Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Crayon鑫
Paddle
提交
2d1d677e
P
Paddle
项目概览
Crayon鑫
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
2d1d677e
编写于
4月 08, 2018
作者:
L
Liu Yiqun
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' into core_inference_multi_thread
上级
208fcf52
3874c383
变更
17
显示空白变更内容
内联
并排
Showing
17 changed file
with
319 addition
and
261 deletion
+319
-261
doc/design/file_manager/README.md
doc/design/file_manager/README.md
+0
-87
doc/design/file_manager/pfs/pfsclient.md
doc/design/file_manager/pfs/pfsclient.md
+0
-129
doc/design/file_manager/src/filemanager.graffle
doc/design/file_manager/src/filemanager.graffle
+0
-0
doc/design/file_manager/src/filemanager.png
doc/design/file_manager/src/filemanager.png
+0
-0
doc/fluid/dev/index_cn.rst
doc/fluid/dev/index_cn.rst
+1
-1
doc/fluid/dev/index_en.rst
doc/fluid/dev/index_en.rst
+1
-1
doc/fluid/dev/releasing_process_cn.md
doc/fluid/dev/releasing_process_cn.md
+30
-24
doc/fluid/dev/releasing_process_en.md
doc/fluid/dev/releasing_process_en.md
+210
-0
paddle/fluid/operators/reader/create_batch_reader_op.cc
paddle/fluid/operators/reader/create_batch_reader_op.cc
+5
-2
paddle/fluid/operators/reader/create_double_buffer_reader_op.cc
.../fluid/operators/reader/create_double_buffer_reader_op.cc
+5
-2
paddle/fluid/operators/reader/create_multi_pass_reader_op.cc
paddle/fluid/operators/reader/create_multi_pass_reader_op.cc
+6
-3
paddle/fluid/operators/reader/create_shuffle_reader_op.cc
paddle/fluid/operators/reader/create_shuffle_reader_op.cc
+6
-2
paddle/fluid/pybind/tensor_py.h
paddle/fluid/pybind/tensor_py.h
+1
-0
python/paddle/fluid/framework.py
python/paddle/fluid/framework.py
+14
-0
python/paddle/fluid/layers/io.py
python/paddle/fluid/layers/io.py
+37
-8
python/paddle/fluid/tests/unittests/test_recordio_reader.py
