Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
BaiXuePrincess
Paddle
提交
edb4e29a
P
Paddle
项目概览
BaiXuePrincess
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
edb4e29a
编写于
3月 21, 2018
作者:
W
wanghaoshuang
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/Paddle
into average_model
上级
ad63722e
873cb9bc
变更
12
显示空白变更内容
内联
并排
Showing
12 changed file
with
758 addition
and
242 deletion
+758
-242
doc/fluid/design/concurrent/images/select_op_workflow.png
doc/fluid/design/concurrent/images/select_op_workflow.png
+0
-0
doc/fluid/design/concurrent/select_op.md
doc/fluid/design/concurrent/select_op.md
+265
-0
doc/v2/getstarted/index_en.rst
doc/v2/getstarted/index_en.rst
+11
-0
paddle/fluid/framework/executor.cc
paddle/fluid/framework/executor.cc
+11
-17
paddle/fluid/framework/executor.h
paddle/fluid/framework/executor.h
+12
-3
paddle/fluid/operators/elementwise_add_op.cu
paddle/fluid/operators/elementwise_add_op.cu
+11
-10
paddle/fluid/platform/float16.h
paddle/fluid/platform/float16.h
+30
-32
python/paddle/fluid/executor.py
python/paddle/fluid/executor.py
+93
-72
python/paddle/fluid/layers/nn.py
python/paddle/fluid/layers/nn.py
+18
-3
python/paddle/fluid/optimizer.py
python/paddle/fluid/optimizer.py
+118
-0
python/paddle/fluid/tests/unittests/test_elementwise_add_op.py
...n/paddle/fluid/tests/unittests/test_elementwise_add_op.py
+189
-104
python/paddle/fluid/tests/unittests/test_executor_and_mul.py
python/paddle/fluid/tests/unittests/test_executor_and_mul.py
+0
-1
未找到文件。
doc/fluid/design/concurrent/images/select_op_workflow.png
0 → 100644
浏览文件 @
edb4e29a
99.1 KB
doc/fluid/design/concurrent/select_op.md
0 → 100644
浏览文件 @
edb4e29a
# select_op Design
## Introduction
In golang, the
[
**select**
](
https://golang.org/ref/spec#Select_statements
)
statement lets a goroutine wait on multiple communication operations at the
same time. The
**select**
blocks until one of its cases can run, then
executes the case. If multiple cases are ready to run, then one case is
choosen at random to be executed.
With the introduction of CSP for Paddle, we mimic this behavior by
creating a
***select_op**
*
.
## How to use it
The
**select_op**
is available as a c++ operator. However most users
will prefer to use the much simplier Python API.
-
**fluid.Select()**
: Creates a select operator and adds it to the current
block within the main program. Also creates a sub block and adds it to the
main program. This sub block is used to hold all variables and operators
used by the case statements.
Within the select block, users can add cases by
calling
**select.case**
or
**select.default**
method.
-
**fluid.Select.case(channel_action, channel, result_variable)**
: Represents
a fluid channel send/recv case. This method creates a SelectCase block
guard and adds it to the Select block. The arguments into this method tells
the select which channel operation to listen to.
-
**fluid.Select.default()**
: Represents the fluid default case. This default
case is executed if none of the channel send/recv cases are available to
execute.
**Example:**
```
ch1 = fluid.make_channel(dtype=core.VarDesc.VarType.LOD_TENSOR)
quit_ch = fluid.make_channel(dtype=core.VarDesc.VarType.LOD_TENSOR)
x = fill_constant(shape=[1], dtype=core.VarDesc.VarType.INT32, value=0)
y = fill_constant(shape=[1], dtype=core.VarDesc.VarType.INT32, value=1)
while_cond = fill_constant(shape=[1], dtype=core.VarDesc.VarType.BOOL, value=True)
while_op = While(cond=while_cond)
with while_op.block():
with fluid.Select() as select:
with select.case(fluid.channel_send, channel, x):
# Send x, then perform Fibonacci calculation on x and y
x_tmp = fill_constant(shape=[1], dtype=core.VarDesc.VarType.INT32, value=0)
assign(input=x, output=x_tmp)
assign(input=y, output=x)
assign(elementwise_add(x=x_tmp, y=y), output=y)
with select.case(fluid.channel_recv, quit_channel, result2):
# Exit out of While loop
while_false = fill_constant(shape=[1], dtype=core.VarDesc.VarType.BOOL, value=False)
helper = layer_helper.LayerHelper('assign')
helper.append_op(
type='assign',
inputs={'X': [while_false]},
outputs={'Out': [while_cond]})
```
## How it Works
### Program Description
```
blocks {
idx: 0
...
// Create "case_to_execute" variable
ops {
outputs {
parameter: "Out"
arguments: "fill_constant_110.tmp_0"
}
type: "fill_constant"
attrs {
name: "force_cpu"
type: BOOLEAN
b: false
}
attrs {
name: "value"
type: FLOAT
f: -1.0
}
attrs {
name: "shape"
type: INTS
ints: 1
}
attrs {
name: "dtype"
type: INT
i: 2
}
}
// Create "select" operator.
// inputs:
// X: All input variables used by operators within the select block
// case_to_execute: Variable filled in by select_op when it determines
// which case to execute.
//
// outputs:
// Out: All output variables referenced by operators within select block.
//
// attrs:
// sub_block: The block id containing the select "cases"
// cases: Serialized list of all cases in the select op.
// Each case is serialized as: '<index>,<type>,<channel>,<value>'
// where type is 0 for default, 1 for send, and 2 for receive.
// No channel and values are needed for default cases.
ops {
inputs {
parameter: "X"
arguments: "fill_constant_103.tmp_0"
arguments: "fill_constant_104.tmp_0"
}
inputs {
parameter: "case_to_execute"
arguments: "fill_constant_110.tmp_0"
}
outputs {
parameter: "Out"
arguments: "fill_constant_110.tmp_0"
}
type: "select"
attrs {
name: "sub_block"
type: BLOCK
block_idx: 1
}
attrs {
name: "cases"
type: STRINGS
strings: "0,1,channel_101,fill_constant_109.tmp_0"
strings: "1,2,channel_102,fill_constant_108.tmp_0"
}
}
...
}
```
The python select API will add the
**select_op**
to the current block. In addition, it will
iterate through all it's case statements and add any input variables required by case statements
into
**X**
. It will also create a temp variable called
**case_to_execute**
. This variable is
filled in by the select_op after it has completed processing the case statements.
If there are no available cases to execute (ie: all cases are blocked on channel operations, and
there is no default statement), then the select_op will block the current thread. The thread will
unblock once there is a channel operation affecting one of the case statements, at which point, the
**select_op**
will set the
**case_to_execute**
variable to the index of the case to execute.
Finally the select_op will call executor.run on the
**sub_block**
.
```
blocks {
idx: 1
parent_idx: 0
...
// Fill a tensor with the case index (ie: 0,1,2,3,ect.)
ops {
outputs {
parameter: "Out"
arguments: "fill_constant_111.tmp_0"
}
type: "fill_constant"
attrs {
name: "force_cpu"
type: BOOLEAN
b: false
}
attrs {
name: "value"
type: FLOAT
f: 0.0
}
attrs {
name: "shape"
type: INTS
ints: 1
}
attrs {
name: "dtype"
type: INT
i: 2
}
}
// Create an "equal" operator to compare the case index with the "case_to_execute"
// tensor (which was filled in by the select op).
ops {
inputs {
parameter: "X"
arguments: "fill_constant_111.tmp_0" // case 0
}
inputs {
parameter: "Y"
arguments: "fill_constant_110.tmp_0" // case_to_execute
}
outputs {
parameter: "Out"
arguments: "equal_0.tmp_0"
}
type: "equal"
attrs {
name: "axis"
type: INT
i: -1
}
}
// Use the output of the "equal" operator as a condition for the "conditional_block".
// If the condition evaluates to true, then execute the "sub_block" (which represents
// the select case's body)
ops {
inputs {
parameter: "Params"
}
inputs {
parameter: "X"
arguments: "equal_0.tmp_0"
}
outputs {
parameter: "Out"
}
outputs {
parameter: "Scope"
arguments: "_generated_var_0"
}
type: "conditional_block"
attrs {
name: "is_scalar_condition"
type: BOOLEAN
b: true
}
attrs {
name: "sub_block"
type: BLOCK
block_idx: 4
}
}
...
