128,7 @@ int countPrimes(int n) {
```java
for (int i = 2; i * i < n; i++)
- if (isPrim[i])
+ if (isPrime[i])
...
```
@@ -122,34 +136,34 @@ for (int i = 2; i * i < n; i++)
```java
for (int j = 2 * i; j < n; j += i)
- isPrim[j] = false;
+ isPrime[j] = false;
```
这样可以把 `i` 的整数倍都标记为 `false`,但是仍然存在计算冗余。
-比如 `n = 25`,`i = 4` 时算法会标记 4 × 2 = 8,4 × 3 = 12 等等数字,但是这两个数字已经被 `i = 2` 和 `i = 3` 的 2 × 4 和 3 × 4 标记了。
+比如 `n = 25`,`i = 5` 时算法会标记 5 × 2 = 10,5 × 3 = 15 等等数字,但是这两个数字已经被 `i = 2` 和 `i = 3` 的 2 × 5 和 3 × 5 标记了。
我们可以稍微优化一下,让 `j` 从 `i` 的平方开始遍历,而不是从 `2 * i` 开始:
```java
for (int j = i * i; j < n; j += i)
- isPrim[j] = false;
+ isPrime[j] = false;
```
这样,素数计数的算法就高效实现了,其实这个算法有一个名字,叫做 Sieve of Eratosthenes。看下完整的最终代码:
```java
int countPrimes(int n) {
- boolean[] isPrim = new boolean[n];
- Arrays.fill(isPrim, true);
+ boolean[] isPrime = new boolean[n];
+ Arrays.fill(isPrime, true);
for (int i = 2; i * i < n; i++)
- if (isPrim[i])
+ if (isPrime[i])
for (int j = i * i; j < n; j += i)
- isPrim[j] = false;
+ isPrime[j] = false;
int count = 0;
for (int i = 2; i < n; i++)
- if (isPrim[i]) count++;
+ if (isPrime[i]) count++;
return count;
}
@@ -164,17 +178,13 @@ int countPrimes(int n) {
以上就是素数算法相关的全部内容。怎么样,是不是看似简单的问题却有不少细节可以打磨呀?
-
-
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[204.计数质数](https://leetcode-cn.com/problems/count-primes)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\216\245\351\233\250\346\260\264.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\216\245\351\233\250\346\260\264.md"
index dd59d9fcacf25fff44c0540d841ffa7d6ef2c375..c876010ec15aa4372e4226ab965bb74edba0d37f 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\216\245\351\233\250\346\260\264.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\216\245\351\233\250\346\260\264.md"
@@ -1,28 +1,36 @@
# 接雨水问题详解
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[42.接雨水](https://leetcode-cn.com/problems/trapping-rain-water)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [11. Container With Most Water](https://leetcode.com/problems/container-with-most-water/) | [11. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/) | 🟠
+| [42. Trapping Rain Water](https://leetcode.com/problems/trapping-rain-water/) | [42. 接雨水](https://leetcode.cn/problems/trapping-rain-water/) | 🔴
**-----------**
-接雨水这道题目挺有意思,在面试题中出现频率还挺高的,本文就来步步优化,讲解一下这道题。
+力扣第 42 题「接雨水」挺有意思,在面试题中出现频率还挺高的,本文就来步步优化,讲解一下这道题。
先看一下题目:
-
+
就是用一个数组表示一个条形图,问你这个条形图最多能接多少水。
@@ -38,11 +46,11 @@ int trap(int[] height);
这么一想,可以发现这道题的思路其实很简单。具体来说,仅仅对于位置 `i`,能装下多少水呢?
