# Benchmark
Machine:
- Server: Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz, 2 Sockets, 20 Cores per socket
- Laptop: TBD
System: CentOS release 6.3 (Final), Docker 1.12.1.
PaddlePaddle: (TODO: will rerun after 0.11.0)
- paddlepaddle/paddle:latest (for MKLML and MKL-DNN)
- MKL-DNN tag v0.11
- MKLML 2018.0.1.20171007
- paddlepaddle/paddle:latest-openblas (for OpenBLAS)
- OpenBLAS v0.2.20
On each machine, we will test and compare the performance of training on single node using MKL-DNN / MKLML / OpenBLAS respectively.
## Benchmark Model
### Server
Test on batch size 64, 128, 256 on Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
Input image size - 3 * 224 * 224, Time: images/second
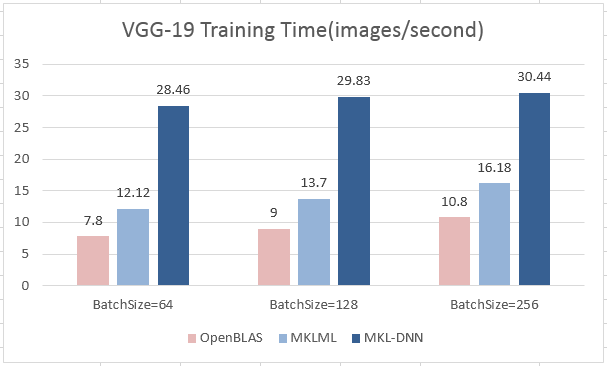
- VGG-19
| BatchSize | 64 | 128 | 256 |
|--------------|-------| -----| --------|
| OpenBLAS | 7.80 | 9.00 | 10.80 |
| MKLML | 12.12 | 13.70 | 16.18 |
| MKL-DNN | 28.46 | 29.83 | 30.44 |
 - ResNet-50
| BatchSize | 64 | 128 | 256 |
|--------------|-------| ------| -------|
| OpenBLAS | 25.22 | 25.68 | 27.12 |
| MKLML | 32.52 | 31.89 | 33.12 |
| MKL-DNN | 81.69 | 82.35 | 84.08 |
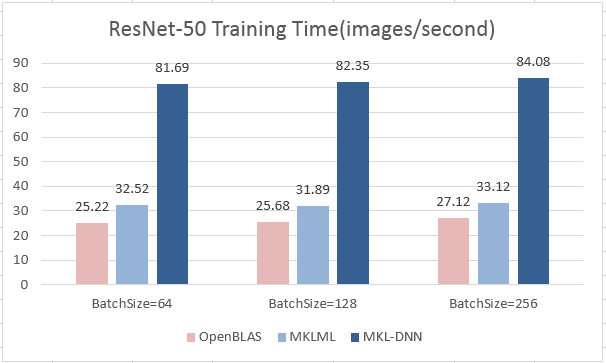
- ResNet-50
| BatchSize | 64 | 128 | 256 |
|--------------|-------| ------| -------|
| OpenBLAS | 25.22 | 25.68 | 27.12 |
| MKLML | 32.52 | 31.89 | 33.12 |
| MKL-DNN | 81.69 | 82.35 | 84.08 |
 - GoogLeNet
| BatchSize | 64 | 128 | 256 |
|--------------|-------| ------| -------|
| OpenBLAS | 89.52 | 96.97 | 108.25 |
| MKLML | 128.46| 137.89| 158.63 |
| MKL-DNN | 250.46| 264.83| 269.50 |
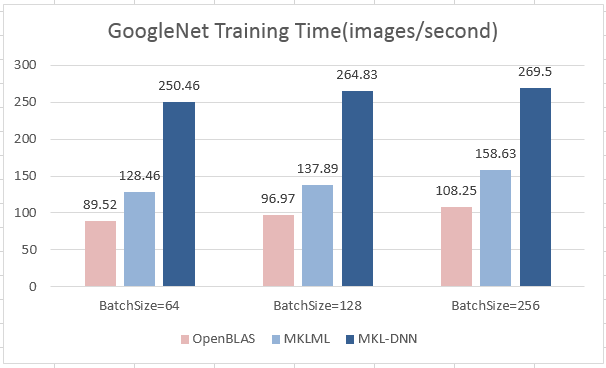
- GoogLeNet
| BatchSize | 64 | 128 | 256 |
|--------------|-------| ------| -------|
| OpenBLAS | 89.52 | 96.97 | 108.25 |
| MKLML | 128.46| 137.89| 158.63 |
| MKL-DNN | 250.46| 264.83| 269.50 |
 ### Laptop
TBD
### Laptop
TBD