// Repeat the above operators for each case statements inside the select body
}
```
Cases are represented by a
**conditional_block operator**
, whose's condition is set as the output of
equal(
**case_to_execute**
,
**case_index**
). Since each case index is unique in this sub-block,
only one case will be executed.
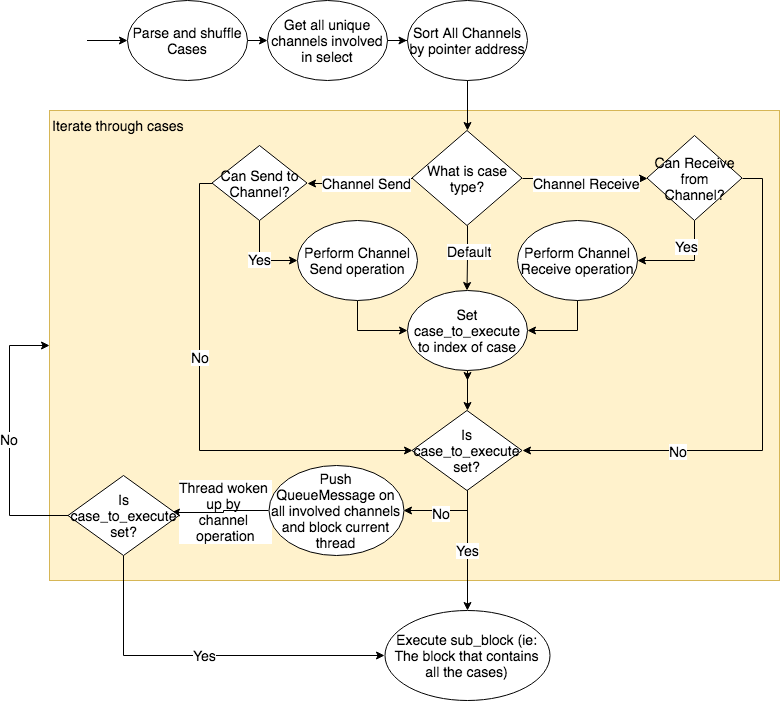
### select_op flow
<p
align=
"center"
>
<img
src=
"./images/select_op_workflow.png"
/><br/>
</p>
The select algorithm is inspired by golang's select routine. Please refer to
http://www.tapirgames.com/blog/golang-concurrent-select-implementation for more information.
## Backward Pass
TODO
doc/v2/getstarted/index_en.rst
浏览文件 @
edb4e29a
GET STARTED
GET STARTED
============
============
If you want to quickly know how to use PaddlePaddle, please refer to the following guide:
.. toctree::
.. toctree::
:maxdepth: 1
:maxdepth: 1
quickstart_en.rst
quickstart_en.rst
While using PaddlePaddle to build applications, please understand some basic concepts.
Here is an example of linear regression. It introduces workflow of PaddlePaddle, including data format, model configuration and training, etc.
.. toctree::
:maxdepth: 1
concepts/use_concepts_en.rst
concepts/use_concepts_en.rst
paddle/fluid/framework/executor.cc
浏览文件 @
edb4e29a
...
@@ -14,12 +14,8 @@ limitations under the License. */
...
@@ -14,12 +14,8 @@ limitations under the License. */
#include "paddle/fluid/framework/executor.h"
#include "paddle/fluid/framework/executor.h"
#include <set>
#include "gflags/gflags.h"
#include "paddle/fluid/framework/channel.h"
#include "paddle/fluid/framework/channel.h"
#include "paddle/fluid/framework/feed_fetch_method.h"
#include "paddle/fluid/framework/feed_fetch_method.h"
#include "paddle/fluid/framework/feed_fetch_type.h"
#include "paddle/fluid/framework/lod_rank_table.h"
#include "paddle/fluid/framework/lod_rank_table.h"
#include "paddle/fluid/framework/lod_tensor_array.h"
#include "paddle/fluid/framework/lod_tensor_array.h"
#include "paddle/fluid/framework/op_registry.h"
#include "paddle/fluid/framework/op_registry.h"
...
@@ -40,14 +36,13 @@ namespace {
...
@@ -40,14 +36,13 @@ namespace {
int
kProgramId
=
-
1
;
int
kProgramId
=
-
1
;
}
// namespace
}
// namespace
struct
ExecutorPrepareContext
{
ExecutorPrepareContext
::
ExecutorPrepareContext
(
ExecutorPrepareContext
(
const
framework
::
ProgramDesc
&
prog
,
size_t
block_id
)
const
framework
::
ProgramDesc
&
prog
,
size_t
block_id
)
:
prog_
(
prog
),
block_id_
(
block_id
)
{}
:
prog_
(
prog
),
block_id_
(
block_id
)
{}
const
framework
::
ProgramDesc
&
prog_
;
ExecutorPrepareContext
::~
ExecutorPrepareContext
()
{
size_t
block_id_
;
VLOG
(
5
)
<<
"destroy ExecutorPrepareContext"
;
std
::
vector
<
std
::
unique_ptr
<
OperatorBase
>>
ops_
;
}
};
Executor
::
Executor
(
const
platform
::
Place
&
place
)
:
place_
(
place
)
{}
Executor
::
Executor
(
const
platform
::
Place
&
place
)
:
place_
(
place
)
{}
...
@@ -101,9 +96,8 @@ static void CheckTensorNANOrInf(const std::string& name,
...
@@ -101,9 +96,8 @@ static void CheckTensorNANOrInf(const std::string& name,
void
Executor
::
Run
(
const
ProgramDesc
&
pdesc
,
Scope
*
scope
,
int
block_id
,
void
Executor
::
Run
(
const
ProgramDesc
&
pdesc
,
Scope
*
scope
,
int
block_id
,
bool
create_local_scope
,
bool
create_vars
)
{
bool
create_local_scope
,
bool
create_vars
)
{
platform
::
RecordBlock
b
(
block_id
);
platform
::
RecordBlock
b
(
block_id
);
auto
*
ctx
=
Prepare
(
pdesc
,
block_id
);
auto
ctx
=
Prepare
(
pdesc
,
block_id
);
RunPreparedContext
(
ctx
,
scope
,
create_local_scope
,
create_vars
);
RunPreparedContext
(
ctx
.
get
(),
scope
,
create_local_scope
,
create_vars
);
delete
ctx
;
}
}
// Check whether the block already has feed operators and feed_holder.
// Check whether the block already has feed operators and feed_holder.
...
@@ -274,15 +268,15 @@ void Executor::Run(const ProgramDesc& program, Scope* scope,
...
@@ -274,15 +268,15 @@ void Executor::Run(const ProgramDesc& program, Scope* scope,
}
}
}
}
ExecutorPrepareContext
*
Executor
::
Prepare
(
const
ProgramDesc
&
program
,
std
::
unique_ptr
<
ExecutorPrepareContext
>
Executor
::
Prepare
(
int
block_id
)
{
const
ProgramDesc
&
program
,
int
block_id
)
{
auto
*
ctx
=
new
ExecutorPrepareContext
(
program
,
block_id
);
auto
*
ctx
=
new
ExecutorPrepareContext
(
program
,
block_id
);
PADDLE_ENFORCE_LT
(
static_cast
<
size_t
>
(
block_id
),
program
.
Size
());
PADDLE_ENFORCE_LT
(
static_cast
<
size_t
>
(
block_id
),
program
.
Size
());
auto
&
block
=
program
.
Block
(
block_id
);
auto
&
block
=
program
.
Block
(
block_id
);
for
(
auto
&
op_desc
:
block
.
AllOps
())
{
for
(
auto
&
op_desc
:
block
.
