*[Cluster Training Using Kubernetes](#cluster-training-using-kubernetes)
# Introduction
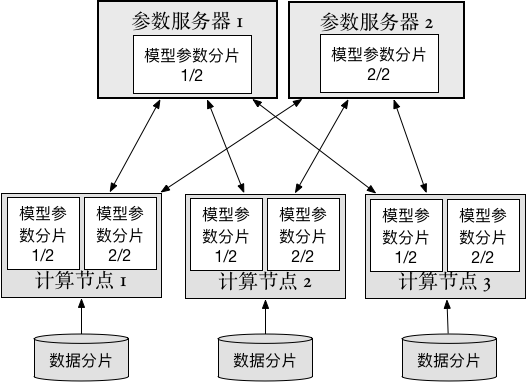
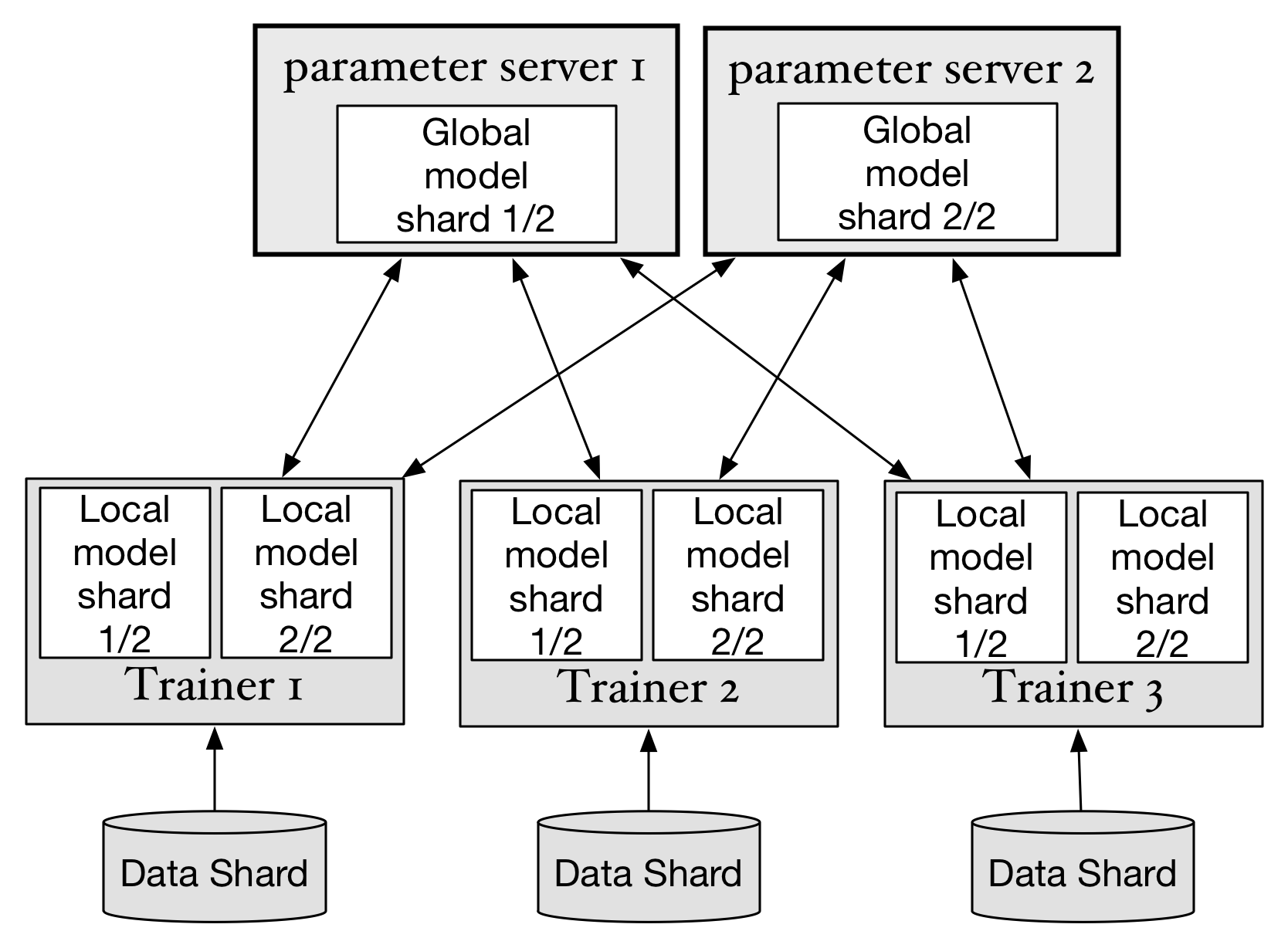
In this article, we'll explain how to run distributed training jobs with PaddlePaddle on different types of clusters. The diagram below shows the main architecture of a distributed trainning job:
- Data shard: training data will be split into multiple partitions, trainers use the partitions of the whole dataset to do the training job.
