- 29 6月, 2022 10 次提交
-
-
由 tianshuo78520a 提交于
-
由 zhangkaihuo 提交于
-
由 ccrrong 提交于
* add comparisons trt converter
-
由 Leo Chen 提交于
-
由 Leo Chen 提交于
* separate variable scope and scope * hot fix for lod_tensor_blocking_queue * fix bug that variable exists in global scope
-
由 Chen Weihang 提交于
-
由 Wilber 提交于
* inference add convert to mixed model ability.
-
由 zyfncg 提交于
* move cross form legacy_api.yaml to api.yaml * move diagonal to api.yaml
-
由 ronnywang 提交于
-
由 QingshuChen 提交于
* skip xpu conv2d fp16 unitest *test=kunlun * minor *test=kunlun
-
- 28 6月, 2022 27 次提交
-
-
由 Yuang Liu 提交于
-
由 Sing_chan 提交于
-
由 Aurelius84 提交于
-
由 Aurelius84 提交于
* [Dy2Stat]Polish all API name of _jst
-
由 xiongkun 提交于
* add unittest for PR43688
-
由 wangzhen38 提交于
* [UPDATE FLUID API] only reference in paddlerec * change lr * [UPDATE FLUID API] only reference in paddlerec * update by reviews
-
由 Feiyu Chan 提交于
* change to condition to find python interpreter to avoid skipping the find process. PYTHONINTERP_FOUND is the best signal that python interpreter is found.
-
由 Chen Long 提交于
-
由 Tomasz Socha 提交于
* Remove output arguments from functions. Replace pointers with references * Name used bool flags * Reorder functions * Enable bfloat16 data type * Give declarations some space * Style * Style
-
由 zhaoying9105 提交于
-
由 Ming-Xu Huang 提交于
1. test_parallel_executor_seresnext_base_gpu failed on 2 P100 GPUs with `470.82` driver. ``` ====================================================================== FAIL: test_seresnext_with_learning_rate_decay (test_parallel_executor_seresnext_base_gpu.TestResnetGPU) ---------------------------------------------------------------------- Traceback (most recent call last): File "/opt/paddle/paddle/build/python/paddle/fluid/tests/unittests/test_parallel_executor_seresnext_base_gpu.py", line 32, in test_seresnext_with_learning_rate_decay self._compare_result_with_origin_model( File "/opt/paddle/paddle/build/python/paddle/fluid/tests/unittests/seresnext_test_base.py", line 56, in _compare_result_with_origin_model self.assertAlmostEquals( AssertionError: 6.8825445 != 6.882531 within 1e-05 delta (1.335144e-05 difference) ---------------------------------------------------------------------- ``` 2. To be more accuracte on evaluating loss convergence, we proposed to apply IOU as metric, instead of comparing first and last loss values. 3. As offline discussion, we also evaluated convergence on P100 and A100 in 1000 interations to make sure this UT have the same convergence property on both devices. The curves are showed below. 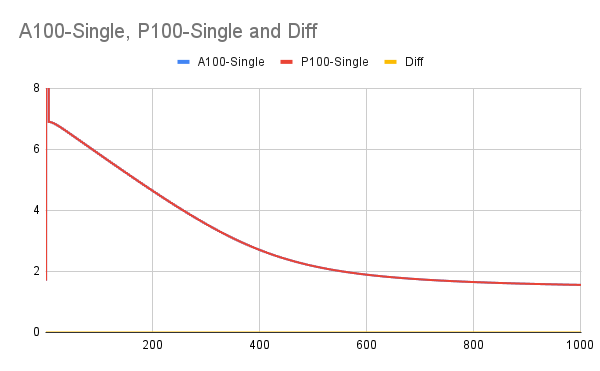 -
由 fuyou765 提交于
-
由 石晓伟 提交于
-
 由 zhouweiwei2014 提交于
由 zhouweiwei2014 提交于* [Sparse]add SparseTensor mv kernel(csr*dense_vec->dence_vec, coo*dense_vec->dense_vec) * fix CI
-
由 zmxdream 提交于
