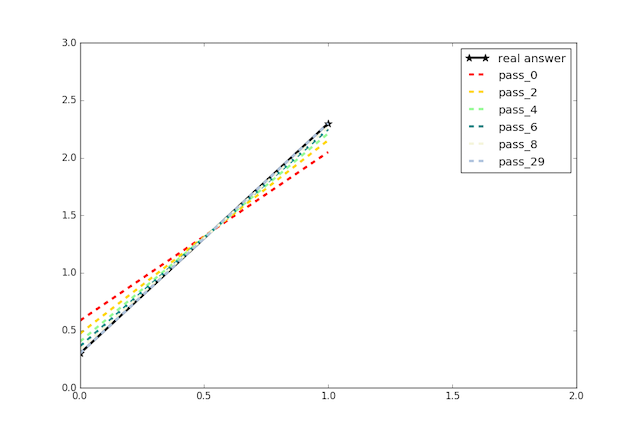
Adding an introduction doc for Paddle to implement simplest linear regression.
Showing
demo/introduction/README.md
0 → 100644
demo/introduction/dataprovider.py
0 → 100644
demo/introduction/train.sh
0 → 100755
doc/introduction/index.md
0 → 100644
doc/introduction/parameters.png
0 → 120000
{kind=link}
doc_cn/introduction/index.md
0 → 100644
{kind=link}
43.4 KB