Regression MovieLens Ratting¶
Here we demonstrate a Cosine Similarity Regression job in movie lens dataset. This demo will show how paddle does (word) embedding job, handles the similarity regression, the character-level convolutional networks for text, and how does paddle handle multiple types of inputs. Note that the model structure is not fine-tuned and just a demo to show how paddle works.
YOU ARE WELCOME TO BUILD A BETTER DEMO BY USING PADDLEPADDLE, AND LET US KNOW TO MAKE THIS DEMO BETTER.
Data Preparation¶
Download and extract dataset¶
We use movielens 1m dataset here. To download and unzip the dataset, simply run the following commands.
cd demo/recommendation/data
./ml_data.sh
And the directory structure of demo/recommendation/data/ml-1m is:
+--ml-1m
+--- movies.dat # movie features
+--- ratings.dat # ratings
+--- users.dat # user features
+--- README # dataset description
Field config file¶
Field config file is used to specific the fields dataset and file format, i.e, specific WHAT type it is in each feature file.
The field config file of ml-1m shows in demo/recommendation/data/config.json.
It specifics the field types and file names: 1) there are four types of field for user file: id, gender, age and occupation;
2) the filename is “users.dat”, and the delimiter of file is ”::”.
{
"user": {
"file": {
"name": "users.dat",
"delimiter": "::"
},
"fields": ["id", "gender", "age", "occupation"]
},
"movie": {
"file": {
"name": "movies.dat",
"delimiter": "::"
},
"fields": ["id", "title", "genres"]
}
}
Preprocess Data¶
You need to install python 3rd party libraries. IT IS HIGHLY RECOMMEND TO USE VIRTUALENV MAKE A CLEAN PYTHON ENVIRONMENT.
pip install -r requirements.txt
The general command for preprocessing the dataset is:
cd demo/recommendation
./preprocess.sh
And the detail steps are introduced as follows.
Extract Movie/User features to python object¶
There are many features in movie or user in movielens 1m dataset. Each line of rating file just provides a Movie/User id to refer each movie or user. We process the movie/user feature file first, and pickle the feature (Meta) object as a file.
Meta config file¶
Meta config file is used to specific HOW to parse each field in dataset. It could be translated from field config file, or written by hand. Its file format could be either json or yaml syntax file. Parser will automatically choose the file format by extension name.
To convert Field config file to meta config file, just run:
cd demo/recommendation/data
python config_generator.py config.json > meta_config.json
The meta config file shows below:
{
"meta": {
"movie": {
"fields": [
{
"type": "id",
"pos": 0
},
{
"regex": {
"pattern": "^(.*)\\((\\d+)\\)$",
"group_id": 1,
"strip": true
},
"type": {
"seq_type": "sequence",
"name": "embedding"
},
"dict": {
"type": "char_based"
},
"name": "title",
"pos": 1
},
{
"type": "one_hot_dense",
"dict": {
"delimiter": "|",
"type": "split"
},
"name": "genres",
"pos": 2
}
],
"file": {
"delimiter": "::",
"type": "split",
"name": "movies.dat"
}
},
"user": {
"fields": [
{
"type": "id",
"pos": 0
},
{
"type": "embedding",
"dict": {
"type": "char_based"
},
"name": "gender",
"pos": 1
},
{
"type": "embedding",
"dict": {
"sort": true,
"type": "whole_content"
},
"name": "age",
"pos": 2
},
{
"type": "embedding",
"dict": {
"sort": "true",
"type": "whole_content"
},
"name": "occupation",
"pos": 3
}
],
"file": {
"delimiter": "::",
"type": "split",
"name": "users.dat"
}
}
}
}
There are two kinds of features in meta: movie and user.
- in movie file, whose name is movies.dat
we just split each line by ”::”
pos 0 is id.
- pos 1 feature:
- name is title.
- it uses regex to parse this feature.
- it is a char based word embedding feature.
- it is a sequence.
- pos 2 feature:
- name is genres.
- type is one hot dense vector.
- dictionary is auto generated by parsing, each key is split by ‘|’
- in user file, whose name is users.dat
we just split each line by ”::”
pos 0 is id.
- pos 1 feature:
- name is gender
- just simple char based embedding.
- pos 2 feature:
- name is age
- just whole word embedding.
- embedding id will be sort by word.
- pos 3 feature:
- name is occupation.
- just simple whole word embedding.