python/paddle/fluid/tests/unittests/test_recordio_reader.py
+2
-2
python/setup.py.in
python/setup.py.in
+1
-0
未找到文件。
doc/design/file_manager/README.md
已删除
100644 → 0
浏览文件 @
208fcf52
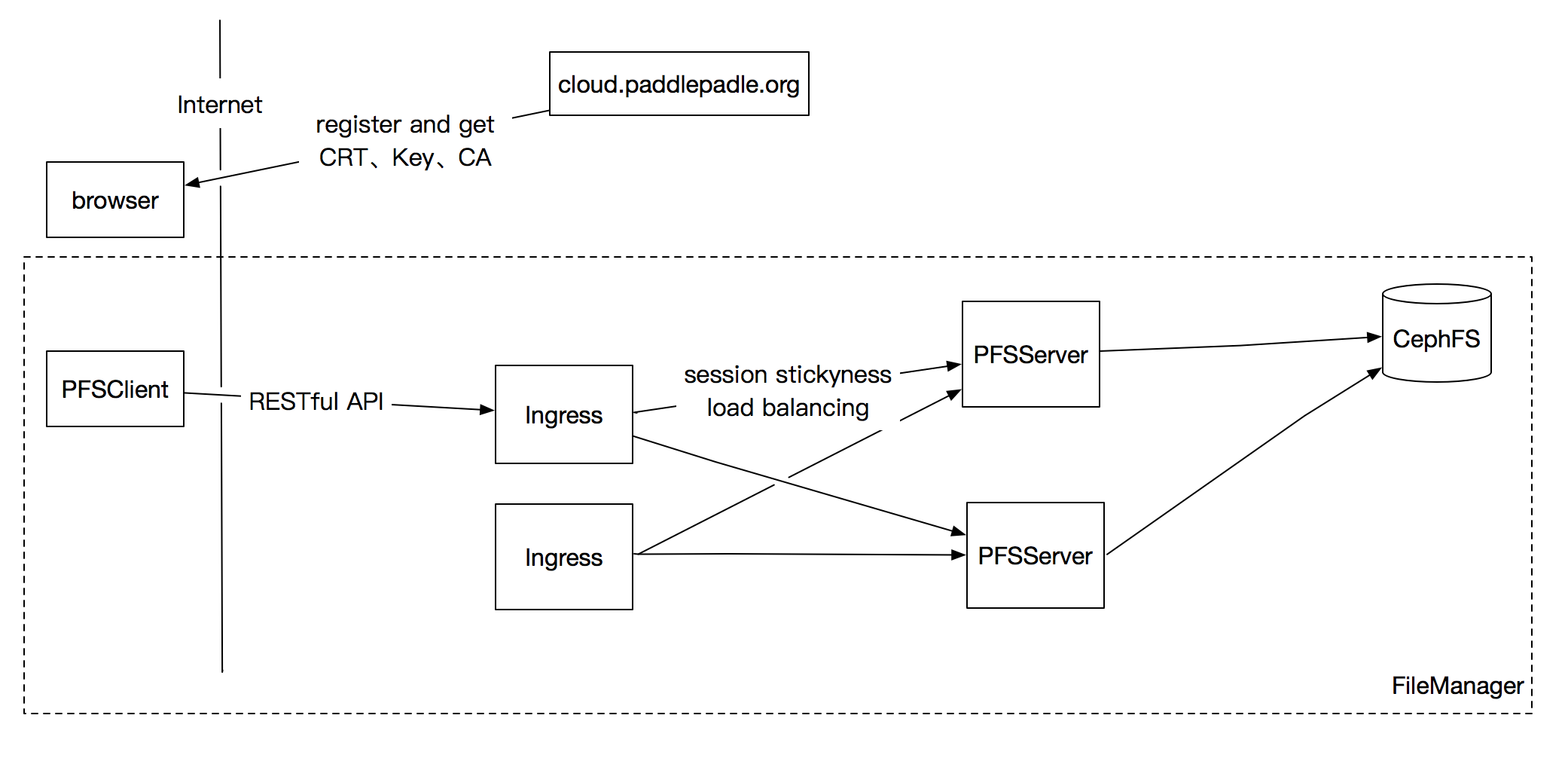
# FileManager设计文档
## 目标
在本文档中,我们设计说明了名为FileManager系统,方便用户上传自己的训练数据以进行分布式训练
主要功能包括:
-
提供常用的命令行管理命令管理文件和目录
-
支持大文件的断点上传、下载
## 名词解释
-
PFS:是
`Paddlepaddle cloud File System`
的缩写,是对用户文件存储空间的抽象,与之相对的是local filesystem。目前我们用CephFS来搭建。
-
[
CephFS
](
http://docs.ceph.com/docs/master/cephfs/
)
:一个POSIX兼容的文件系统。
-
Chunk:逻辑划上文件分块的单位。
## 模块
### 架构图
<image
src=
./src/filemanager.png
width=
900
>
### PFSClient
-
功能: 详细设计
[
link
](
./pfs/pfsclient.md
)
-
提供用户管理文件的命令
-
需要可以跨平台执行
-
双向验证
PFSClient需要和Ingress之间做双向验证
<sup>
[
tls
](
#tls
)
</sup>
,所以用户需要首先在
`cloud.paddlepaddle.org`
上注册一下,申请用户空间,并且把系统生成的CA(certificate authority)、Key、CRT(CA signed certificate)下载到本地,然后才能使用PFSClient。
### [Ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/)
-
功能:
提供七层协议的反向代理、基于粘性会话的负载均衡功能。
-
透传用户身份的办法
Ingress需要把PFSClient的身份信息传给PFSServer,配置的方法参考
[
link
](
http://www.integralist.co.uk/posts/clientcertauth.html#3
)
### PFSServer
PFSServer提供RESTful API接口,接收处理PFSClient端的文件管理请求,并且把结果返回PFSClient端。
RESTful API
-
/api/v1/files
-
`GET /api/v1/files`
: Get metadata of files or directories.
-
`POST /api/v1/files`
: Create files or directories.
-
`PATCH /api/v1/files`
: Update files or directories.
-
`DELETE /api/v1/files`
: Delete files or directories.
-
/api/v1/file/chunks
-
`GET /api/v1/storage/file/chunks`
: Get chunks's metadata of a file.
-
/api/v1/storage/files
-
`GET /api/v1/storage/files`
: Download files or directories.
-
`POST /api/v1/storage/files`
: Upload files or directories.
-
/api/v1/storage/file/chunks
-
`GET /api/v1/storage/file/chunks`
: Download chunks's data.
