Text generation Tutorial¶
Sequence to sequence has been proven to be a powerful model for language generation. It can be used for machine translation, query rewriting, image captioning, etc.
This tutorial guides you through training a sequence to sequence model for neural machine translation (NMT) network that translates French to English.
We follow the paper Neural Machine Translation by Jointly Learning to Align and Translate , which details the model architecture and training procedure for good performance on WMT-14 dataset. This tutorial reproduces this result in PaddlePaddle.
We thank @caoying for the pull request that defines the model architecture and solver configurations.
Data Preparation¶
Download and Extract¶
Download the WMT-14 dataset from http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/, extract it, and divide Develop and Test data into separate folder.
- Train data: bitexts (after selection)
- Develop and Test data: dev+test data
To do this, simply run the following commands in linux, otherwise, you need to download, extract, divide, and rename the file suffix respectively.
cd demo/seqToseq/data
./wmt14_data.sh
We should find that the dataset wmt14 has three folders as shown in the following table.
| folder name | French-English parallel corpora file | number of total file | size |
|---|---|---|---|
| train_data | ccb2_pc30.src, ccb2_pc30.trg, etc | twelve | 3.55G |
| test_data | ntst1213.src, ntst1213.trg | two | 1636k |
| gen_data | ntst14.src, ntst14.trg | two | 864k |
- Each folder has French-English parallel corpora
- XXX.src are source French files; XXX.trg are target English files.
- The number of lines of XXX.src and XXX.trg should be the same.
- Each line is a French/English sentence.
- There is a one-to-one correspondence between the sentence at the i-th line of XXX.src and XXX.trg.
User Defined Dataset¶
If you need to do other sequence-to-sequence tasks, such as Paraphrasing, you only need to organize the data as follows, and place them in demo/seqToseq/data:
dataset
train
file1.src file1.trg
file2.src file2.trg
......
test
file1.src file1.trg
file2.src file2.trg
......
gen
file1.src file1.trg
file2.src file2.trg
......
- 1st directory: dataset folder name
- 2nd directory: folder of train, test, and gen. The names of these three folders are fixed.
- 3rd file: Source-Target parallel corpora files.
- XXX.src are source files, XXX.trg are target files.
- Each line of the file must be a sequence.
- There should be a one-to-one correspondence between the i-th sequence of XXX.src and XXX.trg.
Data Preprocess¶
Preprocessing Workflow¶
- Concat each Source-Target parallel corpora to be one file:
- concat each XXX.src and XXX.trg to be XXX.
- the i-th line of XXX = the i-th line of XXX.src + ‘\t’ + the i-th line of XXX.trg
- Build source and target dictionary of train data, each dictionary has DICTSIZE words:
- the most frequent (DICTSIZE-3) words
- 3 special token:
<s>: the start of a sequence<e>: the end of a sequence<unk>: a word not included in dictionary
Preprocessing Command and Result¶
The general command for preprocessing the dataset is:
cd demo/seqToseq/
python preprocess.py -i INPUT [-d DICTSIZE] [-m]
-i INPUT: the path of input original dataset-d DICTSIZE: the specified word count of dictionary, if not set, dictionary will contain all the words in input dataset-m --mergeDict: merge source and target dictionary, thus, two dictionaries have the same context
And you will see messages like this:
concat parallel corpora for dataset
build source dictionary for train data
build target dictionary for train data
dictionary size is XXX
Here, you can simply run the command:
python preprocess.py -i data/wmt14 -d 30000
It will take several minutes, and store the preprocessed dataset in demo/seqToseq/data/pre-wmt14, the directory has following structure.
train test gen train.list test.list gen.list src.dict trg.dict
- train, test, gen: folder contains French-English parallel corpora of train data, test data and gen data respectively. Each line of file in folder contains two parts, the former is a French sequence, and the latter is a corresponding English sequence.
- train.list, test.list, gen.list: text contains a file list in train folder, test folder and gen folder respectively
- src.dict, trg.dict: source (French) / target (English) dictionary, each dictionary has 30000 words: the most frequent 29997 words and 3 special token
Model Training¶
Introduction¶
Neural machine translation (NMT) aims at building a single neural network that can be jointly tuned to maximize translation performance. Recently proposed NMT models often belong to a family of encoder–decoder models. Encoder-Decoder models encode a source sentence into a fixed-length vector from which a decoder generates a target sentence.
In this task, we use an extension to the encoder–decoder model which learns to align and translate jointly. Each time the model generates a word in a translation, it searches for a set of positions in the source sentence for the most relevant information. The decoder predicts a target word based on the context vectors associated with these source positions and all the previous generated target words. For more detailed explanation, readers can refer to paper Neural Machine Translation by Jointly Learning to Align and Translate.
