# Design Doc: Large Model
## Abstract
We propose an approach to support the large parameter.
For embedding layer, the parameter may very large and could
not be stored in one trainer's memory. In this approach, a Trainer would
prefetch a sliced parameter from different Parameter Server instances
according to the input `Ids`, and then run forward, backward and send
the gradient to Parameter Server to execute the optimize program.
## Design
**NOTE**: this approach is a feature of Fluid distributed trianing, maybe you want
to know [Distributed Architecture](./distributed_architecture.md) and
[Parameter Server](./parameter_server.md) before reading the following content.
Fluid large model distributed training use
[Distributed Transpiler](./parameter_server.md#distributed-transpiler) to split
a large parameter into multiple parameters which stored on Parameter Server, and
the Trainer would prefetch them by `RPC` interface.
### Split Large Parameter
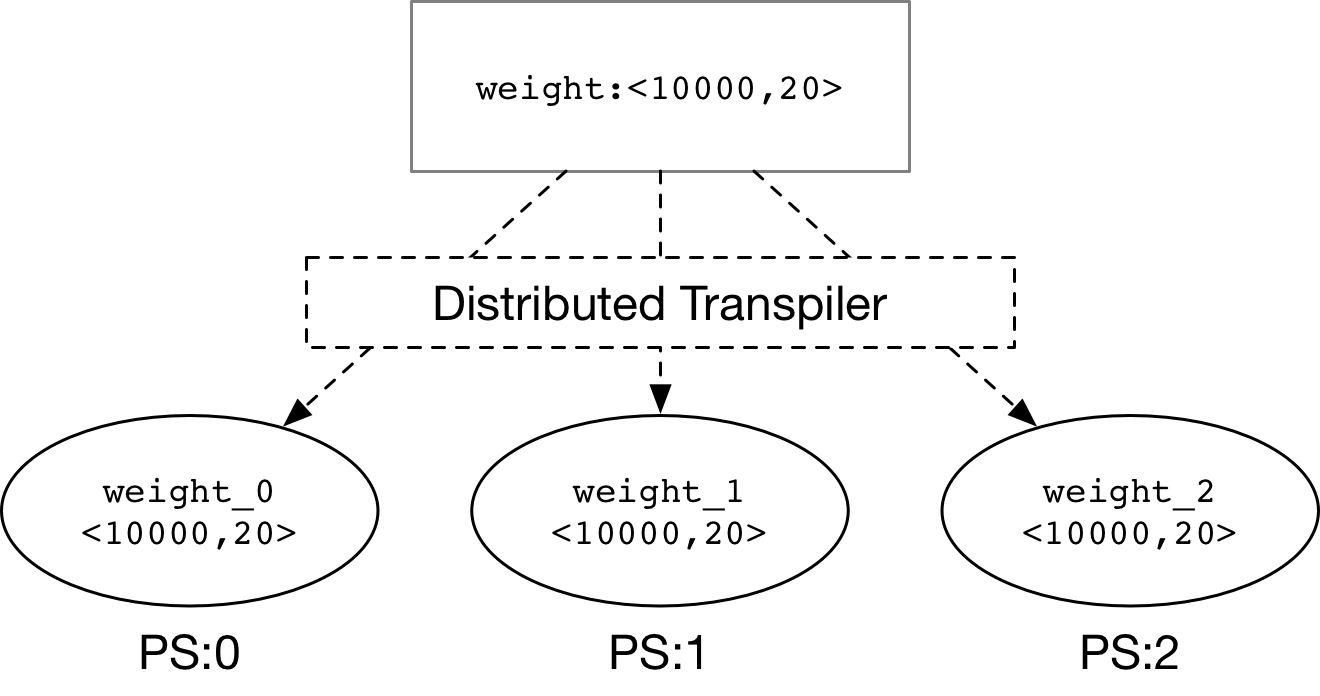 **Distributed Transpiler** would split the large parameter
(weight) into some sliced parameters (weight_0, weight_1, weight_2) as the
figure above.
### Prefetch Parameters from Parameter Servers
**Distributed Transpiler** would split the large parameter
(weight) into some sliced parameters (weight_0, weight_1, weight_2) as the
figure above.
### Prefetch Parameters from Parameter Servers
 - `PrefetchRpc` operator would send the rows index the multiple Parameter Servers,
and then receive the SelctedRows.
- The different with normal Fluid distributed training, we only prefetch the rows
## TODO
- Async Update
To avoid slow-node, Async update is important for distributed training,
we need an design doc and implement it in future.
- `PrefetchRpc` operator would send the rows index the multiple Parameter Servers,
and then receive the SelctedRows.
- The different with normal Fluid distributed training, we only prefetch the rows
## TODO
- Async Update
To avoid slow-node, Async update is important for distributed training,
we need an design doc and implement it in future.