-
`POST /api/v1/storage/file/chunks`
: Upload chunks's data.
## 文件传输优化
### 分块文件传输
用户文件可能是比较大的,上传到Cloud或者下载到本地的时间可能比较长,而且在传输的过程中也可能出现网络不稳定的情况。为了应对以上的问题,我们提出了Chunk的概念,一个Chunk由所在的文件偏移、数据、数据长度及校验值组成。文件的上传和下载都是通过对Chunk的操作来实现的。由于Chunk比较小(默认256K),完成一个传输动作完成的时间也比较短,不容易出错。PFSClient需要在传输完毕最后一个Chunk的时候检查destination文件的MD5值是否和source文件一致。
一个典型的Chunk如下所示:
```
type Chunk struct {
fileOffset int64
checksum uint32
len uint32
data []byte
}
```
### 生成sparse文件
当destination文件不存在或者大小和source文件不一致时,可以用
[
Fallocate
](
https://Go.org/pkg/syscall/#Fallocate
)
生成sparse文件,然后就可以并发写入多个Chunk。
### 覆盖不一致的部分
文件传输的的关键在于需要PFSClient端对比source和destination的文件Chunks的checksum是否保持一致,不一致的由PFSClient下载或者传输Chunk完成。这样已经传输成功的部分就不用重新传输了。
## 用户使用流程
参考
[
link
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/cluster_train/data_dispatch.md
)
## 框架生成
用
[
swagger
](
https://github.com/swagger-api/swagger-codegen
)
生成PFSClient和PFSServer的框架部分,以便我们可以把更多的精力放到逻辑本身上。
## 参考文档
-
<a
name=
tls
></a>
[
TLS complete guide
](
https://github.com/k8sp/tls/blob/master/tls.md
)
-
[
aws.s3
](
http://docs.aws.amazon.com/cli/latest/reference/s3/
)
-
[
linux man document
](
https://linux.die.net/man/
)
doc/design/file_manager/pfs/pfsclient.md
已删除
100644 → 0
浏览文件 @
208fcf52
# PFSClient
## Description
The
`pfs`
command is a Command Line Interface to manage your files on PaddlePaddle Cloud
## Synopsis
```
paddle [options] pfs <subcommand> [parameters]
```
## Options
```
--profile (string)
Use a specific profile from your credential file.
--help (string)
Display more information about command
--version
Output version information and exit
--debug
Show detailed debugging log
--only-show-errors (boolean)
Only errors and warnings are displayed. All other output is suppressed.
```
## Path Arguments
When using a command, we need to specify path arguments. There are two path argument type:
`localpath`
and
`pfspath`
.
A
`pfspath`
begin with
`/pfs`
, eg:
`/pfs/$DATACENTER/home/$USER/folder`
.
[
Here
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/cluster_train/data_dispatch.md#上传训练文件
)
is how to config datacenters.
## order of Path Arguments
Commonly, if there are two path arguments, the first is the source, and the second is the destination.
## Subcommonds
-
rm - remove files or directories
```
Synopsis:
rm [-r] [-v] <PFSPath> ...
Options:
-r
Remove directories and their contents recursively
-v
Cause rm to be verbose, showing files after they are removed.
Examples:
paddle pfs rm /pfs/$DATACENTER/home/$USER/file
paddle pfs rm -r /pfs/$DATACENTER/home/$USER/folder
```
-
mv - move (rename) files
```
Synopsis:
mv [-f | -n] [-v] <LocalPath> <PFSPath>
mv [-f | -n] [-v] <LocalPath> ... <PFSPath>
mv [-f | -n] [-v] <PFSPath> <LocalPath>
mv [-f | -n] [-v] <PFSPath> ... <LocalPath>
mv [-f | -n] [-v] <PFSPath> <PFSPath>
mv [-f | -n] [-v] <PFSPath> ... <PFSPath>
Options:
-f
Do not prompt for confirmation before overwriting the destination path. (The -f option overrides previous -n options.)
-n
Do not overwrite an existing file. (The -n option overrides previous -f options.)
-v
Cause mv to be verbose, showing files after they are moved.
Examples:
paddle pfs mv ./text1.txt /pfs/$DATACENTER/home/$USER/text1.txt
```
-
cp - copy files or directories
```
Synopsis:
cp [-r] [-f | -n] [-v] [--preserve--links] <LocalPath> <PFSPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <LocalPath> ... <PFSPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> <LocalPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> ... <LocalPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> <PFSPath>
cp [-r] [-f | -n] [-v] [--preserve--links] <PFSPath> ... <PFSPath>
Options:
-r
Copy directories recursively
-f
Do not prompt for confirmation before overwriting the destination path. (The -f option overrides previous -n options.)