The most distinguishing feature of this model is that it doesn’t encode an input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors, where one vector corresponds to an input element. A subset of these vectors is chosen adaptively while decoding the translated sentence. This frees a NMT model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. The improvement of this model is more apparent for longer sentences, but the improvement can be observed for sentences of any length.
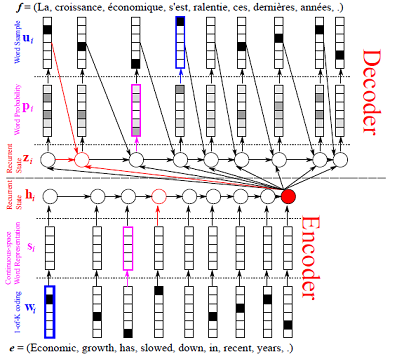
Training Model in PaddlePaddle¶
We need to create a model config file before training. Here is an example demo/seqToseq/translation/train.conf. The first three lines import python function for defining network, and define the job_mode and attention_mode.
from seqToseq_net import *
is_generating = False
### Data Definiation
train_conf = seq_to_seq_data(data_dir = "./data/pre-wmt14",
is_generating = is_generating)
### Algorithm Configuration
settings(
learning_method = AdamOptimizer(),
batch_size = 50,
learning_rate = 5e-4)
### Network Architecture
gru_encoder_decoder(train_conf, is_generating)
- Data Definiation: We define a SeqToSeq train and test data in our example. It returns train_conf as the configuration, following is its input arguments:
- data_dir: directory of train data and test data
- is_generating: whether this config is used for generating, here is false
- Algorithm Configuration: We use the SGD training algorithm (default), ADAM learning method in our example, specify batch_size as 50, and learning rate as 5e-4.
- Network Architecture: We use an attention version of GRU Encoder-Decoder network in our example. It consists a bidirectional GRU as an encoder and a decoder that emulates searching through a source sentence during decoding a translation.
Training Command and Result¶
After writing the model config, we can train the model by running the command:
cd demo/seqToseq/translation
./train.sh
The train.sh is shown as follows:
paddle train \
--config='translation/train.conf' \
--save_dir='translation/model' \
--use_gpu=false \
--num_passes=16 \
--show_parameter_stats_period=100 \
--trainer_count=4 \
--log_period=10 \
--dot_period=5 \
2>&1 | tee 'translation/train.log'
- config: set config of neural network
- save_dir: set output path to save models
- use_gpu: whether to use GPU to train, here use CPU
- num_passes: set number of passes. One pass in paddle means training all samples in dataset one time
- show_parameter_stats_period: here show parameter statistic every 100 batches
- trainer_count: set number of CPU threads or GPU devices
- log_period: here print log every 10 batches
- dot_period: here print ‘.’ every 5 batches
The training loss function is printed every 10 batch by default, and you will see messages like this:
I0719 19:16:45.952062 15563 TrainerInternal.cpp:160] Batch=10 samples=500 AvgCost=198.475 CurrentCost=198.475 Eval: classification_error_evaluator=0.737155 CurrentEval: classification_error_evaluator=0.737155
I0719 19:17:56.707319 15563 TrainerInternal.cpp:160] Batch=20 samples=1000 AvgCost=157.479 CurrentCost=116.483 Eval: classification_error_evaluator=0.698392 CurrentEval: classification_error_evaluator=0.659065
.....
- AvgCost: Average Cost from 0th batch to current batch
- CurrentCost: Cost in current batch
- classification_error_evaluator(Eval): False prediction rate for each word from 0th evaluation to current evaluation
- classification_error_evaluator(CurrentEval): False prediction rate for each word in current evaluation
And when the classification_error_evaluator is less than 0.35, the model is trained sucessfully.
Text Generation¶
Introduction¶
Generally speaking, the NMT model is conditioned on the encodings of the source sentence, and then to predict the next target word by given the current target word. In the training process, the current word is always knowns as the ground truth, by contrast. In the generating process, the current word is the output of the decoder in last time step, which is accessed to from a memory in PaddlePaddle.
Besides, we use Beam Search to generate sequences. Beam search uses breadth-first search to build its search tree. At each level of the tree, it generates all successors of the states at the current level, sorting them in increasing order of heuristic cost. However, it only stores a predetermined number of best states at each level (called the beam size).
