 +
+
+
+
以每一个词为中心词X,然后在窗口内和临近的词Y组成样本对(X,Y)用于网络训练。在实际训练过程中还会根据自定义的负采样率生成负样本来加强训练的效果 具体的训练思路如下: -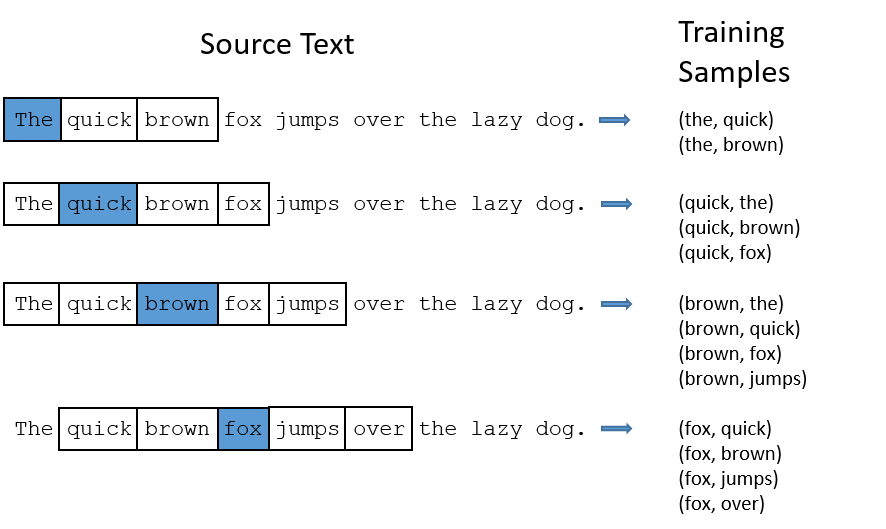 +
+ +
+
推荐用户参考[ IPython Notebook demo](https://aistudio.baidu.com/aistudio/projectDetail/124377)教程获取更详细的信息。 diff --git a/models/recall/word2vec/config.yaml b/models/recall/word2vec/config.yaml index 34a25e59ecfa4ccd292a3b6e358c83ac827ed59f..3e8347a94748560e85734a4c5a68d4b529c29ba4 100755 --- a/models/recall/word2vec/config.yaml +++ b/models/recall/word2vec/config.yaml @@ -42,38 +42,40 @@ hyper_parameters: window_size: 5 # select runner by name -mode: train_runner +mode: [single_cpu_train, single_cpu_infer] # config of each runner. # runner is a kind of paddle training class, which wraps the train/infer process. runner: -- name: train_runner +- name: single_cpu_train class: train # num of epochs - epochs: 2 + epochs: 5 # device to run training or infer device: cpu save_checkpoint_interval: 1 # save model interval of epochs save_inference_interval: 1 # save inference - save_checkpoint_path: "increment" # save checkpoint path - save_inference_path: "inference" # save inference path + save_checkpoint_path: "increment_w2v" # save checkpoint path + save_inference_path: "inference_w2v" # save inference path save_inference_feed_varnames: [] # feed vars of save inference save_inference_fetch_varnames: [] # fetch vars of save inference init_model_path: "" # load model path print_interval: 1 -- name: infer_runner + phases: [phase1] +- name: single_cpu_infer class: infer # device to run training or infer device: cpu - init_model_path: "increment/0" # load model path + init_model_path: "increment_w2v" # load model path print_interval: 1 + phases: [phase2] # runner will run all the phase in each epoch phase: - name: phase1 model: "{workspace}/model.py" # user-defined model dataset_name: dataset_train # select dataset by name + thread_num: 5 +- name: phase2 + model: "{workspace}/model.py" # user-defined model + dataset_name: dataset_infer # select dataset by name thread_num: 1 -# - name: phase2 -# model: "{workspace}/model.py" # user-defined model -# dataset_name: dataset_infer # select dataset by name -# thread_num: 1