- Trainer: each trainer reads the data shard, and train the neural network. Then the trainer will upload calculated "gradients" to parameter servers, and wait for parameters to be optimized on the parameter server side. When that finishes, the trainer download optimized parameters and continues its training.
- Parameter server: every parameter server stores part of the whole neural network model data. They will do optimization calculations when gradients are uploaded from trainers, and then send updated parameters to trainers.
PaddlePaddle can support both synchronize stochastic gradient descent (SGD) and asynchronous SGD.
When training with synchronize SGD, PaddlePaddle uses an internal "synchronize barrier" which makes gradients update and parameter download in strict order. On the other hand, asynchronous SGD won't wait for all trainers to finish upload at a single step, this will increase the parallelism of distributed training: parameter servers do not depend on each other, they'll do parameter optimization concurrently. Parameter servers will not wait for trainers, so trainers will also do their work concurrently. But asynchronous SGD will introduce more randomness and noises in the gradient.
# Preparations
1. Prepare your computer cluster. It's normally a bunch of Linux servers connected by LAN. Each server will be assigned a unique IP address. The computers in the cluster can be called "nodes".
2. Install PaddlePaddle on every node. If you are going to take advantage of GPU cards, you'll also need to install proper driver and CUDA libraries. To install PaddlePaddle please read [this build and install](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/getstarted/build_and_install) document. We strongly recommend using [Docker installation](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/getstarted/build_and_install/docker_install_en.rst).
After installation, you can check the version by typing the below command (run a docker container if using docker: `docker run -it paddlepaddle/paddle:[tag] /bin/bash`):
```bash
$ paddle version
PaddlePaddle 0.10.0rc, compiled with
with_avx: ON
with_gpu: OFF
with_double: OFF
with_python: ON
with_rdma: OFF
with_timer: OFF
```
In this article, we explain how to run distributed Paddle training jobs on clusters. We will create the distributed version of the single-process training example, [recommendation](https://github.com/baidu/Paddle/tree/develop/demo/recommendation).
We'll take `doc/howto/usage/cluster/src/word2vec` as an example to introduce distributed training using PaddlePaddle v2 API.
[Scripts](https://github.com/baidu/Paddle/tree/develop/paddle/scripts/cluster_train) used in this article launch distributed jobs via SSH. They also work as a reference for users running more sophisticated cluster management systems like MPI and [Kubernetes](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/howto/usage/k8s).
# Command-line arguments
## Prerequisite
## Starting parameter server
1. Aforementioned scripts use a Python library [fabric](http://www.fabfile.org/) to run SSH commands. We can use `pip` to install fabric:
Type the below command to start a parameter server which will wait for trainers to connect:
1. We need to install PaddlePaddle on all nodes in the cluster. To enable GPUs, we need to install CUDA in `/usr/local/cuda`; otherwise Paddle would report errors at runtime.
If you wish to run parameter servers in background, and save a log file, you can type:
1. Set the `ROOT_DIR` variable in [`cluster_train/conf.py`] on all nodes. For convenience, we often create a Unix user `paddle` on all nodes and set `ROOT_DIR=/home/paddle`. In this way, we can write public SSH keys into `/home/paddle/.ssh/authorized_keys` so that user `paddle` can SSH to all nodes without password.
| port | required | 7164 | port which parameter server will listen on. If ports_num greater than 1, parameter server will listen on multiple ports for more network throughput |
| ports_num | required | 1 | total number of ports will listen on |
| ports_num_for_sparse | required | 1 | number of ports which serves sparse parameter update |
| num_gradient_servers | required | 1 | total number of gradient servers |
## Prepare Job Workspace
## Starting trainer
Type the command below to start the trainer(name the file whatever you want, like "train.py")
We refer to the directory where we put dependent libraries, config files, etc., as *workspace*.