-
+
能装 2 格水,因为 `height[i]` 的高度为 0,而这里最多能盛 2 格水,2-0=2。
-为什么位置 `i` 最多能盛 2 格水呢?因为,位置 `i` 能达到的水柱高度和其左边的最高柱子、右边的最高柱子有关,我们分别称这两个柱子高度为 `l_max` 和 `r_max`;**位置 i 最大的水柱高度就是 `min(l_max, r_max)`。**
+为什么位置 `i` 最多能盛 2 格水呢?因为,位置 `i` 能达到的水柱高度和其左边的最高柱子、右边的最高柱子有关,我们分别称这两个柱子高度为 `l_max` 和 `r_max`;**位置 i 最大的水柱高度就是 `min(l_max, r_max)`**。
更进一步,对于位置 `i`,能够装的水为:
@@ -56,27 +64,27 @@ water[i] = min(
```
-
+
-
+
这就是本问题的核心思路,我们可以简单写一个暴力算法:
-```cpp
-int trap(vector& height) {
- int n = height.size();
+```java
+int trap(int[] height) {
+ int n = height.length;
int res = 0;
for (int i = 1; i < n - 1; i++) {
int l_max = 0, r_max = 0;
// 找右边最高的柱子
for (int j = i; j < n; j++)
- r_max = max(r_max, height[j]);
+ r_max = Math.max(r_max, height[j]);
// 找左边最高的柱子
for (int j = i; j >= 0; j--)
- l_max = max(l_max, height[j]);
+ l_max = Math.max(l_max, height[j]);
// 如果自己就是最高的话,
// l_max == r_max == height[i]
- res += min(l_max, r_max) - height[i];
+ res += Math.min(l_max, r_max) - height[i];
}
return res;
}
@@ -90,25 +98,28 @@ int trap(vector& height) {
**我们开两个数组 `r_max` 和 `l_max` 充当备忘录,`l_max[i]` 表示位置 `i` 左边最高的柱子高度,`r_max[i]` 表示位置 `i` 右边最高的柱子高度**。预先把这两个数组计算好,避免重复计算:
-```cpp
-int trap(vector& height) {
- if (height.empty()) return 0;
- int n = height.size();
+```java
+int trap(int[] height) {
+ if (height.length == 0) {
+ return 0;
+ }
+ int n = height.length;
int res = 0;
// 数组充当备忘录
- vector l_max(n), r_max(n);
+ int[] l_max = new int[n];
+ int[] r_max = new int[n];
// 初始化 base case
l_max[0] = height[0];
r_max[n - 1] = height[n - 1];
// 从左向右计算 l_max
for (int i = 1; i < n; i++)
- l_max[i] = max(height[i], l_max[i - 1]);
+ l_max[i] = Math.max(height[i], l_max[i - 1]);
// 从右向左计算 r_max
- for (int i = n - 2; i >= 0; i--)
- r_max[i] = max(height[i], r_max[i + 1]);
+ for (int i = n - 2; i >= 0; i--)
+ r_max[i] = Math.max(height[i], r_max[i + 1]);
// 计算答案
- for (int i = 1; i < n - 1; i++)
- res += min(l_max[i], r_max[i]) - height[i];
+ for (int i = 1; i < n - 1; i++)
+ res += Math.min(l_max[i], r_max[i]) - height[i];
return res;
}
```
@@ -121,17 +132,15 @@ int trap(vector& height) {
首先,看一部分代码:
-```cpp
-int trap(vector& height) {
- int n = height.size();
- int left = 0, right = n - 1;
-
- int l_max = height[0];
- int r_max = height[n - 1];
+```java
+int trap(int[] height) {
+ int left = 0, right = height.length - 1;
+ int l_max = 0, r_max = 0;
- while (left <= right) {
- l_max = max(l_max, height[left]);
- r_max = max(r_max, height[right]);
+ while (left < right) {
+ l_max = Math.max(l_max, height[left]);
+ r_max = Math.max(r_max, height[right]);
+ // 此时 l_max 和 r_max 分别表示什么?
left++; right--;
}
}
@@ -143,24 +152,20 @@ int trap(vector& height) {
明白了这一点,直接看解法:
-```cpp
-int trap(vector& height) {
- if (height.empty()) return 0;
- int n = height.size();
- int left = 0, right = n - 1;
+```java
+int trap(int[] height) {
+ int left = 0, right = height.length - 1;
+ int l_max = 0, r_max = 0;
+
int res = 0;
-
- int l_max = height[0];
- int r_max = height[n - 1];
-
- while (left <= right) {
- l_max = max(l_max, height[left]);
- r_max = max(r_max, height[right]);
-
+ while (left < right) {
+ l_max = Math.max(l_max, height[left]);
+ r_max = Math.max(r_max, height[right]);
+
// res += min(l_max, r_max) - height[i]
if (l_max < r_max) {
res += l_max - height[left];
- left++;
+ left++;
} else {
res += r_max - height[right];
right--;
@@ -174,40 +179,112 @@ int trap(vector& height) {
之前的备忘录解法,`l_max[i]` 和 `r_max[i]` 分别代表 `height[0..i]` 和 `height[i..end]` 的最高柱子高度。
-```cpp
-res += min(l_max[i], r_max[i]) - height[i];
+```java
+res += Math.min(l_max[i], r_max[i]) - height[i];
```
-
+
但是双指针解法中,`l_max` 和 `r_max` 代表的是 `height[0..left]` 和 `height[right..end]` 的最高柱子高度。比如这段代码:
-```cpp
+```java
if (l_max < r_max) {
res += l_max - height[left];
left++;
}
```
-
+
此时的 `l_max` 是 `left` 指针左边的最高柱子,但是 `r_max` 并不一定是 `left` 指针右边最高的柱子,这真的可以得到正确答案吗?
其实这个问题要这么思考,我们只在乎 `min(l_max, r_max)`。**对于上图的情况,我们已经知道 `l_max < r_max` 了,至于这个 `r_max` 是不是右边最大的,不重要。重要的是 `height[i]` 能够装的水只和较低的 `l_max` 之差有关**:
-
+
这样,接雨水问题就解决了。
+### 扩展延伸
+
+下面我们看一道和接雨水问题非常类似的题目,力扣第 11 题「盛最多水的容器」:
+
+
+
+函数签名如下:
+
+```java
+int maxArea(int[] height);
+```
+
+这题和接雨水问题很类似,可以完全套用前文的思路,而且还更简单。两道题的区别在于:
+
+**接雨水问题给出的类似一幅直方图,每个横坐标都有宽度,而本题给出的每个横坐标是一条竖线,没有宽度**。
+
+我们前文讨论了半天 `l_max` 和 `r_max`,实际上都是为了计算 `height[i]` 能够装多少水;而本题中 `height[i]` 没有了宽度,那自然就好办多了。
+
+举个例子,如果在接雨水问题中,你知道了 `height[left]` 和 `height[right]` 的高度,你能算出 `left` 和 `right` 之间能够盛下多少水吗?