AllOps
())
{
ctx
->
ops_
.
push_back
(
OpRegistry
::
CreateOp
(
*
op_desc
));
ctx
->
ops_
.
push_back
(
OpRegistry
::
CreateOp
(
*
op_desc
));
}
}
return
ctx
;
return
std
::
unique_ptr
<
ExecutorPrepareContext
>
(
ctx
)
;
}
}
void
Executor
::
RunPreparedContext
(
ExecutorPrepareContext
*
ctx
,
Scope
*
scope
,
void
Executor
::
RunPreparedContext
(
ExecutorPrepareContext
*
ctx
,
Scope
*
scope
,
...
...
paddle/fluid/framework/executor.h
浏览文件 @
edb4e29a
...
@@ -22,7 +22,16 @@ limitations under the License. */
...
@@ -22,7 +22,16 @@ limitations under the License. */
namespace
paddle
{
namespace
paddle
{
namespace
framework
{
namespace
framework
{
struct
ExecutorPrepareContext
;
struct
ExecutorPrepareContext
{
ExecutorPrepareContext
(
const
framework
::
ProgramDesc
&
prog
,
size_t
block_id
);
~
ExecutorPrepareContext
();
const
framework
::
ProgramDesc
&
prog_
;
size_t
block_id_
;
std
::
vector
<
std
::
unique_ptr
<
OperatorBase
>>
ops_
;
};
class
Executor
{
class
Executor
{
public:
public:
// TODO(dzhwinter) : Do not rely on this function, it will be removed
// TODO(dzhwinter) : Do not rely on this function, it will be removed
...
@@ -47,8 +56,8 @@ class Executor {
...
@@ -47,8 +56,8 @@ class Executor {
const
std
::
string
&
feed_holder_name
=
"feed"
,
const
std
::
string
&
feed_holder_name
=
"feed"
,
const
std
::
string
&
fetch_holder_name
=
"fetch"
);
const
std
::
string
&
fetch_holder_name
=
"fetch"
);
static
ExecutorPrepareContext
*
Prepare
(
const
ProgramDesc
&
program
,
static
std
::
unique_ptr
<
ExecutorPrepareContext
>
Prepare
(
int
block_id
);
const
ProgramDesc
&
program
,
int
block_id
);
void
RunPreparedContext
(
ExecutorPrepareContext
*
ctx
,
Scope
*
scope
,
void
RunPreparedContext
(
ExecutorPrepareContext
*
ctx
,
Scope
*
scope
,
bool
create_local_scope
=
true
,
bool
create_local_scope
=
true
,
...
...
paddle/fluid/operators/elementwise_add_op.cu
浏览文件 @
edb4e29a
...
@@ -14,19 +14,20 @@ limitations under the License. */
...
@@ -14,19 +14,20 @@ limitations under the License. */
#define EIGEN_USE_GPU
#define EIGEN_USE_GPU
#include "paddle/fluid/operators/elementwise_add_op.h"
#include "paddle/fluid/operators/elementwise_add_op.h"
#include "paddle/fluid/platform/float16.h"
namespace
ops
=
paddle
::
operators
;
namespace
ops
=
paddle
::
operators
;
namespace
plat
=
paddle
::
platform
;
REGISTER_OP_CUDA_KERNEL
(
REGISTER_OP_CUDA_KERNEL
(
elementwise_add
,
elementwise_add
,
ops
::
ElementwiseAddKernel
<
plat
::
CUDADeviceContext
,
float
>
,
ops
::
ElementwiseAddKernel
<
p
addle
::
platform
::
CUDADeviceContext
,
float
>
,
ops
::
ElementwiseAddKernel
<
p
lat
::
CUDADeviceContext
,
double
>
,
ops
::
ElementwiseAddKernel
<
p
addle
::
platform
::
CUDADeviceContext
,
double
>
,
ops
::
ElementwiseAddKernel
<
p
lat
::
CUDADeviceContext
,
int
>
,
ops
::
ElementwiseAddKernel
<
p
addle
::
platform
::
CUDADeviceContext
,
in
t
>
,
ops
::
ElementwiseAddKernel
<
p
lat
::
CUDADeviceContext
,
int64_
t
>
,
ops
::
ElementwiseAddKernel
<
p
addle
::
platform
::
CUDADeviceContext
,
int64_t
>
);
ops
::
ElementwiseAddKernel
<
p
lat
::
CUDADeviceContext
,
plat
::
float16
>
);
REGISTER_OP_CUDA_KERNEL
(
REGISTER_OP_CUDA_KERNEL
(
elementwise_add_grad
,
elementwise_add_grad
,
ops
::
ElementwiseAddGradKernel
<
paddle
::
platform
::
CUDADeviceContext
,
float
>
,
ops
::
ElementwiseAddGradKernel
<
plat
::
CUDADeviceContext
,
float
>
,
ops
::
ElementwiseAddGradKernel
<
paddle
::
platform
::
CUDADeviceContext
,
double
>
,
ops
::
ElementwiseAddGradKernel
<
plat
::
CUDADeviceContext
,
double
>
,
ops
::
ElementwiseAddGradKernel
<
paddle
::
platform
::
CUDADeviceContext
,
int
>
,
ops
::
ElementwiseAddGradKernel
<
plat
::
CUDADeviceContext
,
int
>
,
ops
::
ElementwiseAddGradKernel
<
paddle
::
platform
::
CUDADeviceContext
,
ops
::
ElementwiseAddGradKernel
<
plat
::
CUDADeviceContext
,
int64_t
>
);
int64_t
>
);
paddle/fluid/platform/float16.h
浏览文件 @
edb4e29a
...
@@ -600,7 +600,7 @@ HOSTDEVICE inline bool operator>=(const float16& a, const float16& b) {
...
@@ -600,7 +600,7 @@ HOSTDEVICE inline bool operator>=(const float16& a, const float16& b) {
// Arithmetic operators for float16 on ARMv8.2-A CPU
// Arithmetic operators for float16 on ARMv8.2-A CPU
#elif defined(PADDLE_WITH_NATIVE_FP16)
#elif defined(PADDLE_WITH_NATIVE_FP16)
HOST
inline
float16
operator
+
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
+
(
const
float16
&
a
,
const
float16
&
b
)
{
float16
res
;
float16
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -616,7 +616,7 @@ HOST inline float16 operator+(const float16& a, const float16& b) {
...
@@ -616,7 +616,7 @@ HOST inline float16 operator+(const float16& a, const float16& b) {
return
res
;
return
res
;
}
}
HOST
inline
float16
operator
-
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
-
(
const
float16
&
a
,
const
float16
&
b
)
{
float16
res
;
float16
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -632,7 +632,7 @@ HOST inline float16 operator-(const float16& a, const float16& b) {
...
@@ -632,7 +632,7 @@ HOST inline float16 operator-(const float16& a, const float16& b) {
return
res
;
return
res
;
}
}
HOST
inline
float16
operator
*
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
*
(
const
float16
&
a
,
const
float16
&
b
)
{
float16
res
;
float16
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -648,7 +648,7 @@ HOST inline float16 operator*(const float16& a, const float16& b) {
...
@@ -648,7 +648,7 @@ HOST inline float16 operator*(const float16& a, const float16& b) {
return
res
;
return
res
;
}
}
HOST
inline
float16
operator
/
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
/
(
const
float16
&
a
,
const
float16
&
b
)
{
float16
res
;
float16
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -664,7 +664,7 @@ HOST inline float16 operator/(const float16& a, const float16& b) {
...
@@ -664,7 +664,7 @@ HOST inline float16 operator/(const float16& a, const float16& b) {
return
res
;
return
res
;
}
}
HOST
inline
float16
operator
-
(
const
float16
&
a
)
{
inline
float16
operator
-
(
const
float16
&
a
)
{
float16
res
;
float16
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -679,27 +679,27 @@ HOST inline float16 operator-(const float16& a) {
...
@@ -679,27 +679,27 @@ HOST inline float16 operator-(const float16& a) {
return
res
;
return
res
;
}
}
HOST
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
a
+
b
;
a
=
a
+
b
;
return
a
;
return
a
;
}
}
HOST
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
a
-
b
;
a
=
a
-
b
;
return
a
;
return
a
;
}
}
HOST
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
a
*
b
;
a
=
a
*
b
;
return
a
;
return
a
;
}
}
HOST
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
a
/
b
;
a
=
a
/
b
;
return
a
;
return
a
;
}
}
HOST
inline
bool
operator
==
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
==
(
const
float16
&
a
,
const
float16
&
b
)
{
uint16_t
res
;
uint16_t
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -715,11 +715,9 @@ HOST inline bool operator==(const float16& a, const float16& b) {
...