```bash
$ python train.py
```
These `train/test` data should be prepared before launching cluster job. To satisfy the requirement that train/test data are placed in different directory from workspace, PADDLE refers train/test data according to index file named as `train.list/test.list` which are used in model config file. So the train/test data also contains train.list/test.list two list file. All local training demo already provides scripts to help you create these two files, and all nodes in cluster job will handle files with same logical code in normal condition.
Trainers' network need to be connected with parameter servers' network to finish the job. Trainers need to know port and IPs to locate parameter servers. You can pass arguments to trainers through [environment variables](https://en.wikipedia.org/wiki/Environment_variable) or pass to `paddle.init()` function. Arguments passed to the `paddle.init()` function will overwrite environment variables.
Generally, you can use same model file from local training for cluster training. What you should have in mind that, the `batch_size` set in `setting` function in model file means batch size in `each` node of cluster job instead of total batch size if synchronization SGD was used.
Use environment viriables:
Following steps are based on [demo/recommendation](https://github.com/PaddlePaddle/Paddle/tree/develop/demo/recommendation) demo in demo directory.
```bash
export PADDLE_INIT_USE_GPU=False
export PADDLE_INIT_TRAINER_COUNT=1
export PADDLE_INIT_PORT=7164
export PADDLE_INIT_PORTS_NUM=1
export PADDLE_INIT_PORTS_NUM_FOR_SPARSE=1
export PADDLE_INIT_NUM_GRADIENT_SERVERS=1
export PADDLE_INIT_TRAINER_ID=0
export PADDLE_INIT_PSERVERS=127.0.0.1
python train.py
```
You just go through demo/recommendation tutorial doc until `Train` section, and at last you will get train/test data and model configuration file. Finaly, just use demo/recommendation as workspace for cluster training.
Pass arguments:
At last your workspace should look like as follow:
| use_gpu | optional | False | set to "True" to enable GPU training |
| |-- config_generator.py
| trainer_count | required | 1 | total count of trainers in the training job |
| |-- meta.bin
| port | required | 7164 | port to connect to parameter server |
| |-- meta_config.json
| ports_num | required | 1 | number of ports for communication |
| |-- meta_generator.py
| ports_num_for_sparse | required | 1 | number of ports for sparse type caculation |
| |-- ml-1m
| num_gradient_servers | required | 1 | total number of gradient server |
| |-- ml_data.sh
| trainer_id | required | 0 | ID for every trainer, start from 0 |
| |-- ratings.dat.test
| pservers | required | 127.0.0.1 | list of IPs of parameter servers, separated by "," |
| |-- ratings.dat.train
| |-- split.py
## Prepare Training Dataset
| |-- test.list
| `-- train.list
Here's some example code [prepare.py](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/howto/usage/cluster/src/word2vec/prepare.py), it will download public `imikolov` dataset and split it into multiple files according to job parallelism(trainers count). Modify `SPLIT_COUNT` at the begining of `prepare.py` to change the count of output files.
|-- dataprovider.py
|-- evaluate.sh
In the real world, we often use `MapReduce` job's output as training data, so there will be lots of files. You can use `mod` to assign training file to trainers:
|-- prediction.py
|-- preprocess.sh
```python
|-- requirements.txt
importos
|-- run.sh
train_list=[]
`-- trainer_config.py
flist=os.listdir("/train_data/")
forfinflist:
suffix=int(f.split("-")[1])
ifsuffix%TRAINER_COUNT==TRAINER_ID:
train_list.append(f)
```
Example code `prepare.py` will split training data and testing data into 3 files with digital suffix like `-00000`, `-00001` and`-00002`:
```
train.txt
train.txt-00000
train.txt-00001
train.txt-00002
test.txt
test.txt-00000
test.txt-00001
test.txt-00002
```
```
Not all of these files are needed for cluster training, but it's not necessary to remove useless files.