+
+不能,因为你不知道 `left` 和 `right` 之间每个柱子具体能盛多少水,你得通过每个柱子的 `l_max` 和 `r_max` 来计算才行。
+
+反过来,就本题而言,你知道了 `height[left]` 和 `height[right]` 的高度,能算出 `left` 和 `right` 之间能够盛下多少水吗?
+
+可以,因为本题中竖线没有宽度,所以 `left` 和 `right` 之间能够盛的水就是:
+
+```python
+min(height[left], height[right]) * (right - left)
+```
+
+类似接雨水问题,高度是由 `height[left]` 和 `height[right]` 较小的值决定的。
+
+解决这道题的思路依然是双指针技巧:
+
+**用 `left` 和 `right` 两个指针从两端向中心收缩,一边收缩一边计算 `[left, right]` 之间的矩形面积,取最大的面积值即是答案**。
+
+先直接看解法代码吧:
+
+```java
+int maxArea(int[] height) {
+ int left = 0, right = height.length - 1;
+ int res = 0;
+ while (left < right) {
+ // [left, right] 之间的矩形面积
+ int cur_area = Math.min(height[left], height[right]) * (right - left);
+ res = Math.max(res, cur_area);
+ // 双指针技巧,移动较低的一边
+ if (height[left] < height[right]) {
+ left++;
+ } else {
+ right--;
+ }
+ }
+ return res;
+}
+```
+
+代码和接雨水问题大致相同,不过肯定有读者会问,下面这段 if 语句为什么要移动较低的一边:
+
+```java
+// 双指针技巧,移动较低的一边
+if (height[left] < height[right]) {
+ left++;
+} else {
+ right--;
+}
+```
+
+**其实也好理解,因为矩形的高度是由 `min(height[left], height[right])` 即较低的一边决定的**:
+
+你如果移动较低的那一边,那条边可能会变高,使得矩形的高度变大,进而就「有可能」使得矩形的面积变大;相反,如果你去移动较高的那一边,矩形的高度是无论如何都不会变大的,所以不可能使矩形的面积变得更大。
+
+至此,这道题也解决了。
+
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[42.接雨水](https://leetcode-cn.com/problems/trapping-rain-water)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\260\264\345\241\230\346\212\275\346\240\267.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\260\264\345\241\230\346\212\275\346\240\267.md"
index 8dc8c25cba12916a1153de2e2701935c9cc2efb5..affbb6064420eb2b67b28f91af1f138b8b2d5f85 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\260\264\345\241\230\346\212\275\346\240\267.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\346\260\264\345\241\230\346\212\275\346\240\267.md"
@@ -1,26 +1,32 @@
# 随机算法之水塘抽样算法
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[382.链表随机节点](https://leetcode-cn.com/problems/linked-list-random-node)
-[398.随机数索引](https://leetcode-cn.com/problems/random-pick-index)
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [382. Linked List Random Node](https://leetcode.com/problems/linked-list-random-node/) | [382. 链表随机节点](https://leetcode.cn/problems/linked-list-random-node/) | 🟠
+| [398. Random Pick Index](https://leetcode.com/problems/random-pick-index/) | [398. 随机数索引](https://leetcode.cn/problems/random-pick-index/) | 🟠
**-----------**
-我最近在 LeetCode 上做到两道非常有意思的题目,382 和 398 题,关于水塘抽样算法(Reservoir Sampling),本质上是一种随机概率算法,解法应该说会者不难,难者不会。
+我最近在力扣上做到两道非常有意思的题目,382 和 398 题,关于水塘抽样算法(Reservoir Sampling),本质上是一种随机概率算法,解法应该说会者不难,难者不会。
我第一次见到这个算法问题是谷歌的一道算法题:给你一个**未知长度**的链表,请你设计一个算法,**只能遍历一次**,随机地返回链表中的一个节点。
@@ -32,7 +38,7 @@
### 算法实现
-**先解决只抽取一个元素的问题**,这个问题的难点在于,随机选择是「动态」的,比如说你现在你有 5 个元素,你已经随机选取了其中的某个元素 `a` 作为结果,但是现在再给你一个新元素 `b`,你应该留着 `a` 还是将 `b` 作为结果呢,以什么逻辑选择 `a` 和 `b` 呢,怎么证明你的选择方法在概率上是公平的呢?
+**先解决只抽取一个元素的问题**,这个问题的难点在于,随机选择是「动态」的,比如说你现在你有 5 个元素,你已经随机选取了其中的某个元素 `a` 作为结果,但是现在再给你一个新元素 `b`,你应该留着 `a` 还是将 `b` 作为结果呢?以什么逻辑做出的选择,才能保证你的选择方法在概率上是公平的呢?