@@ -715,11 +715,9 @@ HOST inline bool operator==(const float16& a, const float16& b) {
return
(
res
&
0xffff
)
!=
0
;
return
(
res
&
0xffff
)
!=
0
;
}
}
HOST
inline
bool
operator
!=
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
!=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
!
(
a
==
b
);
}
return
!
(
a
==
b
);
}
HOST
inline
bool
operator
<
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
<
(
const
float16
&
a
,
const
float16
&
b
)
{
uint16_t
res
;
uint16_t
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v1.h}[0], [%[a_ptr]]
\n
"
"ld1 {v1.h}[0], [%[a_ptr]]
\n
"
...
@@ -735,7 +733,7 @@ HOST inline bool operator<(const float16& a, const float16& b) {
...
@@ -735,7 +733,7 @@ HOST inline bool operator<(const float16& a, const float16& b) {
return
(
res
&
0xffff
)
!=
0
;
return
(
res
&
0xffff
)
!=
0
;
}
}
HOST
inline
bool
operator
<=
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
<=
(
const
float16
&
a
,
const
float16
&
b
)
{
uint16_t
res
;
uint16_t
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v1.h}[0], [%[a_ptr]]
\n
"
"ld1 {v1.h}[0], [%[a_ptr]]
\n
"
...
@@ -751,7 +749,7 @@ HOST inline bool operator<=(const float16& a, const float16& b) {
...
@@ -751,7 +749,7 @@ HOST inline bool operator<=(const float16& a, const float16& b) {
return
(
res
&
0xffff
)
!=
0
;
return
(
res
&
0xffff
)
!=
0
;
}
}
HOST
inline
bool
operator
>
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
>
(
const
float16
&
a
,
const
float16
&
b
)
{
uint16_t
res
;
uint16_t
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -767,7 +765,7 @@ HOST inline bool operator>(const float16& a, const float16& b) {
...
@@ -767,7 +765,7 @@ HOST inline bool operator>(const float16& a, const float16& b) {
return
(
res
&
0xffff
)
!=
0
;
return
(
res
&
0xffff
)
!=
0
;
}
}
HOST
inline
bool
operator
>=
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
>=
(
const
float16
&
a
,
const
float16
&
b
)
{
uint16_t
res
;
uint16_t
res
;
asm
volatile
(
asm
volatile
(
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
"ld1 {v0.h}[0], [%[a_ptr]]
\n
"
...
@@ -785,69 +783,69 @@ HOST inline bool operator>=(const float16& a, const float16& b) {
...
@@ -785,69 +783,69 @@ HOST inline bool operator>=(const float16& a, const float16& b) {
// Arithmetic operators for float16, software emulated on other CPU
// Arithmetic operators for float16, software emulated on other CPU
#else
#else
HOST
inline
float16
operator
+
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
+
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
+
float
(
b
));
return
float16
(
float
(
a
)
+
float
(
b
));
}
}
HOST
inline
float16
operator
-
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
-
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
-
float
(
b
));
return
float16
(
float
(
a
)
-
float
(
b
));
}
}
HOST
inline
float16
operator
*
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
*
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
*
float
(
b
));
return
float16
(
float
(
a
)
*
float
(
b
));
}
}
HOST
inline
float16
operator
/
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
float16
operator
/
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float16
(
float
(
a
)
/
float
(
b
));
return
float16
(
float
(
a
)
/
float
(
b
));
}
}
HOST
inline
float16
operator
-
(
const
float16
&
a
)
{
inline
float16
operator
-
(
const
float16
&
a
)
{
float16
res
;
float16
res
;
res
.
x
=
a
.
x
^
0x8000
;
res
.
x
=
a
.
x
^
0x8000
;
return
res
;
return
res
;
}
}
HOST
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
+=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
+
float
(
b
));
a
=
float16
(
float
(
a
)
+
float
(
b
));
return
a
;
return
a
;
}
}
HOST
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
-=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
-
float
(
b
));
a
=
float16
(
float
(
a
)
-
float
(
b
));
return
a
;
return
a
;
}
}
HOST
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
*=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
*
float
(
b
));
a
=
float16
(
float
(
a
)
*
float
(
b
));
return
a
;
return
a
;
}
}
HOST
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
inline
float16
&
operator
/=
(
float16
&
a
,
const
float16
&
b
)
{
a
=
float16
(
float
(
a
)
/
float
(
b
));
a
=
float16
(
float
(
a
)
/
float
(
b
));
return
a
;
return
a
;
}
}
HOST
inline
bool
operator
==
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
==
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
==
float
(
b
);
return
float
(
a
)
==
float
(
b
);
}
}
HOST
inline
bool
operator
!=
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
!=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
!=
float
(
b
);
return
float
(
a
)
!=
float
(
b
);
}
}
HOST
inline
bool
operator
<
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
<
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
<
float
(
b
);
return
float
(
a
)
<
float
(
b
);
}
}
HOST
inline
bool
operator
<=
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
<=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
<=
float
(
b
);
return
float
(
a
)
<=
float
(
b
);
}
}
HOST
inline
bool
operator
>
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
>
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
>
float
(
b
);
return
float
(
a
)
>
float
(
b
);
}
}
HOST
inline
bool
operator
>=
(
const
float16
&
a
,
const
float16
&
b
)
{
inline
bool
operator
>=
(
const
float16
&
a
,
const
float16
&
b
)
{
return
float
(
a
)
>=
float
(
b
);
return
float
(
a
)
>=
float
(
b
);
}
}
#endif
#endif
...
...
python/paddle/fluid/executor.py
浏览文件 @
edb4e29a
...
@@ -235,66 +235,17 @@ class Executor(object):
...
@@ -235,66 +235,17 @@ class Executor(object):
tensor
.
set_lod
(
lod
)
tensor
.
set_lod
(
lod
)
return
tensor
return
tensor
def
run
(
self
,
def
_get_program_cache
(
self
,
program_cache_key
):
program
=
None
,
return
self
.
program_caches
.
get
(
program_cache_key
,
None
)
feed
=
None
,
fetch_list
=
None
,
feed_var_name
=
'feed'
,
fetch_var_name
=
'fetch'
,
scope
=
None
,
return_numpy
=
True
,
use_program_cache
=
False
):
""" Run program by this Executor. Feed data by feed map, fetch result by fetch_list.
Python executor takes a program, add feed operators and fetch operators to this program according
to feed map and fetch_list. Feed map provides input data for the program. fetch_list provides
the variables(or names) that user want to get after program run. Note: the executor will run all
operators in the program but not only the operators dependent by the fetch_list
:param program: the program that need to run, if not provied, then default_main_program will be used.
:param feed: feed variable map, e.g. {"image": ImageData, "label": LableData}
:param fetch_list: a list of variable or variable names that user want to get, run will return them according
to this list.
:param feed_var_name: the name for the input variable of feed Operator.
:param fetch_var_name: the name for the output variable of feed Operator.
:param scope: the scope used to run this program, you can switch it to different scope. default is global_scope
:param return_numpy: if convert the fetched tensor to numpy
:param use_program_cache: set use_program_cache to true if program not changed compare to the last step.
:return: result according to fetch_list.
"""
if
feed
is
None
:
feed
=
{}
if
not
isinstance
(
feed
,
dict
):
raise
TypeError
(
"feed should be a map"
)
if
fetch_list
is
None
:
fetch_list
=
[]
if
program
is
None
:
program
=
default_main_program
()
if
not
isinstance
(
program
,
Program
):
def
_add_program_cache
(
self
,
program_cache_key
,
program
):
raise
TypeError
()
self
.
program_caches
[
program_cache_key
]
=
program
if
scope
is
None
:
scope
=
global_scope
()
program_cache
=
None
program_cache_key
=
get_program_cache_key
(
feed
,
fetch_list
)
if
use_program_cache
:
def
_add_feed_fetch_ops
(
self
,
program
,
feed
,
fetch_list
,
feed_var_name
,
# find program cache by cache_key
fetch_var_name
):
program_cache
=
self
.
program_caches
.
get
(
program_cache_key
,
None
)
tmp_program
=
program
.
clone
()
# TODO(qiao): Should check program_cache and program are exactly the same.
else
:
self
.
program_caches
.
pop
(
program_cache_key
,
None
)
if
program_cache
is
None
:
program_cache
=
program
.
clone
()
if
use_program_cache
:
self
.
program_caches
[
program_cache_key
]
=
program_cache
global_block
=
program_cache
.
global_block
()
global_block
=
tmp_program
.
global_block
()
if
feed_var_name
in
global_block
.
vars
:
if
feed_var_name
in
global_block
.
vars
:
feed_var
=
global_block
.
var
(
feed_var_name
)
feed_var
=
global_block
.
var
(
feed_var_name
)
...