Meta file¶
After having meta config file, we can generate Meta file, a python pickle object which stores movie/user information. The following commands could be run to generate it.
python meta_generator.py ml-1m meta.bin --config=meta_config.json
And the structure of the meta file meta.bin is:
+--+ movie
| +--+ __meta__
| | +--+ raw_meta # each feature meta config. list
| | | +
| | | | # ID Field, we use id as key
| | | +--+ {'count': 3883, 'max': 3952, 'is_key': True, 'type': 'id', 'min': 1}
| | | |
| | | | # Titile field, the dictionary list of embedding.
| | | +--+ {'dict': [ ... ], 'type': 'embedding', 'name': 'title', 'seq': 'sequence'}
| | | |
| | | | # Genres field, the genres dictionary
| | | +--+ {'dict': [ ... ], 'type': 'one_hot_dense', 'name': 'genres'}
| | |
| | +--+ feature_map [1, 2] # a list for raw_meta index for feature field.
| | # it means there are 2 features for each key.
| | # * 0 offset of feature is raw_meta[1], Title.
| | # * 1 offset of feature is raw_meta[2], Genres.
| |
| +--+ 1 # movie 1 features
| | +
| | +---+ [[...], [...]] # title ids, genres dense vector
| |
| +--+ 2
| |
| +--+ ...
|
+--- user
+--+ __meta__
| +
| +--+ raw_meta
| | +
| | +--+ id field as user
| | |
| | +--+ {'dict': ['F', 'M'], 'type': 'embedding', 'name': 'gender', 'seq': 'no_sequence'}
| | |
| | +--+ {'dict': ['1', '18', '25', '35', '45', '50', '56'], 'type': 'embedding', 'name': 'age', 'seq': 'no_sequence'}
| | |
| | +--+ {'dict': [...], 'type': 'embedding', 'name': 'occupation', 'seq': 'no_sequence'}
| |
| +--+ feature_map [1, 2, 3]
|
+--+ 1 # user 1 features
|
+--+ 2
+--+ ...
Split Training/Testing files¶
We split ml-1m/ratings.dat into a training and testing file. The way to split file is for each user, we split the
rating by two parts. So each user in testing file will have some rating information in training file.
Use separate.py to separate the training and testing file.
python split.py ml-1m/ratings.dat --delimiter="::" --test_ratio=0.1
Then two files will be generated: ml-1m/ratings.dat.train and ml-1m/rating.data.test.
Move them to workspace data, shuffle the train file, and prepare the file list for paddle train.
shuf ml-1m/ratings.dat.train > ratings.dat.train
cp ml-1m/ratings.dat.test .
echo "./data/ratings.dat.train" > train.list
echo "./data/ratings.dat.test" > test.list
Neural Network Configuration¶
Trainer Config File¶
The network structure shows below.
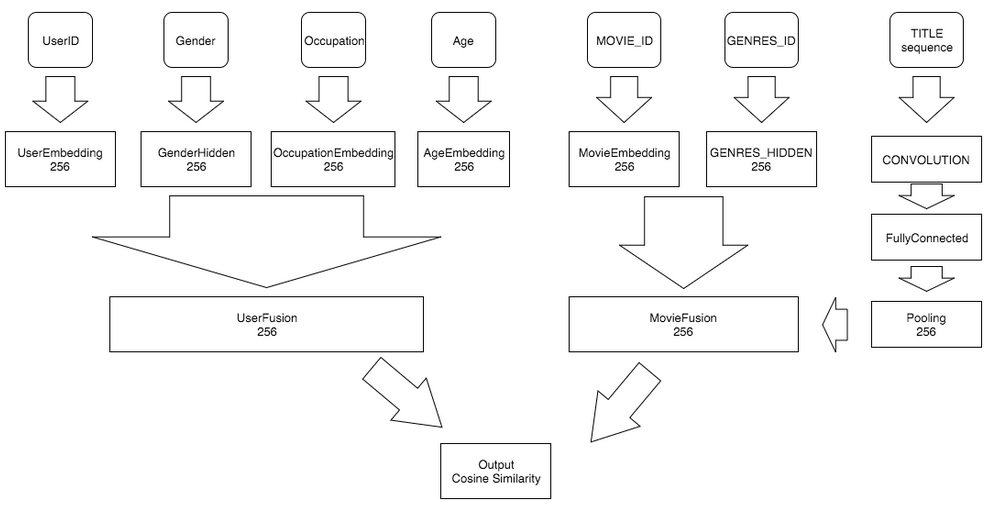
The demo’s neural network config file “trainer_config.py” show as below.
from paddle.trainer_config_helpers import *
try:
import cPickle as pickle
except ImportError:
import pickle
is_predict = get_config_arg('is_predict', bool, False)
META_FILE = 'data/meta.bin'
with open(META_FILE, 'rb') as f:
# load meta file
meta = pickle.load(f)
settings(batch_size=1600, learning_rate=1e-3,
learning_method=RMSPropOptimizer())
def construct_feature(name):
"""
Construct movie/user features.
