Merge the update in profiling tool
Showing
doc/design/backward.md
0 → 100644
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
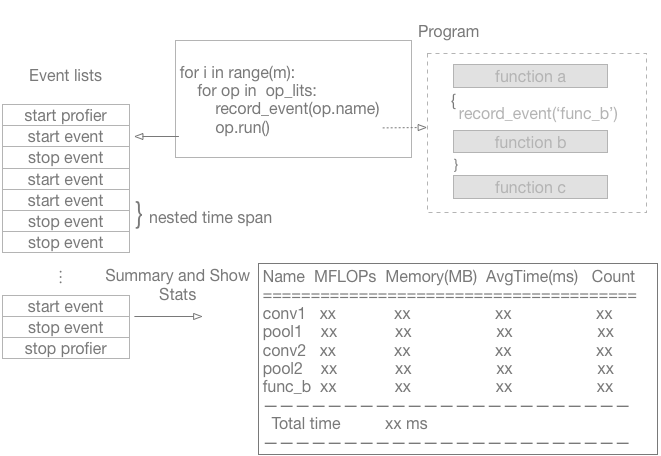
doc/design/images/profiler.png
0 → 100644
{kind=link}
49.9 KB
doc/design/profiler.md
0 → 100644
paddle/framework/backward.md
已删除
100644 → 0
paddle/framework/tensor_util.cc
0 → 100644
paddle/framework/tensor_util.cu
0 → 120000
paddle/operators/norm_op.cc
0 → 100644
paddle/operators/norm_op.cu
0 → 100644
paddle/operators/norm_op.h
0 → 100644