@@ -323,8 +274,7 @@ class Executor(object):
...
@@ -323,8 +274,7 @@ class Executor(object):
attrs
=
{
'col'
:
i
})
attrs
=
{
'col'
:
i
})
# append fetch_operators
# append fetch_operators
if
not
has_fetch_operators
(
global_block
,
fetch_list
,
if
not
has_fetch_operators
(
global_block
,
fetch_list
,
fetch_var_name
):
fetch_var_name
):
for
i
,
var
in
enumerate
(
fetch_list
):
for
i
,
var
in
enumerate
(
fetch_list
):
assert
isinstance
(
var
,
Variable
)
or
isinstance
(
var
,
str
),
(
assert
isinstance
(
var
,
Variable
)
or
isinstance
(
var
,
str
),
(
"Wrong type for fetch_list[%s]: %s"
%
(
i
,
type
(
var
)))
"Wrong type for fetch_list[%s]: %s"
%
(
i
,
type
(
var
)))
...
@@ -334,8 +284,11 @@ class Executor(object):
...
@@ -334,8 +284,11 @@ class Executor(object):
outputs
=
{
'Out'
:
[
fetch_var
]},
outputs
=
{
'Out'
:
[
fetch_var
]},
attrs
=
{
'col'
:
i
})
attrs
=
{
'col'
:
i
})
return
tmp_program
def
_feed_data
(
self
,
program
,
feed
,
feed_var_name
,
scope
):
# feed var to framework
# feed var to framework
for
op
in
program
_cache
.
global_block
().
ops
:
for
op
in
program
.
global_block
().
ops
:
if
op
.
desc
.
type
()
==
'feed'
:
if
op
.
desc
.
type
()
==
'feed'
:
feed_target_name
=
op
.
desc
.
output
(
'Out'
)[
0
]
feed_target_name
=
op
.
desc
.
output
(
'Out'
)[
0
]
cur_feed
=
feed
[
feed_target_name
]
cur_feed
=
feed
[
feed_target_name
]
...
@@ -346,11 +299,79 @@ class Executor(object):
...
@@ -346,11 +299,79 @@ class Executor(object):
else
:
else
:
break
break
self
.
executor
.
run
(
program_cache
.
desc
,
scope
,
0
,
True
,
True
)
def
_fetch_data
(
self
,
fetch_list
,
fetch_var_name
,
scope
):
outs
=
[
outs
=
[
core
.
get_fetch_variable
(
scope
,
fetch_var_name
,
i
)
core
.
get_fetch_variable
(
scope
,
fetch_var_name
,
i
)
for
i
in
xrange
(
len
(
fetch_list
))
for
i
in
xrange
(
len
(
fetch_list
))
]
]
return
outs
def
run
(
self
,
program
=
None
,
feed
=
None
,
fetch_list
=
None
,
feed_var_name
=
'feed'
,
fetch_var_name
=
'fetch'
,
scope
=
None
,
return_numpy
=
True
,
use_program_cache
=
False
):
""" Run program by this Executor. Feed data by feed map, fetch result by fetch_list.
Python executor takes a program, add feed operators and fetch operators to this program according
to feed map and fetch_list. Feed map provides input data for the program. fetch_list provides
the variables(or names) that user want to get after program run. Note: the executor will run all
operators in the program but not only the operators dependent by the fetch_list
:param program: the program that need to run, if not provied, then default_main_program will be used.
:param feed: feed variable map, e.g. {"image": ImageData, "label": LableData}
:param fetch_list: a list of variable or variable names that user want to get, run will return them according
to this list.
:param feed_var_name: the name for the input variable of feed Operator.
:param fetch_var_name: the name for the output variable of feed Operator.
:param scope: the scope used to run this program, you can switch it to different scope. default is global_scope
:param return_numpy: if convert the fetched tensor to numpy
:param use_program_cache: set use_program_cache to true if program not changed compare to the last step.
:return: result according to fetch_list.
"""
if
feed
is
None
:
feed
=
{}
if
not
isinstance
(
feed
,
dict
):
raise
TypeError
(
"feed should be a map"
)
if
fetch_list
is
None
:
fetch_list
=
[]
if
program
is
None
:
program
=
default_main_program
()
if
not
isinstance
(
program
,
Program
):
raise
TypeError
()
if
scope
is
None
:
scope
=
global_scope
()
cache_key
=
get_program_cache_key
(
feed
,
fetch_list
)
if
use_program_cache
:
cached_program
=
self
.
_get_program_cache
(
cache_key
)
if
cached_program
is
None
:
cached_program
=
self
.
_add_feed_fetch_ops
(
program
=
program
,
feed
=
feed
,
fetch_list
=
fetch_list
,
feed_var_name
=
feed_var_name
,
fetch_var_name
=
fetch_var_name
)
self
.
_add_program_cache
(
cache_key
,
cached_program
)
program
=
cached_program
else
:
self
.
program_caches
.
pop
(
cache_key
,
None
)
program
=
self
.
_add_feed_fetch_ops
(
program
=
program
,
feed
=
feed
,
fetch_list
=
fetch_list
,
feed_var_name
=
feed_var_name
,
fetch_var_name
=
fetch_var_name
)
self
.
_feed_data
(
program
,
feed
,
feed_var_name
,
scope
)
self
.
executor
.
run
(
program
.
desc
,
scope
,
0
,
True
,
True
)
outs
=
self
.
_fetch_data
(
fetch_list
,
fetch_var_name
,
scope
)
if
return_numpy
:
if
return_numpy
:
outs
=
as_numpy
(
outs
)
outs
=
as_numpy
(
outs
)
return
outs
return
outs
python/paddle/fluid/layers/nn.py
浏览文件 @
edb4e29a
...
@@ -1117,12 +1117,14 @@ def conv2d(input,
...
@@ -1117,12 +1117,14 @@ def conv2d(input,
filter_size
,
filter_size
,
stride
=
1
,
stride
=
1
,
padding
=
0
,
padding
=
0
,
dilation
=
1
,
groups
=
None
,
groups
=
None
,
param_attr
=
None
,
param_attr
=
None
,
bias_attr
=
None
,
bias_attr
=
None
,
use_cudnn
=
True
,
use_cudnn
=
True
,
use_mkldnn
=
False
,
use_mkldnn
=
False
,
act
=
None
):
act
=
None
,
name
=
None
):
"""
"""
**Convlution2D Layer**
**Convlution2D Layer**
...
@@ -1183,6 +1185,9 @@ def conv2d(input,
...
@@ -1183,6 +1185,9 @@ def conv2d(input,
padding(int|tuple): The padding size. If padding is a tuple, it must
padding(int|tuple): The padding size. If padding is a tuple, it must
contain two integers, (padding_H, padding_W). Otherwise, the
contain two integers, (padding_H, padding_W). Otherwise, the
padding_H = padding_W = padding. Default: padding = 0.
padding_H = padding_W = padding. Default: padding = 0.
dilation(int|tuple): The dilation size. If dilation is a tuple, it must
contain two integers, (dilation_H, dilation_W). Otherwise, the
dilation_H = dilation_W = dilation. Default: dilation = 1.
groups(int): The groups number of the Conv2d Layer. According to grouped
groups(int): The groups number of the Conv2d Layer. According to grouped
convolution in Alex Krizhevsky's Deep CNN paper: when group=2,
convolution in Alex Krizhevsky's Deep CNN paper: when group=2,
the first half of the filters is only connected to the first half
the first half of the filters is only connected to the first half
...