**先说结论,当你遇到第 `i` 个元素时,应该有 `1/i` 的概率选择该元素,`1 - 1/i` 的概率保持原有的选择**。看代码容易理解这个思路:
@@ -44,9 +50,10 @@ int getRandom(ListNode head) {
ListNode p = head;
// while 循环遍历链表
while (p != null) {
+ i++;
// 生成一个 [0, i) 之间的整数
// 这个整数等于 0 的概率就是 1/i
- if (r.nextInt(++i) == 0) {
+ if (0 == r.nextInt(i)) {
res = p.val;
}
p = p.next;
@@ -59,15 +66,7 @@ int getRandom(ListNode head) {
**证明**:假设总共有 `n` 个元素,我们要的随机性无非就是每个元素被选择的概率都是 `1/n` 对吧,那么对于第 `i` 个元素,它被选择的概率就是:
-
-
-
+
第 `i` 个元素被选择的概率是 `1/i`,第 `i+1` 次不被替换的概率是 `1 - 1/(i+1)`,以此类推,相乘就是第 `i` 个元素最终被选中的概率,就是 `1/n`。
@@ -105,16 +104,8 @@ int[] getRandom(ListNode head, int k) {
对于数学证明,和上面区别不大:
-
-
+
因为虽然每次更新选择的概率增大了 `k` 倍,但是选到具体第 `i` 个元素的概率还是要乘 `1/k`,也就回到了上一个推导。
@@ -132,19 +123,19 @@ $$ -->
1、如何对带有权重的样本进行加权随机抽取?比如给你一个数组 `w`,每个元素 `w[i]` 代表权重,请你写一个算法,按照权重随机抽取索引。比如 `w = [1,99]`,算法抽到索引 0 的概率是 1%,抽到索引 1 的概率是 99%。
+答案见 [我的这篇文章](https://labuladong.github.io/article/fname.html?fname=随机权重)。
+
2、实现一个生成器类,构造函数传入一个很长的数组,请你实现 `randomGet` 方法,每次调用随机返回数组中的一个元素,多次调用不能重复返回相同索引的元素。要求不能对该数组进行任何形式的修改,且操作的时间复杂度是 O(1)。
-这两个问题都是比较困难的,以后有时间我会写一写相关的文章。
+答案见 [我的这篇文章](https://labuladong.github.io/article/fname.html?fname=随机集合)。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[382.链表随机节点](https://leetcode-cn.com/problems/linked-list-random-node)
diff --git "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\347\274\272\345\244\261\345\222\214\351\207\215\345\244\215\347\232\204\345\205\203\347\264\240.md" "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\347\274\272\345\244\261\345\222\214\351\207\215\345\244\215\347\232\204\345\205\203\347\264\240.md"
index 1112b549c6aeac61bc66f7c0580b024962b3661a..0e049291154d3b869b9f006b1983a5b7bf747b9b 100644
--- "a/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\347\274\272\345\244\261\345\222\214\351\207\215\345\244\215\347\232\204\345\205\203\347\264\240.md"
+++ "b/\351\253\230\351\242\221\351\235\242\350\257\225\347\263\273\345\210\227/\347\274\272\345\244\261\345\222\214\351\207\215\345\244\215\347\232\204\345\205\203\347\264\240.md"
@@ -1,32 +1,39 @@
# 如何寻找缺失和重复的元素
+
+
+
+
-
-
+
-**《labuladong 的算法秘籍》、《labuladong 的刷题笔记》两本 PDF 和刷题插件 2.0 免费开放下载,详情见 [labuladong 的刷题三件套正式发布](https://mp.weixin.qq.com/s/yN4cHQRsFa5SWlacopHXYQ)**~
+**通知:[数据结构精品课 V1.8](https://aep.h5.xeknow.com/s/1XJHEO) 持续更新中;[第十期刷题打卡挑战](https://mp.weixin.qq.com/s/eUG2OOzY3k_ZTz-CFvtv5Q) 最后一天报名。**
-读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-[645.错误的集合](https://leetcode-cn.com/problems/set-mismatch)
+
+读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
+
+| LeetCode | 力扣 | 难度 |
+| :----: | :----: | :----: |
+| [645. Set Mismatch](https://leetcode.com/problems/set-mismatch/) | [645. 错误的集合](https://leetcode.cn/problems/set-mismatch/) | 🟢
**-----------**
-今天就聊一道很看起来简单却十分巧妙的问题,寻找缺失和重复的元素。之前的一篇文章「寻找缺失元素」也写过类似的问题,不过这次的和上次的问题使用的技巧不同。
+今天就聊一道很看起来简单却十分巧妙的问题,寻找缺失和重复的元素。之前的一篇文章 [常用的位操作](算法思维系列/常用的位操作.md) 中也写过类似的问题,不过这次的和上次的问题使用的技巧不同。
-这是 LeetCode 645 题,我来描述一下这个题目:
+这是力扣第 645 题「错误的集合」,我来描述一下这个题目:
给一个长度为 `N` 的数组 `nums`,其中本来装着 `[1..N]` 这 `N` 个元素,无序。但是现在出现了一些错误,`nums` 中的一个元素出现了重复,也就同时导致了另一个元素的缺失。请你写一个算法,找到 `nums` 中的重复元素和缺失元素的值。
-```cpp
+```java
// 返回两个数字,分别是 {dup, missing}
-vector findErrorNums(vector& nums);
+int[] findErrorNums(int[] nums);
```
比如说输入:`nums = [1,2,2,4]`,算法返回 `[2,3]`。
@@ -35,7 +42,7 @@ vector findErrorNums(vector& nums);
但问题是,这个常规解法需要一个哈希表,也就是 O(N) 的空间复杂度。你看题目给的条件那么巧,在 `[1..N]` 的几个数字中恰好有一个重复,一个缺失,**事出反常必有妖**,对吧。
-O(N) 的时间复杂度遍历数组是无法避免的,所以我们可以想想办法如何降低空间复杂度,是否可以在 O(1) 的空间复杂度之下找到重复和确实的元素呢?