`trainer_config.py`
When job started, every trainer needs to get it's own part of data. In some distributed systems a storage service will be provided, so the date under that path can be accessed by all the trainer nodes. Without the storage service, you must copy the training data to each trainer node.
Indicates the model config file.
`train.list` and `test.list`
Different training jobs may have different data format and `reader()` function, developers may need to write different data prepare scripts and `reader()` functions for their job.
File index. It stores all relative or absolute file paths of all train/test data at current node.
`dataprovider.py`
## Prepare Training program
used to read train/test samples. It's same as local training.
`data`
We'll create a *workspace* directory on each node, storing your training program, dependencies, mounted or downloaded dataset directory.
all files in data directory are refered by train.list/test.list which are refered by data provider.
## Prepare Cluster Job Configuration
Your workspace may looks like:
```
.
|-- my_lib.py
|-- word_dict.pickle
|-- train.py
|-- train_data_dir/
| |-- train.txt-00000
| |-- train.txt-00001
| |-- train.txt-00002
`-- test_data_dir/
|-- test.txt-00000
|-- test.txt-00001
`-- test.txt-00002
```
The options below must be carefully set in cluster_train/conf.py
-`my_lib.py`: user defined libraries, like PIL libs. This is optional.
-`word_dict.pickle`: dict file for training word embeding.
-`train.py`: training program. Sample code: [api_train_v2_cluster.py](https://github.com/PaddlePaddle/Paddle/tree/develop/doc/howto/usage/cluster/src/word2vec/prepare.py). ***NOTE:*** You may need to modify the head part of `train.py` when using different cluster platform to retrive configuration environment variables:
`HOSTS` all nodes hostname or ip that will run cluster job. You can also append user and ssh port with hostname, such as root@192.168.100.17:9090.
`ROOT_DIR` workspace ROOT directory for placing JOB workspace directory
-`train_data_dir`: containing training data. Mount from storage service or copy trainning data to here.
-`test_data_dir`: containing testing data.
`PADDLE_NIC` the NIC(Network Interface Card) interface name for cluster communication channel, such as eth0 for ethternet, ib0 for infiniband.
# Use cluster platforms or cluster management tools
`PADDLE_PORT` port number for cluster commnunication channel
PaddlePaddle supports running jobs on several platforms including:
-[Kubernetes](http://kubernetes.io) open-source system for automating deployment, scaling, and management of containerized applications from Google.
-[OpenMPI](https://www.open-mpi.org) Mature high performance parallel computing framework.
-[Fabric](http://www.fabfile.org) A cluster management tool. Write scripts to submit jobs or manage the cluster.
`PADDLE_PORTS_NUM` the number of port used for cluster communication channle. if the number of cluster nodes is small(less than 5~6nodes), recommend you set it to larger, such as 2 ~ 8, for better network performance.
We'll introduce cluster job management on these platforms. The examples can be found under [cluster_train_v2](https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/scripts/cluster_train_v2).
`PADDLE_PORTS_NUM_FOR_SPARSE` the number of port used for sparse updater cluster commnunication channel. if sparse remote update is used, set it like `PADDLE_PORTS_NUM`
These cluster platforms provide API or environment variables for training processes, when the job is dispatched to different nodes. Like node ID, IP or total number of nodes etc.
`LD_LIBRARY_PATH` set addtional LD_LIBRARY_PATH for cluster job. You can use it to set CUDA libraries path.
## Cluster Training Using Fabric
Default Configuration as follow:
### Prepare a Linux cluster
```python
Run `kubectl -f ssh_servers.yaml` under the directory: `paddle/scripts/cluster_train_v2/fabric/docker_cluster` will launch a demo cluster. Run `kubectl get po -o wide` to get IP addresses of these nodes.
HOSTS=[
"root@192.168.100.17",
"root@192.168.100.18",
]
'''
workspace configuration
'''
#root dir for workspace
ROOT_DIR="/home/paddle"
'''
network configuration
'''
#pserver nics
PADDLE_NIC="eth0"
#pserver port
PADDLE_PORT=7164
#pserver ports num
PADDLE_PORTS_NUM=2
#pserver sparse ports num
PADDLE_PORTS_NUM_FOR_SPARSE=2
#environments setting for all processes in cluster job
`paddle.py` provides automatical scripts to start all PaddlePaddle cluster processes in different nodes. By default, all command line options can set as `paddle.py` command options and `paddle.py` will transparently and automatically set these options to PaddlePaddle lower level processes.