-n
Do not overwrite an existing file. (The -n option overrides previous -f options.)
-v
Cause cp to be verbose, showing files after they are copied.
--preserve--links
Reserve links when copy links
Examples:
paddle pfs cp ./file /pfs/$DATACENTER/home/$USER/file
paddle pfs cp /pfs/$DATACENTER/home/$USER/file ./file
```
-
ls- list files
```
Synopsis:
ls [-r] <PFSPath> ...
Options:
-R
List directory(ies) recursively
Examples:
paddle pfs ls /pfs/$DATACENTER/home/$USER/file
paddle pfs ls /pfs/$DATACENTER/home/$USER/folder
```
-
mkdir - mkdir directory(ies)
Create intermediate directory(ies) as required.
```
Synopsis:
mkdir <PFSPath> ...
Examples:
paddle pfs mkdir /pfs/$DATACENTER/home/$USER/folder
```
doc/design/file_manager/src/filemanager.graffle
已删除
100644 → 0
浏览文件 @
208fcf52
文件已删除
doc/design/file_manager/src/filemanager.png
已删除
100644 → 0
浏览文件 @
208fcf52
141.7 KB
doc/fluid/dev/index_cn.rst
浏览文件 @
2d1d677e
...
...
@@ -9,5 +9,5 @@
use_eigen_cn.md
name_convention.md
support_new_device.md
releasing_process.md
releasing_process
_cn
.md
op_markdown_format.md
doc/fluid/dev/index_en.rst
浏览文件 @
2d1d677e
...
...
@@ -9,5 +9,5 @@ Development
use_eigen_en.md
name_convention.md
support_new_device.md
releasing_process.md
releasing_process
_en
.md
op_markdown_format.md
doc/fluid/dev/releasing_process.md
→
doc/fluid/dev/releasing_process
_cn
.md
浏览文件 @
2d1d677e
...
...
@@ -10,19 +10,10 @@ PaddlePaddle每次发新的版本,遵循以下流程:
*
使用Regression Test List作为检查列表,测试本次release的正确性。
*
如果失败,记录下所有失败的例子,在这个
`release/版本号`
分支中,修复所有bug后,Patch号加一,到第二步
*
修改
`python/setup.py.in`
中的版本信息,并将
`istaged`
字段设为
`True`
。
*
编译这个版本的python wheel包,并发布到pypi。
*
由于pypi.python.org目前遵循
[
严格的命名规范PEP 513
](
https://www.python.org/dev/peps/pep-0513
)
,在使用twine上传之前,需要重命名wheel包中platform相关的后缀,比如将
`linux_x86_64`
修改成
`manylinux1_x86_64`
。
*
pypi上的package名称为paddlepaddle和paddlepaddle_gpu,如果要上传GPU版本的包,需要修改build/python/setup.py中,name: "paddlepaddle_gpu"并重新打包wheel包:
`python setup.py bdist_wheel`
。
*
上传方法:
```
cd build/python
pip install twine
twine upload dist/[package to upload]
```
*
编译这个版本的Docker发行镜像,发布到dockerhub。如果失败,修复Docker编译镜像问题,Patch号加一,返回第二步
1.
第三步完成后,将
`release/版本号`
分支合入master分支,并删除
`release/版本号`
分支。将master分支的合入commit打上tag,tag为
`版本号`
。同时再将
`master`
分支合入
`develop`
分支。最后删除
`release/版本号`
分支。
1.
协同完成Release Note的书写
*
将这个版本的python wheel包发布到pypi。
*
更新Docker镜像(参考后面的操作细节)。
1.
第三步完成后,将
`release/版本号`
分支合入master分支,将master分支的合入commit打上tag,tag为
`版本号`
。同时再将
`master`
分支合入
`develop`
分支。
1.
协同完成Release Note的书写。
需要注意的是:
...
...
@@ -31,13 +22,18 @@ PaddlePaddle每次发新的版本,遵循以下流程:
## 发布wheel包到pypi
使用
[
PaddlePaddle CI
](
https://paddleci.ngrok.io/project.html?projectId=Manylinux1&tab=projectOverview
)
1.