+O(N) 的时间复杂度遍历数组是无法避免的,所以我们可以想想办法如何降低空间复杂度,是否可以在 O(1) 的空间复杂度之下找到重复和缺失的元素呢?
### 思路分析
@@ -51,29 +58,29 @@ O(N) 的时间复杂度遍历数组是无法避免的,所以我们可以想想
那么,如何不使用额外空间判断某个索引有多少个元素对应呢?这就是这个问题的精妙之处了:
-**通过将每个索引对应的元素变成负数,以表示这个索引被对应过一次了**:
+**通过将每个索引对应的元素变成负数,以表示这个索引被对应过一次了**,算法过程如下 GIF 所示:
-
+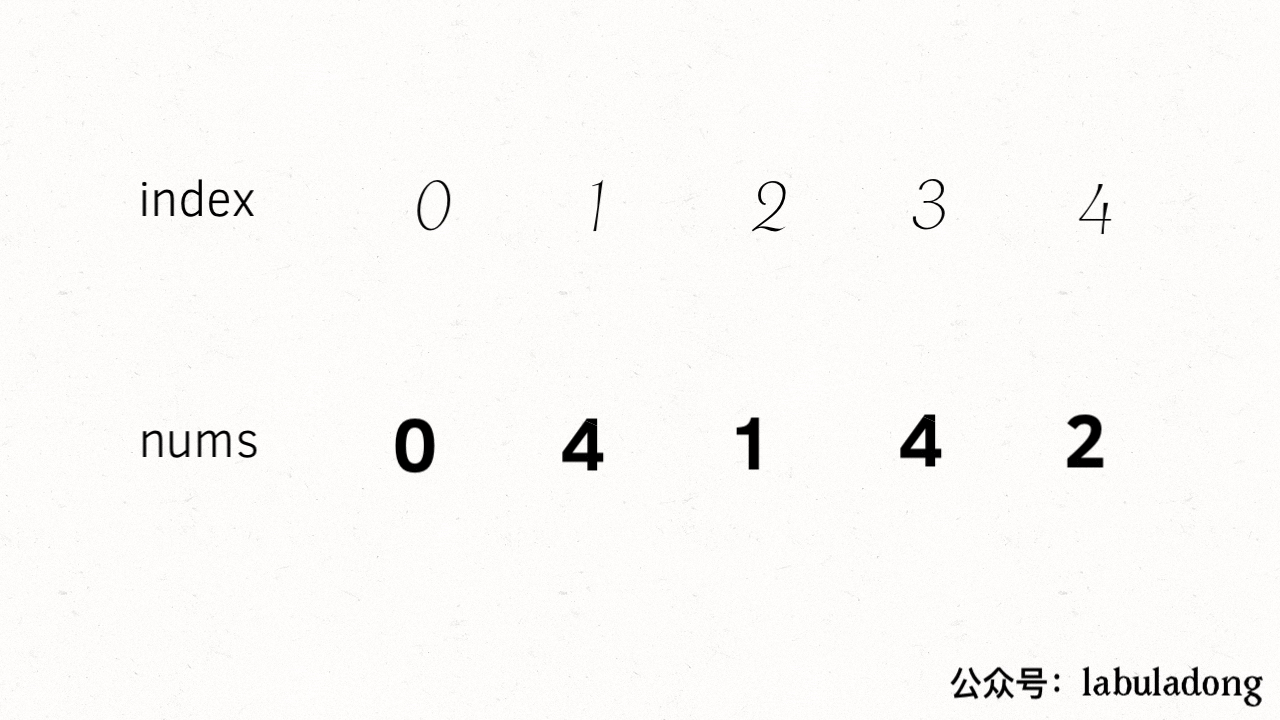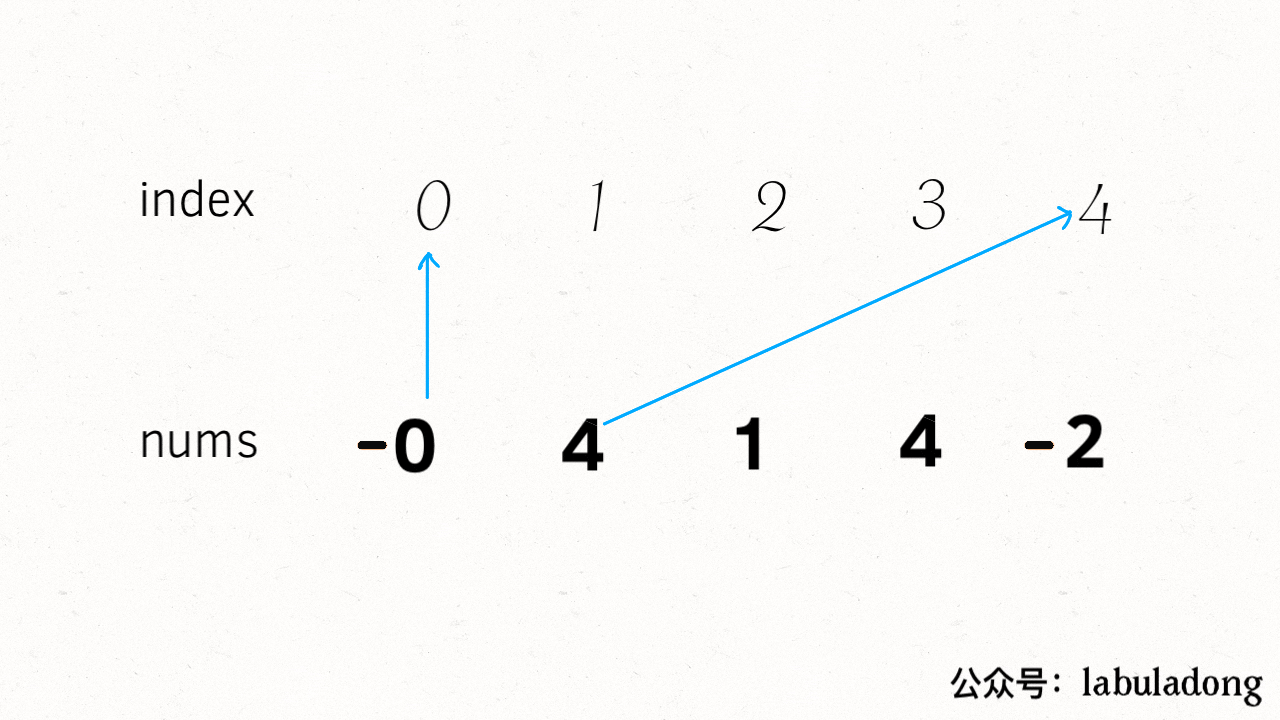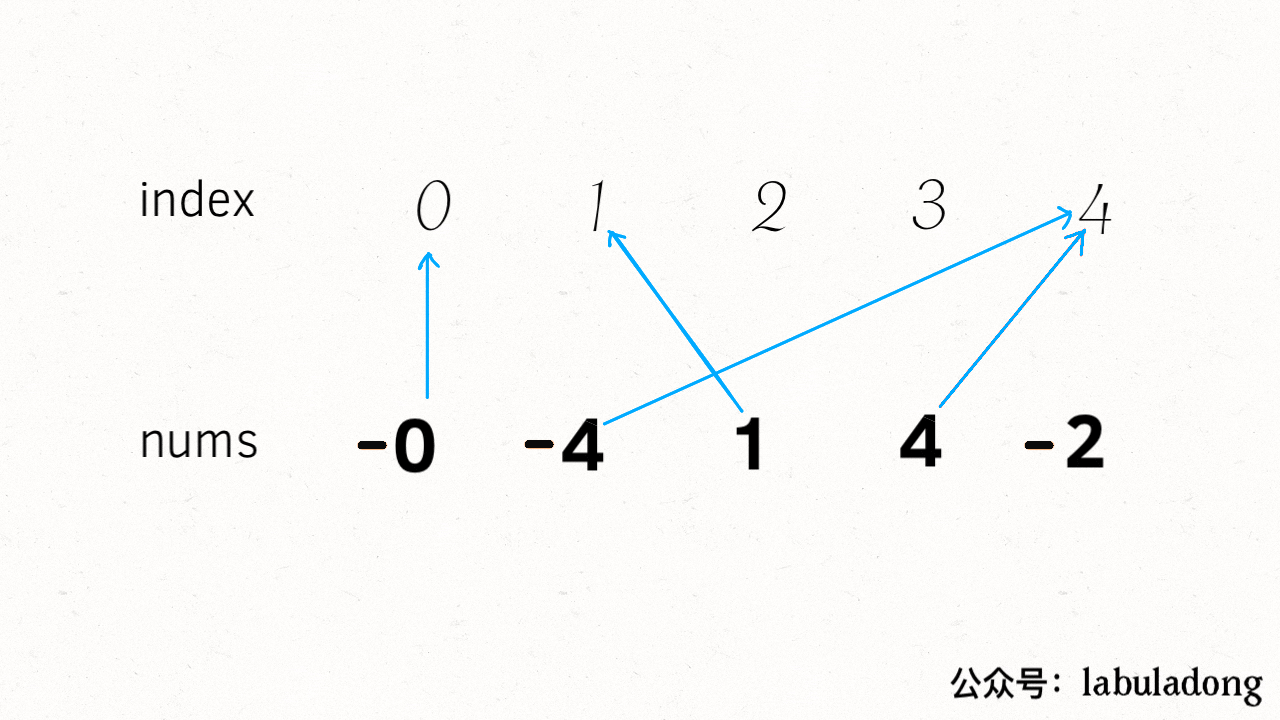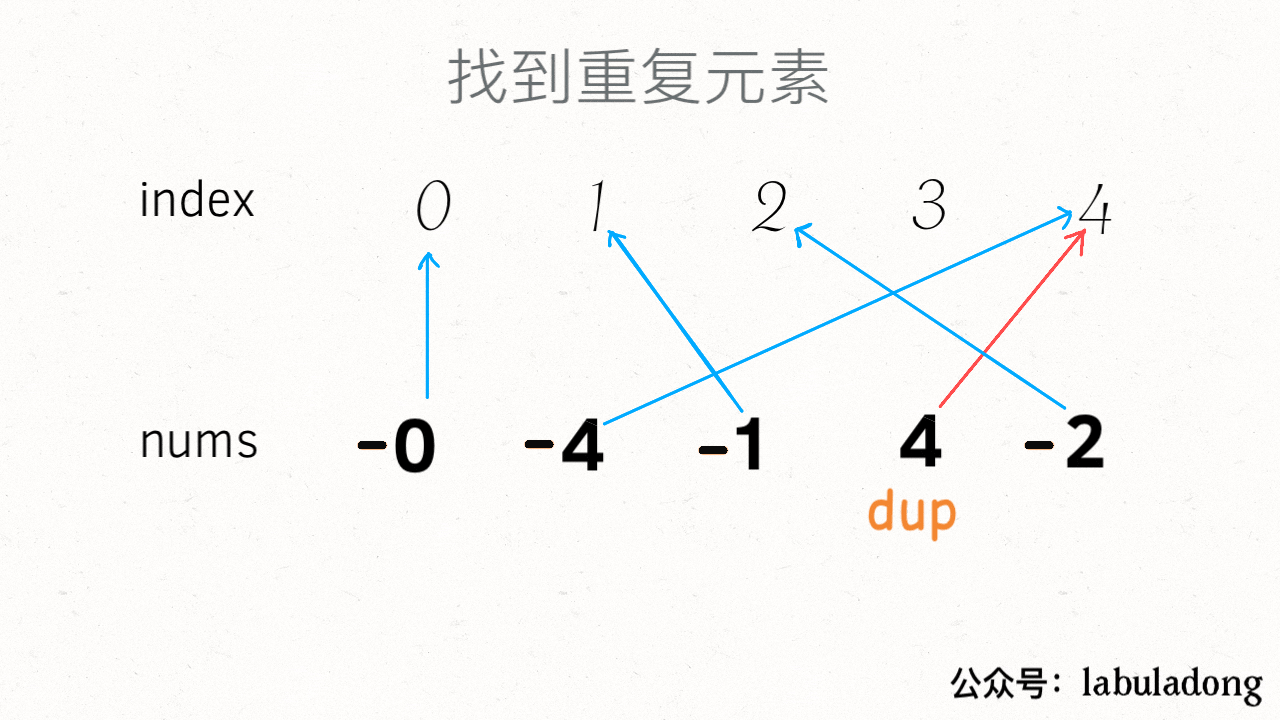
如果出现重复元素 `4`,直观结果就是,索引 `4` 所对应的元素已经是负数了:
-
+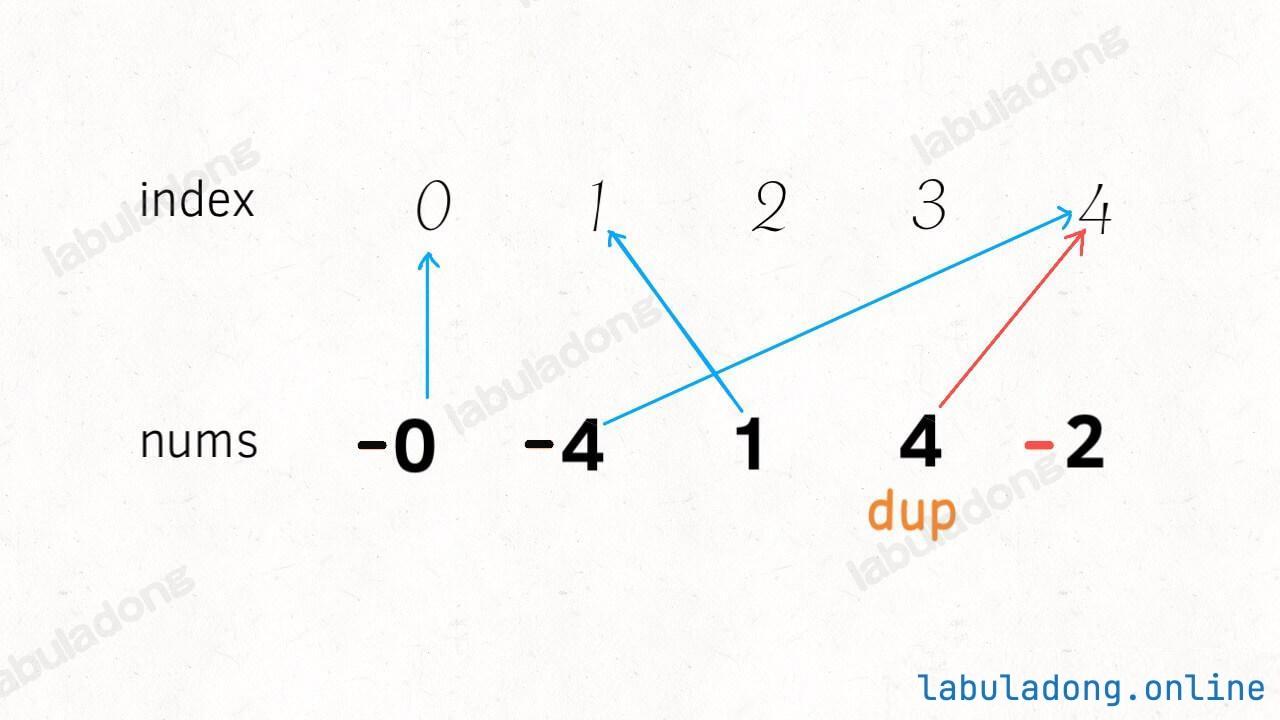
对于缺失元素 `3`,直观结果就是,索引 `3` 所对应的元素是正数:
-
+
对于这个现象,我们就可以翻译成代码了:
-```cpp
-vector findErrorNums(vector& nums) {