@@ -1193,6 +1198,8 @@ def conv2d(input,
...
@@ -1193,6 +1198,8 @@ def conv2d(input,
use_cudnn(bool): Use cudnn kernel or not, it is valid only when the cudnn
use_cudnn(bool): Use cudnn kernel or not, it is valid only when the cudnn
library is installed. Default: True
library is installed. Default: True
act(str): Activation type. Default: None
act(str): Activation type. Default: None
name(str|None): A name for this layer(optional). If set None, the layer
will be named automatically.
Returns:
Returns:
Variable: The tensor variable storing the convolution and
\
Variable: The tensor variable storing the convolution and
\
...
@@ -1233,6 +1240,7 @@ def conv2d(input,
...
@@ -1233,6 +1240,7 @@ def conv2d(input,
filter_size
=
utils
.
convert_to_list
(
filter_size
,
2
,
'filter_size'
)
filter_size
=
utils
.
convert_to_list
(
filter_size
,
2
,
'filter_size'
)
stride
=
utils
.
convert_to_list
(
stride
,
2
,
'stride'
)
stride
=
utils
.
convert_to_list
(
stride
,
2
,
'stride'
)
padding
=
utils
.
convert_to_list
(
padding
,
2
,
'padding'
)
padding
=
utils
.
convert_to_list
(
padding
,
2
,
'padding'
)
dilation
=
utils
.
convert_to_list
(
dilation
,
2
,
'dilation'
)
if
not
isinstance
(
use_cudnn
,
bool
):
if
not
isinstance
(
use_cudnn
,
bool
):
raise
ValueError
(
"use_cudnn should be True or False"
)
raise
ValueError
(
"use_cudnn should be True or False"
)
...
@@ -1262,6 +1270,7 @@ def conv2d(input,
...
@@ -1262,6 +1270,7 @@ def conv2d(input,
attrs
=
{
attrs
=
{
'strides'
:
stride
,
'strides'
:
stride
,
'paddings'
:
padding
,
'paddings'
:
padding
,
'dilations'
:
dilation
,
'groups'
:
groups
,
'groups'
:
groups
,
'use_cudnn'
:
use_cudnn
,
'use_cudnn'
:
use_cudnn
,
'use_mkldnn'
:
use_mkldnn
'use_mkldnn'
:
use_mkldnn
...
@@ -1670,7 +1679,9 @@ def conv2d_transpose(input,
...
@@ -1670,7 +1679,9 @@ def conv2d_transpose(input,
stride
=
1
,
stride
=
1
,
dilation
=
1
,
dilation
=
1
,
param_attr
=
None
,
param_attr
=
None
,
bias_attr
=
None
,
use_cudnn
=
True
,
use_cudnn
=
True
,
act
=
None
,
name
=
None
):
name
=
None
):
"""
"""
**Convlution2D transpose layer**
**Convlution2D transpose layer**
...
@@ -1739,8 +1750,10 @@ def conv2d_transpose(input,
...
@@ -1739,8 +1750,10 @@ def conv2d_transpose(input,
dilation_H = dilation_W = dilation. Default: dilation = 1.
dilation_H = dilation_W = dilation. Default: dilation = 1.
param_attr(ParamAttr): The parameters to the Conv2d_transpose Layer.
param_attr(ParamAttr): The parameters to the Conv2d_transpose Layer.
Default: None
Default: None
bias_attr(ParamAttr): Bias parameter for the Conv2d layer. Default: None
use_cudnn(bool): Use cudnn kernel or not, it is valid only when the cudnn
use_cudnn(bool): Use cudnn kernel or not, it is valid only when the cudnn
library is installed. Default: True
library is installed. Default: True
act(str): Activation type. Default: None
name(str|None): A name for this layer(optional). If set None, the layer
name(str|None): A name for this layer(optional). If set None, the layer
will be named automatically.
will be named automatically.
...
@@ -1793,12 +1806,12 @@ def conv2d_transpose(input,
...
@@ -1793,12 +1806,12 @@ def conv2d_transpose(input,
img_filter
=
helper
.
create_parameter
(
img_filter
=
helper
.
create_parameter
(
dtype
=
input
.
dtype
,
shape
=
filter_shape
,
attr
=
helper
.
param_attr
)
dtype
=
input
.
dtype
,
shape
=
filter_shape
,
attr
=
helper
.
param_attr
)
out
=
helper
.
create_tmp_variable
(
dtype
=
input
.
dtype
)
pre_bias
=
helper
.
create_tmp_variable
(
dtype
=
input
.
dtype
)
helper
.
append_op
(
helper
.
append_op
(
type
=
'conv2d_transpose'
,
type
=
'conv2d_transpose'
,
inputs
=
{
'Input'
:
[
input
],
inputs
=
{
'Input'
:
[
input
],
'Filter'
:
[
img_filter
]},
'Filter'
:
[
img_filter
]},
outputs
=
{
'Output'
:
out
},
outputs
=
{
'Output'
:
pre_bias
},
attrs
=
{
attrs
=
{
'strides'
:
stride
,
'strides'
:
stride
,
'paddings'
:
padding
,
'paddings'
:
padding
,
...
@@ -1806,6 +1819,8 @@ def conv2d_transpose(input,
...
@@ -1806,6 +1819,8 @@ def conv2d_transpose(input,
'use_cudnn'
:
use_cudnn
'use_cudnn'
:
use_cudnn
})
})
pre_act
=
helper
.
append_bias_op
(
pre_bias
,
dim_start
=
1
,
dim_end
=
2
)
out
=
helper
.
append_activation
(
pre_act
)
return
out
return
out
...
...
python/paddle/fluid/optimizer.py
浏览文件 @
edb4e29a
...
@@ -673,6 +673,123 @@ class AdadeltaOptimizer(Optimizer):
...
@@ -673,6 +673,123 @@ class AdadeltaOptimizer(Optimizer):
return
adadelta_op
return
adadelta_op
class
RMSPropOptimizer
(
Optimizer
):
"""
Root Mean Squared Propagation (RMSProp) is an unpublished, adaptive learning
rate method. The original slides proposed RMSProp: Slide 29 of
http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf .
The original equation is as follows:
.. math::
r(w, t) & =
\\
rho r(w, t-1) + (1 -
\\
rho)(
\\
nabla Q_{i}(w))^2
\\\\
w & = w -
\\
frac{
\\
eta} {
\\
sqrt{r(w,t) +
\\
epsilon}}
\\
nabla Q_{i}(w)
The first equation calculates moving average of the squared gradient for
each weight. Then dividing the gradient by :math: `sqrt{v(w,t)}`.
In some cases, adding a momentum term :math: `
\\
beta` is beneficial.
In our implementation, Nesterov momentum is used:
.. math::
r(w, t) & =
\\
rho r(w, t-1) + (1 -
\\
rho)(
\\
nabla Q_{i}(w))^2
\\\\
v(w, t) & =
\\
beta v(w, t-1) +
\\
frac{
\\
eta} {
\\
sqrt{v(w,t) +
\\
epsilon}}
\\
nabla Q_{i}(w)
w & = w - v(w, t)
where, :math: `
\\
rho` is a hyperparameter and typical values are 0.9, 0.95
and so on. :math: `beta` is the momentum term. :math: `
\\
epsilon` is a
smoothing term to avoid division by zero, usually set somewhere in range
from 1e-4 to 1e-8.
Args:
learning_rate(float): global leraning rate.
rho(float): rho is :math: `
\\
rho` in equation, set 0.95 by default.
epsilon(float): :math: `
\\
epsilon` in equation is smoothing term to
avoid division by zero, set 1e-6 by default.
momentum(float): :math: `
\\
beta` in equation is the momentum term,
set 0.0 by default.
Raises:
ValueError: If learning_rate, rho, epsilon, momentum are None.
Examples:
.. code-block:: python
optimizer = fluid.optimizer.RMSProp(0.0001)
_, params_grads = optimizer.minimize(cost)
"""
_momentum_acc_str
=
"momentum"
_mean_square_acc_str
=
"mean_square"
def
__init__
(
self
,
learning_rate
,
rho
=
0.95
,
epsilon
=
1.0e-6
,
momentum
=
0.0
,
**
kwargs
):
super
(
RMSPropOptimizer
,
self
).