使用
[
PaddlePaddle CI
](
https://paddleci.ngrok.io/project.html?projectId=Manylinux1&tab=projectOverview
)
完成自动化二进制编译,参考下图,选择需要发布的版本(通常包含一个CPU版本和一个GPU版本),点击"run"右侧的"..."按钮,可以
弹出下面的选择框,在第二个tab (Changes)里选择需要发布的分支,这里选择0.11.0,然后点击"Run Build"按钮。等待编译完成后
可以在此页面的"Artifacts"下拉框中找到生成的3个二进制文件,分别对应CAPI,
`cp27m`
和
`cp27mu`
的版本。然后按照上述的方法
使用
`twine`
工具上传即可。
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/Paddle/develop/doc/fluid/images/ci_build_whl.png"
>
弹出下面的选择框,在第二个tab (Changes)里选择需要发布的分支,这里选择0.11.0,然后点击"Run Build"按钮。
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/Paddle/develop/doc/fluid/images/ci_build_whl.png"
>
1.
等待编译完成后可以在此页面的"Artifacts"下拉框中找到生成的3个二进制文件,分别对应CAPI,
`cp27m`
和
`cp27mu`
的版本。
1.
由于pypi.python.org目前遵循
[
严格的命名规范PEP 513
](
https://www.python.org/dev/peps/pep-0513
)
,在使用twine上传之前,需要重命名wheel包中platform相关的后缀,比如将
`linux_x86_64`
修改成
`manylinux1_x86_64`
。
1.
上传:
```
cd build/python
pip install twine
twine upload dist/[package to upload]
```
*
注:CI环境使用 https://github.com/PaddlePaddle/buildtools 这里的DockerImage作为编译环境以支持更多的Linux
发型版,如果需要手动编译,也可以使用这些镜像。这些镜像也可以从 https://hub.docker.com/r/paddlepaddle/paddle_manylinux_devel/tags/ 下载得到。
...
...
@@ -48,10 +44,20 @@ PaddlePaddle每次发新的版本,遵循以下流程:
上述PaddlePaddle CI编译wheel完成后会自动将Docker镜像push到DockerHub,所以,发布Docker镜像只需要对自动push的镜像打上
版本号对应的tag即可:
1.
进入 https://hub.docker.com/r/paddlepaddle/paddle/tags/ 查看latest tag的更新时间是否在上述编译wheel包完成后是否最新。
1.
执行
`docker pull paddlepaddle/paddle:[latest tag]`
,latest tag可以是latest或latest-gpu等。
1.
执行
`docker tag paddlepaddle/paddle:[latest tag] paddlepaddle/paddle:[version]`
1.
执行
`docker push paddlepaddle/paddle:[version]`
```
docker pull [镜像]:latest
docker tag [镜像]:latest [镜像]:[version]
docker push [镜像]:[version]
```
需要更新的镜像tag包括:
*
`[version]`
: CPU版本
*
`[version]-openblas`
: openblas版本
*
`[version]-gpu`
: GPU版本(CUDA 8.0 cudnn 5)
*
`[version]-gpu-[cudaver]-[cudnnver]`
: 不同cuda, cudnn版本的镜像
之后可进入 https://hub.docker.com/r/paddlepaddle/paddle/tags/ 查看是否发布成功。
## PaddlePaddle 分支规范
...
...
@@ -76,7 +82,7 @@ PaddlePaddle开发过程使用[git-flow](http://nvie.com/posts/a-successful-git-
### PaddlePaddle Book中所有章节
PaddlePaddle每次发版本首先要保证PaddlePaddle Book中所有章节功能的正确性。功能的正确性包括验证PaddlePaddle目前的
`paddle_trainer`
训练和纯使用
`Python`
训练模型正确性。
PaddlePaddle每次发版本首先要保证PaddlePaddle Book中所有章节功能的正确性。功能的正确性包括验证PaddlePaddle目前的
`paddle_trainer`
训练和纯使用
`Python`
训练
(V2和Fluid)
模型正确性。
<table>
<thead>
...
...
doc/fluid/dev/releasing_process_en.md
0 → 100644
浏览文件 @
2d1d677e
# PaddlePaddle Releasing Process
PaddlePaddle manages its branches using "git-flow branching model", and
[
Semantic Versioning
](
http://semver.org/
)
as it's version number semantics.
Each time we release a new PaddlePaddle version, we should follow the below steps:
1.
Fork a new branch from
`develop`
named
`release/[version]`
, e.g.
`release/0.10.0`
.
1.
Push a new tag on the release branch, the tag name should be like
`[version]rc.patch`
. The
first tag should be
`0.10.0rc1`
, and the second should be
`0.10.0.rc2`
and so on.