- int n = nums.size();
+```java
+int[] findErrorNums(int[] nums) {
+ int n = nums.length;
int dup = -1;
for (int i = 0; i < n; i++) {
- int index = abs(nums[i]);
+ int index = Math.abs(nums[i]);
// nums[index] 小于 0 则说明重复访问
if (nums[index] < 0)
- dup = abs(nums[i]);
+ dup = Math.abs(nums[i]);
else
nums[index] *= -1;
}
@@ -84,21 +91,21 @@ vector findErrorNums(vector& nums) {
if (nums[i] > 0)
missing = i;
- return {dup, missing};
+ return new int[]{dup, missing};
}
```
这个问题就基本解决了,别忘了我们刚才为了方便分析,假设元素是 `[0..N-1]`,但题目要求是 `[1..N]`,所以只要简单修改两处地方即可得到原题的答案:
-```cpp
-vector findErrorNums(vector& nums) {
- int n = nums.size();
+```java
+int[] findErrorNums(int[] nums) {
+ int n = nums.length;
int dup = -1;
for (int i = 0; i < n; i++) {
// 现在的元素是从 1 开始的
- int index = abs(nums[i]) - 1;
+ int index = Math.abs(nums[i]) - 1;
if (nums[index] < 0)
- dup = abs(nums[i]);
+ dup = Math.abs(nums[i]);
else
nums[index] *= -1;
}
@@ -108,8 +115,8 @@ vector findErrorNums(vector& nums) {
if (nums[i] > 0)
// 将索引转换成元素
missing = i + 1;
-
- return {dup, missing};
+
+ return new int[]{dup, missing};
}
```
@@ -123,19 +130,15 @@ vector findErrorNums(vector& nums) {
排序的方法也很好理解,对于这个问题,可以想象如果元素都被从小到大排序,如果发现索引对应的元素如果不相符,就可以找到重复和缺失的元素。
-异或运算也是常用的,因为异或性质 `a ^ a = 0, a ^ 0 = a`,如果将索引和元素同时异或,就可以消除成对儿的索引和元素,留下的就是重复或者缺失的元素。可以看看前文「寻找缺失元素」,介绍过这种方法。
-
-
+异或运算也是常用的,因为异或性质 `a ^ a = 0, a ^ 0 = a`,如果将索引和元素同时异或,就可以消除成对儿的索引和元素,留下的就是重复或者缺失的元素。可以看看前文 [常用的位运算](https://labuladong.github.io/article/fname.html?fname=常用的位操作),介绍过这种方法。
**_____________**
-**刷算法,学套路,认准 labuladong,公众号和 [在线电子书](https://labuladong.gitee.io/algo/) 持续更新最新文章**。
+**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「进群」可加入算法群;回复「PDF」可获取精华文章 PDF**:
+
+
-**本小抄即将出版,微信扫码关注公众号,后台回复「小抄」限时免费获取,回复「进群」可进刷题群一起刷题,带你搞定 LeetCode**。
-
-
-
======其他语言代码======
[645.错误的集合](https://leetcode-cn.com/problems/set-mismatch)