* fix merge_grad&push_sparse * change typo * fix code format. test=develop * fix code format. test=develop * fix code format. test=develop * fix debug info * optimize hbm * fix size_t * fix size_t
-
由 minghaoBD 提交于
-
由 zhangxiaoci 提交于
-
由 Ruibiao Chen 提交于
* boost::variant -> paddle::variant * boost::variant.apply_visit -> paddle::visit * Update pybind_boost_hraders.h * Fix CINN compilation errors * Revert FetchResultType
-
由 Sing_chan 提交于
-
由 Qi Li 提交于
-
由 WangZhen 提交于
* Polish Layer code * Refine some api name * Polish load program code * Clean smoe include * Process windows style path * Move some funtions to utils
-
由 chenjian 提交于
* record memory and op supplement info * update * update * fix a bug * fix memory recording * fix a bug * update * update * fix a bug * update * fix a bug * fix a bug * fix a bug * update dygraph record * add infer shape record * fix * fix * fix * add comments * fix a bug * fix * fix
-
由 pangyoki 提交于
* inplace op without backward supports input of multiple inplace vars * support inplace without backward in eager mode and fix python_c in eager_fluid * fix output in yaml * fix map to const& * solve conflict v2
-
由 Xiaoxu Chen 提交于
* enable Jacobian,Hessian supporting new autograd * fix prim mode failed in PR-CI-Windows * add forward_gradients api * add forward_gradients api * skip test_autograd_functional_prim in windows ci * fix test_autograd_funciton_prim timeouot * remove the block parameter in prim2orig method * remove duplicate to_tensors code snippet # test=allcases
-
由 WangZhen 提交于
-
由 sneaxiy 提交于
-
- 27 6月, 2022 3 次提交
-
-
由 Huihuang Zheng 提交于
The paddle-cinn failed recently and block all PRs from merging. We found the key error reason from the log: 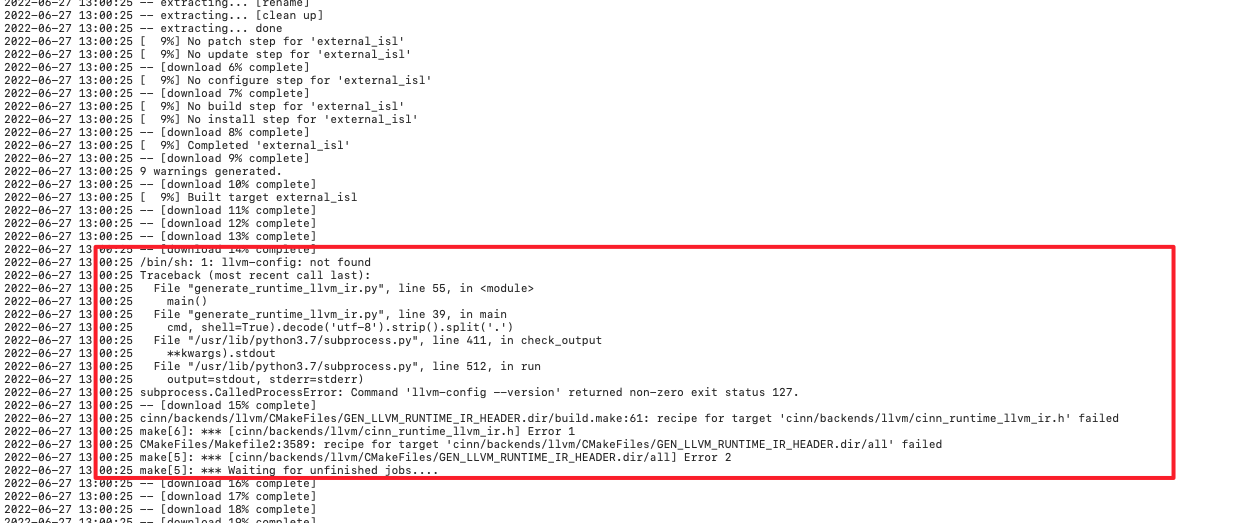 The CI environment didn't contain llvm. We then debug and found https://github.com/PaddlePaddle/Paddle/pull/43534 deleted the llvm due to clang-format upgrade:  So this PR added the llvm back. However, `clang-llvm-3.8.0` contains `clang-format-3.8`, so we modified the old command `cp -r` to `cp -rn`, which could ignore the installed `clang-format-13`
-
由 Sing_chan 提交于
* make inference_api_test use import_lib + dll to smaller its size;test=document_fix;test=windows_ci_inference * make place.h not export symbols; change the order of inference test dependencies * cant delete analysis pass ..in inference_analysis_test or build test_analyzer.exe will failed; temporarily comment test need paddle_inference_c * add onnx path; cp onnxruntime.dll to tests/api * make c_ut depend on paddle_inference_c_shared rather than paddle_inference_c * make c_ut depend .dll in windows and .lib in linux;path add capi_exp * init context pool by analysis predictor * make windows and linux both use shared; compile shared even on_infer off * move case:profile after case:fuse_statis to avoid context pool null problem * make c_ut depend .dll in windows and .lib in linux;path add capi_exp
-
由 pangyoki 提交于
-