1.
After that, we should do:
*
Run all regression test on the Regression Test List (see PaddlePaddle TeamCity CI), to confirm
that this release has no major bugs.
*
If regression test fails, we must fix those bugs and create a new
`release/[version]`
branch from previous release branch.
*
Modify
`python/setup.py.in`
, change the version number and change
`ISTAGED`
to
`True`
.
*
Publish PaddlePaddle release wheel packages to pypi (see below instructions for detail).
*
Update the Docker images (see below instructions for detail).
1.
After above step, merge
`release/[version]`
branch to master and push a tag on the master commit,
then merge
`master`
to
`develop`
.
1.
Update the Release Note.
***NOTE:**
*
*
Do
***NOT**
*
merge commits from develop branch to release branches to keep the release branch contain
features only for current release, so that we can test on that version.
*
If we want to fix bugs on release branches, we must merge the fix to master, develop and release branch.
## Publish Wheel Packages to pypi
1.
Use our
[
CI tool
](
https://paddleci.ngrok.io/project.html?projectId=Manylinux1&tab=projectOverview
)
to build all wheel packages needed to publish. As shown in the following picture, choose a build
version, click "..." button on the right side of "Run" button, and switch to the second tab in the
pop-up box, choose the current release branch and click "Run Build" button. You may repeat this
step to start different versions of builds.
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/Paddle/develop/doc/fluid/images/ci_build_whl.png"
>
1.
After the build succeeds, download the outputs under "Artifacts" including capi,
`cp27m`
and
`cp27mu`
.
1.
Since pypi.python.org follows
[
PEP 513
](
https://www.python.org/dev/peps/pep-0513
)
, before we
upload the package using
`twine`
, we need to rename the package from
`linux_x86_64`
to
`manylinux1_x86_64`
.
1.
Start the upload:
```
cd build/python
pip install twine
twine upload dist/[package to upload]
```
*
NOTE: We use a special Docker image to build our releases to support more Linux distributions, you can
download it from https://hub.docker.com/r/paddlepaddle/paddle_manylinux_devel/tags/, or build it using
scripts under
`tools/manylinux1`
.
*
pypi does not allow overwrite the already uploaded version of wheel package, even if you delete the
old version. you must change the version number before upload a new one.
## Publish Docker Images
Our CI tool will push latest images to DockerHub, so we only need to push a version tag like:
```
docker pull [image]:latest
docker tag [image]:latest [image]:[version]
docker push [image]:[version]
```
Tags that need to be updated are:
*
`[version]`
: CPU only version image
*
`[version]-openblas`
: openblas version image
*
`[version]-gpu`
: GPU version(using CUDA 8.0 cudnn 5)
*
`[version]-gpu-[cudaver]-[cudnnver]`
: tag for different cuda, cudnn versions
You can then checkout the latest pushed tags at https://hub.docker.com/r/paddlepaddle/paddle/tags/.
## Branching Model
We use
[
git-flow
](
http://nvie.com/posts/a-successful-git-branching-model/
)
as our branching model,
with some modifications:
*
`master`
branch is the stable branch. Each version on the master branch is tested and guaranteed.
*
`develop`
branch is for development. Each commit on develop branch has passed CI unit test, but no
regression tests are run.
*
`release/[version]`
branch is used to publish each release. Latest release version branches have
bugfix only for that version, but no feature updates.
*
Developer forks are not required to follow
[
git-flow
](
http://nvie.com/posts/a-successful-git-branching-model/
)
branching model, all forks is like a feature branch.
*
Advise: developer fork's develop branch is used to sync up with main repo's develop branch.
*
Advise: developer use it's fork's develop branch to for new branch to start developing.
*
Use that branch on developer's fork to create pull requests and start reviews.
*
developer can push new commits to that branch when the pull request is open.
*
Bug fixes are also started from developers forked repo. And, bug fixes branch can merge to
`master`
,
`develop`
and
`releases`
.
## PaddlePaddle Regression Test List
### All Chapters of PaddlePaddle Book
We need to guarantee that all the chapters of PaddlePaddle Book can run correctly. Including
V1 (
`paddle_trainer`
training) and V2 training and Fluid training.