__init__
(
learning_rate
=
learning_rate
,
**
kwargs
)
if
learning_rate
is
None
:
raise
ValueError
(
"learning_rate is not set."
)
if
rho
is
None
:
raise
ValueError
(
"rho is not set."
)
if
epsilon
is
None
:
raise
ValueError
(
"epsilon is not set."
)
if
momentum
is
None
:
raise
ValueError
(
"momentum is not set."
)
self
.
type
=
"rmsprop"
self
.
_rho
=
rho
self
.
_epsilon
=
epsilon
self
.
_momentum
=
momentum
def
_create_accumulators
(
self
,
block
,
parameters
):
if
not
isinstance
(
block
,
framework
.
Block
):
raise
TypeError
(
"block is not instance of framework.Block."
)
for
p
in
parameters
:
self
.
_add_accumulator
(
self
.
_momentum_acc_str
,
p
)
self
.
_add_accumulator
(
self
.
_mean_square_acc_str
,
p
)
def
_append_optimize_op
(
self
,
block
,
param_and_grad
):
if
not
isinstance
(
block
,
framework
.
Block
):
raise
TypeError
(
"block is not instance of framework.Block."
)
momentum_acc
=
self
.
_get_accumulator
(
self
.
_momentum_acc_str
,
param_and_grad
[
0
])
mean_square_acc
=
self
.
_get_accumulator
(
self
.
_mean_square_acc_str
,
param_and_grad
[
0
])
rmsprop_op
=
block
.
append_op
(
type
=
self
.
type
,
inputs
=
{
"Param"
:
param_and_grad
[
0
],
"Grad"
:
param_and_grad
[
1
],
"Moment"
:
momentum_acc
,
"MeanSquare"
:
mean_square_acc
,
"LearningRate"
:
self
.
_create_param_lr
(
param_and_grad
),
},
outputs
=
{
"ParamOut"
:
param_and_grad
[
0
],
"MomentOut"
:
momentum_acc
,
"MeanSquareOut"
:
mean_square_acc
},
attrs
=
{
"epsilon"
:
self
.
_epsilon
,
"decay"
:
self
.
_rho
,
"momentum"
:
self
.
_momentum
})
return
rmsprop_op
# We short the class name, since users will use the optimizer with the package
# We short the class name, since users will use the optimizer with the package
# name. The sample code:
# name. The sample code:
#
#
...
@@ -688,6 +805,7 @@ Adam = AdamOptimizer
...
@@ -688,6 +805,7 @@ Adam = AdamOptimizer
Adamax
=
AdamaxOptimizer
Adamax
=
AdamaxOptimizer
DecayedAdagrad
=
DecayedAdagradOptimizer
DecayedAdagrad
=
DecayedAdagradOptimizer
Adadelta
=
AdadeltaOptimizer
Adadelta
=
AdadeltaOptimizer
RMSProp
=
RMSPropOptimizer
class
ModelAverage
(
Optimizer
):
class
ModelAverage
(
Optimizer
):
...
...
python/paddle/fluid/tests/unittests/test_elementwise_add_op.py
浏览文件 @
edb4e29a
...
@@ -13,158 +13,243 @@
...
@@ -13,158 +13,243 @@
# limitations under the License.
# limitations under the License.
import
unittest
import
unittest
import
numpy
as
np
import
numpy
as
np
import
paddle.fluid.core
as
core
from
op_test
import
OpTest
from
op_test
import
OpTest
class
TestElementwiseOp
(
OpTest
):
class
TestElementwise
Add
Op
(
OpTest
):
def
setUp
(
self
):
def
setUp
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
op_type
=
"elementwise_add"
self
.
dtype
=
np
.
float32
self
.
axis
=
-
1
self
.
init_dtype
()
self
.
init_input_output
()
self
.
init_axis
()
self
.
inputs
=
{
self
.
inputs
=
{
'X'
:
np
.
random
.
uniform
(
0.1
,
1
,
[
13
,
17
]).
astype
(
"float32"
),
'X'
:
OpTest
.
np_dtype_to_fluid_dtype
(
self
.
x
),
'Y'
:
np
.
random
.
uniform
(
0.1
,
1
,
[
13
,
17
]).
astype
(
"float32"
)
'Y'
:
OpTest
.
np_dtype_to_fluid_dtype
(
self
.
y
)
}
}
self
.
outputs
=
{
'Out'
:
np
.
add
(
self
.
inputs
[
'X'
],
self
.
inputs
[
'Y'
])}
self
.
attrs
=
{
'axis'
:
self
.
axis
}
self
.
outputs
=
{
'Out'
:
self
.
out
}
def
test_check_output
(
self
):
def
test_check_output
(
self
):
self
.
check_output
()
self
.
check_output
()
def
test_check_grad_normal
(
self
):
def
test_check_grad_normal
(
self
):
if
self
.
dtype
==
np
.
float16
:
return
self
.
check_grad
([
'X'
,
'Y'
],
'Out'
,
max_relative_error
=
0.005
)
self
.
check_grad
([
'X'
,
'Y'
],
'Out'
,
max_relative_error
=
0.005
)
def
test_check_grad_ingore_x
(
self
):
def
test_check_grad_ingore_x
(
self
):
if
self
.
dtype
==
np
.
float16
:
return
self
.
check_grad
(
self
.
check_grad
(
[
'Y'
],
'Out'
,
max_relative_error
=
0.005
,
no_grad_set
=
set
(
"X"
))
[
'Y'
],
'Out'
,
max_relative_error
=
0.005
,
no_grad_set
=
set
(
"X"
))
def
test_check_grad_ingore_y
(
self
):
def
test_check_grad_ingore_y
(
self
):
if
self
.
dtype
==
np
.
float16
:
return
self
.
check_grad
(
self
.
check_grad
(
[
'X'
],
'Out'
,
max_relative_error
=
0.005
,
no_grad_set
=
set
(
'Y'
))
[
'X'
],
'Out'
,
max_relative_error
=
0.005
,
no_grad_set
=
set
(
'Y'
))
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
uniform
(
0.1
,
1
,
[
13
,
17
]).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
uniform
(
0.1
,
1
,
[
13
,
17
]).
astype
(
self
.
dtype
)
self
.
out
=
np
.
add
(
self
.
x
,
self
.
y
)
class
TestElementwiseAddOp_scalar
(
TestElementwiseOp
):
def
init_dtype
(
self
):
def
setUp
(
self
):
pass
self
.
op_type
=
"elementwise_add"
self
.
inputs
=
{
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
np
.
float32
),
'Y'
:
np
.
random
.
rand
(
1
).
astype
(
np
.
float32
)
}
self
.
outputs
=
{
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
]}
def
init_axis
(
self
):
pass
class
TestElementwiseAddOp_scalar2
(
TestElementwiseOp
):
def
setUp
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
inputs
=
{
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
np
.
float32
),
'Y'
:
np
.
random
.
rand
(
1
,
1
).
astype
(
np
.
float32
)
}
self
.
outputs
=
{
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
]}
class
TestFP16ElementwiseAddOp
(
TestElementwiseAddOp
):
def
init_dtype
(
self
):
self
.
dtype
=
np
.
float16
class
TestElementwiseAddOp_Vector
(
TestElementwiseOp
):
def
test_check_output
(
self
):
def
setUp
(
self
):
if
core
.
is_compiled_with_cuda
():
self
.
op_type
=
"elementwise_add"
place
=
core
.