This method read from meta data. Then convert feature to neural network due
to feature type. The map relation as follow.
* id: embedding => fc
* embedding:
is_sequence: embedding => context_projection => fc => pool
not sequence: embedding => fc
* one_hot_dense: fc => fc
Then gather all features vector, and use a fc layer to combined them as
return.
:param name: 'movie' or 'user'
:type name: basestring
:return: combined feature output
:rtype: LayerOutput
"""
__meta__ = meta[name]['__meta__']['raw_meta']
fusion = []
for each_meta in __meta__:
type_name = each_meta['type']
slot_name = each_meta.get('name', '%s_id' % name)
if type_name == 'id':
slot_dim = each_meta['max']
embedding = embedding_layer(input=data_layer(slot_name,
size=slot_dim),
size=256)
fusion.append(fc_layer(input=embedding,
size=256))
elif type_name == 'embedding':
is_seq = each_meta['seq'] == 'sequence'
slot_dim = len(each_meta['dict'])
din = data_layer(slot_name, slot_dim)
embedding = embedding_layer(input=din, size=256)
if is_seq:
fusion.append(
text_conv_pool(input=embedding, context_len=5,
hidden_size=256))
else:
fusion.append(fc_layer(input=embedding,
size=256))
elif type_name == 'one_hot_dense':
slot_dim = len(each_meta['dict'])
hidden = fc_layer(input=data_layer(slot_name, slot_dim),
size=256)
fusion.append(fc_layer(input=hidden,
size=256))
return fc_layer(name="%s_fusion" % name, input=fusion, size=256)
movie_feature = construct_feature("movie")
user_feature = construct_feature("user")
similarity = cos_sim(a=movie_feature, b=user_feature)
if not is_predict:
outputs(regression_cost(input=similarity,
label=data_layer('rating', size=1)))
define_py_data_sources2('data/train.list', 'data/test.list', module='dataprovider',
obj='process', args={'meta': meta})
else:
outputs(similarity)
In this trainer_config.py, we just map each feature type to
a feature vector, following shows how to map each feature to a vector shows below.
id: Just simple embedding, and then add to fully connected layer.embedding:- if is_sequence, get the embedding and do a text convolutional operation, get the average pooling result.
- if not sequence, get the embedding and add to fully connected layer.
one_host_dense:- just two fully connected layer.
Then we combine each features of movie into one movie feature by a
fc_layer with multiple inputs, and do the same thing to user features,
get one user feature. Then we calculate the cosine similarity of these two
features.
In these network, we use several api in trainer_config_helpers. There are
- Data Layer, data_layer
- Fully Connected Layer, fc_layer
- Embedding Layer, embedding_layer
- Context Projection Layer, context_projection
- Pooling Layer, pooling_layer
- Cosine Similarity Layer, cos_sim
- Text Convolution Pooling Layer, text_conv_pool
- Declare Python Data Sources, define_py_data_sources2
Data Provider¶
from paddle.trainer.PyDataProvider2 import *
import common_utils # parse
def hook(settings, meta, **kwargs):
"""
Init hook is invoked before process data. It will set obj.slots and store
data meta.
:param obj: global object. It will passed to process routine.
:type obj: object
:param meta: the meta file object, which passed from trainer_config. Meta
file record movie/user features.
:param kwargs: unused other arguments.