<table>
<thead>
<tr>
<th></th>
<th>
Linear Regression
</th>
<th>
Recognize Digits
</th>
<th>
Image Classification
</th>
<th>
Word2Vec
</th>
<th>
Personalized Recommendation
</th>
<th>
Sentiment Analysis
</th>
<th>
Semantic Role Labeling
</th>
<th>
Machine Translation
</th>
</tr>
</thead>
<tbody>
<tr>
<td>
API.V2 + Docker + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
API.V2 + Docker + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Docker + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Docker + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
API.V2 + Ubuntu + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
API.V2 + Ubuntu + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Ubuntu + GPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
<tr>
<td>
`paddle_trainer`
+ Ubuntu + CPU
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
<td>
</td>
</tr>
</tbody>
</table>
paddle/fluid/operators/reader/create_batch_reader_op.cc
浏览文件 @
2d1d677e
...
...
@@ -39,10 +39,13 @@ class CreateBatchReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
*
out
=
scope
.
FindVar
(
Output
(
"Out"
))
->
template
GetMutable
<
framework
::
ReaderHolder
>();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
out
->
Reset
(
new
BatchReader
(
underlying_reader
.
Get
(),
Attr
<
int
>
(
"batch_size"
)));
}
...
...
paddle/fluid/operators/reader/create_double_buffer_reader_op.cc
浏览文件 @
2d1d677e
...
...
@@ -99,10 +99,13 @@ class CreateDoubleBufferReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
*
out
=
scope
.
FindVar
(
Output
(
"Out"
))
->
template
GetMutable
<
framework
::
ReaderHolder
>();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
place_str
=
Attr
<
std
::
string
>
(
"place"
);
platform
::
Place
place
;
...
...
paddle/fluid/operators/reader/create_multi_pass_reader_op.cc
浏览文件 @
2d1d677e
...
...
@@ -62,12 +62,15 @@ class CreateMultiPassReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
auto
*
out
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)))
.
GetMutable
<
framework
::
ReaderHolder
>
();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
&
out
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)));
int
pass_num
=
Attr
<
int
>
(
"pass_num"
);
out
.
GetMutable
<
framework
::
ReaderHolder
>
()
->
Reset
(
new
MultiPassReader
(
underlying_reader
.
Get
(),
pass_num
));
out
->
Reset
(
new
MultiPassReader
(
underlying_reader
.
Get
(),
pass_num
));
}
};
...
...
paddle/fluid/operators/reader/create_shuffle_reader_op.cc
浏览文件 @
2d1d677e
...
...
@@ -80,10 +80,14 @@ class CreateShuffleReaderOp : public framework::OperatorBase {
private:
void
RunImpl
(
const
framework
::
Scope
&
scope
,
const
platform
::
Place
&
dev_place
)
const
override
{
auto
*
out
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)))
.
GetMutable
<
framework
::
ReaderHolder
>
();
if
(
out
->
Get
()
!=
nullptr
)
{
return
;
}
const
auto
&
underlying_reader
=
scope
.
FindVar
(
Input
(
"UnderlyingReader"
))
->
Get
<
framework
::
ReaderHolder
>
();
auto
&
var
=
detail
::
Ref
(
scope
.
FindVar
(
Output
(
"Out"
)));
var
.
GetMutable
<
framework
::
ReaderHolder
>
()
->
Reset
(
out
->
Reset
(
new
ShuffleReader
(
underlying_reader
.
Get
(),
static_cast
<
size_t
>
(
Attr
<
int
>
(
"buffer_size"
))));
}
...
...
paddle/fluid/pybind/tensor_py.h
浏览文件 @
2d1d677e
...
...
@@ -13,6 +13,7 @@ See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <Python.h>
#include <string>
#include <tuple>
#include <vector>
...
...
python/paddle/fluid/framework.py
浏览文件 @
2d1d677e
...
...
@@ -640,6 +640,20 @@ class Operator(object):
"""
return
self
.
desc
.
block_attr
(
name
)
def
all_attrs
(
self
):
"""
Get the attribute dict
Returns(dict): The Operator's attribute dict
"""
attr_names
=
self
.
attr_names
attr_map
=
{}
for
n
in
attr_names
:
if
n
==
'sub_block'
:
attr_map
[
n
]
=
self
.
block_attr
(
n
)
else
:
attr_map
[
n
]
=
self
.
attr
(
n
)
return
attr_map
class
Block
(
object
):
def
__init__
(
self
,
program
,
idx
):
...
...
python/paddle/fluid/layers/io.py
浏览文件 @
2d1d677e
...
...