CUDAPlace
(
0
)
self
.
inputs
=
{
if
core
.
is_float16_supported
(
place
):
'X'
:
np
.
random
.
random
((
32
,
)).
astype
(
"float32"
),
self
.
check_output_with_place
(
place
,
atol
=
1e-3
)
'Y'
:
np
.
random
.
random
((
32
,
)).
astype
(
"float32"
)
}
self
.
outputs
=
{
'Out'
:
np
.
add
(
self
.
inputs
[
'X'
],
self
.
inputs
[
'Y'
])}
class
TestElementwiseAddOp_broadcast_0
(
TestElementwiseOp
):
class
TestElementwiseAddOp_scalar
(
TestElementwiseAddOp
):
def
setUp
(
self
):
def
init_input_output
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
inputs
=
{
self
.
y
=
np
.
random
.
rand
(
1
).
astype
(
self
.
dtype
)
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
np
.
float32
),
self
.
out
=
self
.
x
+
self
.
y
'Y'
:
np
.
random
.
rand
(
2
).
astype
(
np
.
float32
)
}
self
.
attrs
=
{
'axis'
:
0
}
self
.
outputs
=
{
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
2
,
1
,
1
)
}
class
TestFP16ElementwiseAddOp_scalar
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
1
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
class
TestElementwiseAddOp_broadcast_1
(
TestElementwiseOp
):
def
setUp
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
inputs
=
{
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
np
.
float32
),
'Y'
:
np
.
random
.
rand
(
3
).
astype
(
np
.
float32
)
}
self
.
attrs
=
{
'axis'
:
1
}
class
TestElementwiseAddOp_scalar2
(
TestElementwiseAddOp
):
self
.
outputs
=
{
def
init_input_output
(
self
):
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
1
,
3
,
1
)
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
}
self
.
y
=
np
.
random
.
rand
(
1
,
1
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
class
TestElementwiseAddOp_broadcast_2
(
TestElementwiseOp
):
class
TestFP16ElementwiseAddOp_scalar2
(
TestFP16ElementwiseAddOp
):
def
setUp
(
self
):
def
init_input_output
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
inputs
=
{
self
.
y
=
np
.
random
.
rand
(
1
,
1
).
astype
(
self
.
dtype
)
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
np
.
float32
),
self
.
out
=
self
.
x
+
self
.
y
'Y'
:
np
.
random
.
rand
(
4
).
astype
(
np
.
float32
)
}
self
.
outputs
=
{
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
1
,
1
,
4
)
}
class
TestElementwiseAddOp_Vector
(
TestElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
random
((
32
,
)).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
random
((
32
,
)).
astype
(
self
.
dtype
)
self
.
out
=
np
.
add
(
self
.
x
,
self
.
y
)
class
TestElementwiseAddOp_broadcast_3
(
TestElementwiseOp
):
def
setUp
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
inputs
=
{
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
,
5
).
astype
(
np
.
float32
),
'Y'
:
np
.
random
.
rand
(
3
,
4
).
astype
(
np
.
float32
)
}
self
.
attrs
=
{
'axis'
:
1
}
class
TestFP16ElementwiseAddOp_Vector
(
TestFP16ElementwiseAddOp
):
self
.
outputs
=
{
def
init_input_output
(
self
):
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
1
,
3
,
4
,
1
)
self
.
x
=
np
.
random
.
random
((
32
,
)).
astype
(
self
.
dtype
)
}
self
.
y
=
np
.
random
.
random
((
32
,
)).
astype
(
self
.
dtype
)
self
.
out
=
np
.
add
(
self
.
x
,
self
.
y
)
class
TestElementwiseAddOp_broadcast_4
(
TestElementwiseOp
):
class
TestElementwiseAddOp_broadcast_0
(
TestElementwiseAddOp
):
def
setUp
(
self
):
def
init_input_output
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
inputs
=
{
self
.
y
=
np
.
random
.
rand
(
2
).
astype
(
self
.
dtype
)
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
,
5
).
astype
(
np
.
float32
),
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
2
,
1
,
1
)
'Y'
:
np
.
random
.
rand
(
2
,
1
).
astype
(
np
.
float32
)
}
self
.
attrs
=
{
'axis'
:
0
}
def
init_axis
(
self
):
self
.
outputs
=
{
self
.
axis
=
0
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
2
,
1
,
1
,
1
)
}
class
TestElementwiseAddOp_rowwise_add_0
(
TestElementwiseOp
):
class
TestFP16ElementwiseAddOp_broadcast_0
(
TestFP16ElementwiseAddOp
):
def
setUp
(
self
):
def
init_input_output
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
inputs
=
{
self
.
y
=
np
.
random
.
rand
(
2
).
astype
(
self
.
dtype
)
'X'
:
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
np
.
float32
),
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
2
,
1
,
1
)
'Y'
:
np
.
random
.
rand
(
3
,
4
).
astype
(
np
.
float32
)
}
self
.
attrs
=
{
'axis'
:
1
}
def
init_axis
(
self
):
self
.
outputs
=
{
self
.
axis
=
0
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
1
,
3
,
4
)
}
class
TestElementwiseAddOp_rowwise_add_1
(
TestElementwiseOp
):
class
TestElementwiseAddOp_broadcast_1
(
TestElementwiseAddOp
):
def
setUp
(
self
):
def
init_input_output
(
self
):
self
.
op_type
=
"elementwise_add"
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
inputs
=
{
self
.
y
=
np
.
random
.
rand
(
3
).
astype
(
self
.
dtype
)
'X'
:
np
.
random
.
rand
(
2
,
1
).
astype
(
np
.
float32
),
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
3
,
1
)
'Y'
:
np
.
random
.
rand
(
1
).
astype
(
np
.
float32
)
}
self
.
attrs
=
{
'axis'
:
1
}
def
init_axis
(
self
):
self
.
outputs
=
{
self
.
axis
=
1
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
].
reshape
(
1
,
1
)
}
class
TestFP16ElementwiseAddOp_broadcast_1
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
3
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
3
,
1
)
def
init_axis
(
self
):
self
.
axis
=
1
class
TestElementwiseAddOp_broadcast_2
(
TestElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
4
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
1
,
4
)
class
TestFP16ElementwiseAddOp_broadcast_2
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
4
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
1
,
4
)
class
TestElementwiseAddOp_broadcast_3
(
TestElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
,
5
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
3
,
4
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
3
,
4
,
1
)
def
init_axis
(
self
):
self
.
axis
=
1
class
TestFP16ElementwiseAddOp_broadcast_3
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
,
5
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
3
,
4
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
3
,
4
,
1
)
def
init_axis
(
self
):
self
.
axis
=
1
class
TestElementwiseAddOp_broadcast_4
(
TestElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
,
5
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
2
,
1
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
2
,
1
,
1
,
1
)
def
init_axis
(
self
):
self
.
axis
=
0
class
TestFP16ElementwiseAddOp_broadcast_4
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
,
5
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
2
,
1
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
2
,
1
,
1
,
1
)
def
init_axis
(
self
):
self
.
axis
=
0
class
TestElementwiseAddOp_rowwise_add_0
(
TestElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
3
,
4
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
3
,
4
)
def
init_axis
(
self
):
self
.
axis
=
1
class
TestFP16ElementwiseAddOp_rowwise_add_0
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
3
,
4
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
3
,
4
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
3
,
4
)
def
init_axis
(
self
):
self
.
axis
=
1
class
TestElementwiseAddOp_rowwise_add_1
(
TestElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
1
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
1
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
1
)
def
init_axis
(
self
):
self
.
axis
=
1
class
TestFP16ElementwiseAddOp_rowwise_add_1
(
TestFP16ElementwiseAddOp
):
def
init_input_output
(
self
):
self
.
x
=
np
.
random
.
rand
(
2
,
1
).
astype
(
self
.
dtype
)
self
.
y
=
np
.
random
.
rand
(
1
).
astype
(
self
.
dtype
)
self
.
out
=
self
.
x
+
self
.
y
.
reshape
(
1
,
1
)
def
init_axis
(
self
):
self
.
axis
=
1
if
__name__
==
'__main__'
:
if
__name__
==
'__main__'
:
...
...
python/paddle/fluid/tests/unittests/test_executor_and_mul.py
浏览文件 @
edb4e29a
...
@@ -16,7 +16,6 @@ import unittest
...
@@ -16,7 +16,6 @@ import unittest
import
numpy
import
numpy
import
paddle.fluid.core
as
core
import
paddle.fluid.core
as
core
from
paddle.fluid.executor
import
Executor
from
paddle.fluid.executor
import
Executor
from
paddle.fluid.layers
import
mul
,
data
from
paddle.fluid.layers
import
mul
,
data
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}