Pretrained model¶
We trained the model on a cluster with 50 nodes, each node has two 6-core CPUs. We trained 16 passes in 5 days, where each pass takes 7 hours. The model_dir has 16 sub-folder, each of which contains the whole model parameters with 202MB size. And we find pass-00012 model has the highest BLEU 27.77 (see paper BLEU: a Method for Automatic Evaluation of Machine Translation). To download and extract this model, simply run the following commands in linux.
cd demo/seqToseq/data
./wmt14_model.sh
Generating Model in PaddlePaddle¶
We need to create a model config file before translating French sequence. Here is an example demo/seqToseq/translation/gen.conf, the first three lines import python function for defining network, and define the job_mode and attention_mode.
from seqToseq_net import *
is_generating = True
################## Data Definiation #####################
gen_conf = seq_to_seq_data(data_dir = "./data/pre-wmt14",
is_generating = is_generating,
gen_result = "./translation/gen_result")
############## Algorithm Configuration ##################
settings(
learning_method = AdamOptimizer(),
batch_size = 1,
learning_rate = 0)
################# Network configure #####################
gru_encoder_decoder(gen_conf, is_generating)
- Data Definiation: We defines an SeqToSeq gen data in our example. It returns gen_conf as the configuration, following is its input arguments:
- data_dir: directory of gen data
- is_generating: whether this config is used for generating, here is false
- gen_result: file to store the generation result
- Algorithm Configuration: We use SGD traing algorithm in generation, and specify batch_size as 1 (each time generate one sequence), and learning rate as 0.
- Network Architecture: Essentially the same as the training model.
Generating Command and Result¶
After writing the model config, we can do text translation from French to English by running the command:
cd demo/seqToseq/translation
./gen.sh
The gen.sh is shown as follows, unlike training, there are some different arguments to specify:
paddle train \
--job=test \
--config='translation/gen.conf' \
--save_dir='data/wmt14_model' \
--use_gpu=true \
--num_passes=13 \
--test_pass=12 \
--trainer_count=1 \
2>&1 | tee 'translation/gen.log'
- job: set job mode to test
- num_passes and test_pass: loading model parameters from test_pass to (num_passes - 1), here only loads
data/wmt14_model/pass-00012
You will see messages like this:
I0706 14:48:31.178915 31441 GradientMachine.cpp:143] Loading parameters from data/wmt14_model/pass-00012
I0706 14:48:40.012039 31441 Tester.cpp:125] Batch=100 samples=100 AvgCost=0
I0706 14:48:48.898632 31441 Tester.cpp:125] Batch=200 samples=200 AvgCost=0
...
And the generating result in demo/seqToseq/translation/gen_result likes:
0
0 -11.1314 The <unk> <unk> about the width of the seats while large controls are at stake <e>
1 -11.1519 The <unk> <unk> on the width of the seats while large controls are at stake <e>
2 -11.5988 The <unk> <unk> about the width of the seats while large controls are at stake . <e>
1
0 -24.4149 The dispute is between the major aircraft manufacturers about the width of the tourist seats on the <unk> flights , paving the way for a <unk> confrontation during the month of the Dubai <unk> . <e>
1 -26.9524 The dispute is between the major aircraft manufacturers about the width of the tourist seats on the <unk> flights , paving the way for a <unk> confrontation during the month of Dubai ' s <unk> . <e>
2 -27.9574 The dispute is between the major aircraft manufacturers about the width of the tourist seats on the <unk> flights , paving the way for a <unk> confrontation during the month of Dubai ' s Dubai <unk> . <e>
...
- This is the beam search result, where beam size is 3
- ‘0’ in 1st-line and ‘1’ in 6th-line mean the sequence-id in gen data
- Other six lines list the beam search results
- The 2nd-column is the score of beam search (from large to small)
- The 3rd-colunm is the generating English sequence
- There is 2 special tokens:
<e>: the end of a sequence<unk>: a word not included in dictionary
Bleu Evalutaion¶
Human evaluations of machine translation are extensive but expensive. Paper BLEU: a Method for Automatic Evaluation of Machine Translation presents a method as an automated understudy to skilled human judges which substitutes for them when there is need for quick or frequent evaluations. Moses is a statistical machine translation system, and we use multi-bleu.perl of it to do Bleu Evalution. To download this script, simply run the following command:
cd demo/seqToseq/translation
./moses_bleu.sh
Since the standard translation is alrealy downloaded as data/wmt14/gen/ntst14.trg, we can do Bleu Evalution by running the command:
cd demo/seqToseq/translation
./eval_bleu.sh FILE BEAMSIZE
- FILE: the generation result file
- BEAMSIZE: expand width in beam search