@@ -255,7 +255,32 @@ def _copy_reader_var_(block, var):
new_var
.
desc
.
set_shapes
(
var
.
desc
.
shapes
())
new_var
.
desc
.
set_dtypes
(
var
.
desc
.
dtypes
())
new_var
.
persistable
=
True
return
monkey_patch_reader_methods
(
new_var
)
return
new_var
def
_copy_reader_create_op_
(
block
,
op
):
input_param_names
=
op
.
input_names
new_input_map
=
{}
for
param_name
in
input_param_names
:
new_input_map
[
param_name
]
=
[]
arg_names
=
op
.
input
(
param_name
)
for
arg_name
in
arg_names
:
new_input_map
[
param_name
].
append
(
block
.
var
(
arg_name
))
output_param_names
=
op
.
output_names
new_output_map
=
{}
for
param_name
in
output_param_names
:
new_output_map
[
param_name
]
=
[]
arg_names
=
op
.
output
(
param_name
)
for
arg_name
in
arg_names
:
new_output_map
[
param_name
].
append
(
block
.
var
(
arg_name
))
new_op
=
block
.
append_op
(
type
=
op
.
type
,
inputs
=
new_input_map
,
outputs
=
new_output_map
,
attrs
=
op
.
all_attrs
())
return
new_op
def
open_recordio_file
(
filename
,
shapes
,
lod_levels
,
dtypes
):
...
...
@@ -283,8 +308,9 @@ def open_recordio_file(filename, shapes, lod_levels, dtypes):
startup_var
.
desc
.
set_dtypes
(
dtypes
)
startup_var
.
persistable
=
True
return
_copy_reader_var_
(
default_main_program
().
current_block
(),
main_prog_var
=
_copy_reader_var_
(
default_main_program
().
current_block
(),
startup_var
)
return
monkey_patch_reader_methods
(
main_prog_var
)
def
open_files
(
filenames
,
thread_num
,
shapes
,
lod_levels
,
dtypes
):
...
...
@@ -313,22 +339,25 @@ def open_files(filenames, thread_num, shapes, lod_levels, dtypes):
startup_var
.
desc
.
set_dtypes
(
dtypes
)
startup_var
.
persistable
=
True
return
_copy_reader_var_
(
default_main_program
().
current_block
(),
main_prog_var
=
_copy_reader_var_
(
default_main_program
().
current_block
(),
startup_var
)
return
monkey_patch_reader_methods
(
main_prog_var
)
def
__create_decorated_reader__
(
op_type
,
reader
,
attrs
):
var_name
=
unique_name
(
op_type
)
startup_blk
=
default_startup_program
().
current_block
()
startup_var
=
startup_blk
.
create_var
(
name
=
var_name
)
startup_blk
.
append_op
(
start
op_op
=
start
up_blk
.
append_op
(
type
=
op_type
,
inputs
=
{
'UnderlyingReader'
:
reader
},
outputs
=
{
'Out'
:
[
startup_var
]},
attrs
=
attrs
)
startup_var
.
persistable
=
True
return
_copy_reader_var_
(
default_main_program
().
current_block
(),
startup_var
)
main_prog_block
=
default_main_program
().
current_block
()
main_prog_var
=
_copy_reader_var_
(
main_prog_block
,
startup_var
)
_copy_reader_create_op_
(
main_prog_block
,
startop_op
)
return
monkey_patch_reader_methods
(
main_prog_var
)
def
create_shuffle_reader
(
reader
,
buffer_size
):
...
...
python/paddle/fluid/tests/unittests/test_recordio_reader.py
浏览文件 @
2d1d677e
...
...
@@ -15,8 +15,8 @@
import
unittest
import
paddle.fluid
as
fluid
import
paddle
import
paddle.dataset.mnist
as
mnist
import
paddle
.v2
as
paddle
import
paddle.
v2.
dataset.mnist
as
mnist
class
TestRecordIO
(
unittest
.
TestCase
):
...
...
python/setup.py.in
浏览文件 @
2d1d677e
...
...
@@ -107,6 +107,7 @@ package_dir={
# So that package points to other directory.
'paddle.fluid.proto.profiler': '${PADDLE_BINARY_DIR}/paddle/fluid/platform',
'paddle.fluid.proto': '${PADDLE_BINARY_DIR}/paddle/fluid/framework',
'paddle.fluid': '${PADDLE_BINARY_DIR}/python/paddle/fluid',
}
if '${WITH_FLUID_ONLY}'== 'OFF':
package_dir['py_paddle']='${PADDLE_BINARY_DIR}/python/py_paddle'
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}