`paddle.py` provides automatical scripts to start all PaddlePaddle cluster processes in different nodes. By default, all command line options can be set as `paddle.py` command options and `paddle.py` will transparently and automatically set these options to PaddlePaddle lower level processes.
`paddle.py`provides two distinguished command option for easy job launching.
`paddle.py`provides two distinguished command option for easy job launching.
`job_dispatch_package` set it with local `workspace`directory, it will be dispatched to all nodes set in conf.py. It could be helpful for frequent hacking workspace files, otherwise frequent mulit-nodes workspace deployment could make your crazy.
-`job_dispatch_package` set it with local `workspace` directory, it will be dispatched to all nodes which is set in `conf.py`. It could be helpful for frequently manipulating workspace files. otherwise, frequent multi-nodes workspace deployment is very annoying.
`job_workspace` set it with already deployed workspace directory, `paddle.py` will skip dispatch stage to directly launch cluster job with all nodes. It could help to reduce heavy
-`job_workspace` set it with already deployed workspace directory, `paddle.py` will skip dispatch stage to directly launch cluster job with all nodes. It could help to reduce heavy
dispatch latency.
dispatch latency.
`cluster_train/run.sh` provides command line sample to run `demo/recommendation` cluster job, just modify `job_dispatch_package` and `job_workspace` with your defined directory, then:
`cluster_train/run.sh` provides command line sample to run `demo/recommendation` cluster job, just modify `job_dispatch_package` and `job_workspace` with your defined directory, then:
...
@@ -134,23 +225,69 @@ sh run.sh
...
@@ -134,23 +225,69 @@ sh run.sh
The cluster Job will start in several seconds.
The cluster Job will start in several seconds.
### Kill Cluster Job
### Kill Cluster Job
`paddle.py` can capture `Ctrl + C` SIGINT signal to automatically kill all processes launched by it. So just stop `paddle.py` to kill cluster job. You should mannally kill job if program crashed.
`paddle.py` can capture `Ctrl + C` SIGINT signal to automatically kill all processes launched by it. So just stop `paddle.py` to kill cluster job. You should manually kill the job if the program crashed.
### Check Cluster Training Result
### Check Cluster Training Result
Check log in $workspace/log for details, each node owns same log structure.
Check log in $workspace/log for details, each node owns same log structure.
`paddle_trainer.INFO`
`paddle_trainer.INFO`
It provides almost all interal output log for training, same as local training. Check runtime model convergence here.
It provides almost all internal output log for training, same as local training. Check runtime model convergence here.
`paddle_pserver2.INFO`
`paddle_pserver2.INFO`
It provides pserver running log, which could help to diagnose distributed error.
It provides parameter server running log, which could help to diagnose distributed error.
`server.log`
`server.log`
It provides stderr and stdout of pserver process. Check error log if training crashs.
It provides stderr and stdout of parameter server process. Check error log if training crashes.
`train.log`
`train.log`
It provides stderr and stdout of trainer process. Check error log if training crashs.
It provides stderr and stdout of trainer process. Check error log if training crashes.
### Check Model Output
### Check Model Output
After one pass finished, model files will be writed in `output` directory in node 0.
After one pass finished, model files will be written in `output` directory in node 0.
`nodefile` in workspace indicates the node id of current cluster job.
`nodefile` in workspace indicates the node id of current cluster job.
## Cluster Training Using OpenMPI
### Prepare an OpenMPI cluster
Run the following command to start a 3-node MPI cluster and one "head" node.
```bash
cd paddle/scripts/cluster_train_v2/openmpi/docker_cluster
kubectl create -f head.yaml
kubectl create -f mpi-nodes.yaml
```
Then you can log in to every OpenMPI node using ssh without input any passwords.
### Launching Cluster Job
Follow the steps to launch a PaddlePaddle training job in OpenMPI cluster:\
```bash
# find out node IP addresses
kubectl get po -o wide
# generate a "machines" file containing node IP addresses
kubectl get po -o wide | grep nodes | awk'{print $6}'> machines
{kind=link}
{kind=link}