"""
del kwargs # unused kwargs
# Header define slots that used for paddle.
# first part is movie features.
# second part is user features.
# final part is rating score.
# header is a list of [USE_SEQ_OR_NOT?, SlotType]
headers = list(common_utils.meta_to_header(meta, 'movie'))
headers.extend(list(common_utils.meta_to_header(meta, 'user')))
headers.append(dense_vector(1)) # Score
# slot types.
settings.input_types = headers
settings.meta = meta
@provider(init_hook=hook, cache=CacheType.CACHE_PASS_IN_MEM)
def process(settings, filename):
with open(filename, 'r') as f:
for line in f:
# Get a rating from file.
user_id, movie_id, score = map(int, line.split('::')[:-1])
# Scale score to [-5, +5]
score = float(score) * 2 - 5.0
# Get movie/user features by movie_id, user_id
movie_meta = settings.meta['movie'][movie_id]
user_meta = settings.meta['user'][user_id]
outputs = [movie_id - 1]
# Then add movie features
for each_meta in movie_meta:
outputs.append(each_meta)
# Then add user id.
outputs.append(user_id - 1)
# Then add user features.
for each_meta in user_meta:
outputs.append(each_meta)
# Finally, add score
outputs.append([score])
# Return data to paddle
yield outputs
The data provider just read the meta.bin and rating file, yield each sample for training.
In this dataprovider.py, we should set:
- obj.slots: The feature types and dimension.
- use_seq: Whether this
dataprovider.pyin sequence mode or not. - process: Return each sample of data to
paddle.
The data provider details document see there.
Train¶
After prepare data, config network, writting data provider, now we can run paddle training.
The run.sh is shown as follow:
paddle train \
--config=trainer_config.py \
--save_dir=./output \
--use_gpu=false \
--trainer_count=4\
--test_all_data_in_one_period=true \
--log_period=100 \
--dot_period=1 \
--num_passes=50 2>&1 | tee 'log.txt'
It just start a paddle training process, write the log to log.txt, then print it on screen.
Each command line argument in run.sh, please refer to the command line
arguments page. The short description of these arguments is shown as follow.
- config: Tell paddle which file is neural network configuration.
- save_dir: Tell paddle save model into ‘./output’
- use_gpu: Use gpu or not. Default is false.
- trainer_count: The compute thread in one machine.
- test_all_data_in_one_period: Test All Data during one test period. Otherwise,
will test a
batch_sizedata in one test period. - log_period: Print log after train
log_periodbatches. - dot_period: Print a
.after traindot_periodbatches. - num_passes: Train at most
num_passes.
If training process starts successfully, the output likes follow:
I0601 08:07:22.832059 10549 TrainerInternal.cpp:157] Batch=100 samples=160000 AvgCost=4.13494 CurrentCost=4.13494 Eval: CurrentEval:
I0601 08:07:50.672627 10549 TrainerInternal.cpp:157] Batch=200 samples=320000 AvgCost=3.80957 CurrentCost=3.48421 Eval: CurrentEval:
I0601 08:08:18.877369 10549 TrainerInternal.cpp:157] Batch=300 samples=480000 AvgCost=3.68145 CurrentCost=3.42519 Eval: CurrentEval:
I0601 08:08:46.863963 10549 TrainerInternal.cpp:157] Batch=400 samples=640000 AvgCost=3.6007 CurrentCost=3.35847 Eval: CurrentEval:
I0601 08:09:15.413025 10549 TrainerInternal.cpp:157] Batch=500 samples=800000 AvgCost=3.54811 CurrentCost=3.33773 Eval: CurrentEval:
I0601 08:09:36.058670 10549 TrainerInternal.cpp:181] Pass=0 Batch=565 samples=902826 AvgCost=3.52368 Eval:
I0601 08:09:46.215489 10549 Tester.cpp:101] Test samples=97383 cost=3.32155 Eval:
I0601 08:09:46.215966 10549 GradientMachine.cpp:132] Saving parameters to ./output/model/pass-00000
I0601 08:09:46.233397 10549 ParamUtil.cpp:99] save dir ./output/model/pass-00000
I0601 08:09:46.233438 10549 Util.cpp:209] copy trainer_config.py to ./output/model/pass-00000
I0601 08:09:46.233541 10549 ParamUtil.cpp:147] fileName trainer_config.py
The model is saved in output/ directory. You can use Ctrl-C to stop training whenever you want.
Evaluate and Predict¶
After training several passes, you can evaluate them and get the best pass. Just run
./evaluate.sh
You will see messages like this:
Best pass is 00009, error is 3.06949, which means predict get error as 0.875998002281
evaluating from pass output/pass-00009
Then, you can predict what any user will rate a movie. Just run
python prediction.py 'output/pass-00009/'
Predictor will read user input, and predict scores. It has a command-line user interface as follows:
Input movie_id: 9
Input user_id: 4
Prediction Score is 2.56
Input movie_id: 8
Input user_id: 2
Prediction Score is 3.13