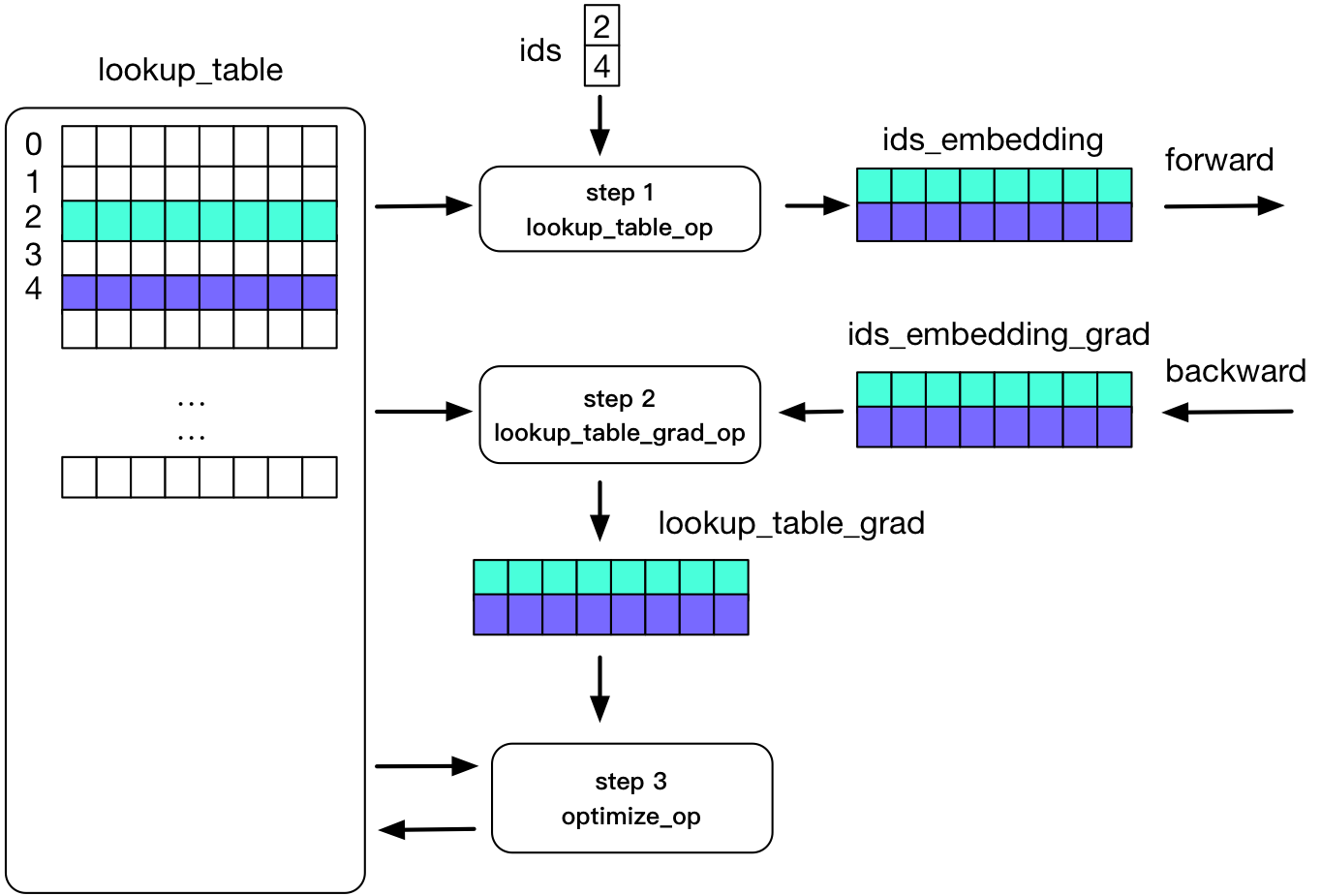
@@ -103,7 +103,7 @@ In computability theory, a system of data-manipulation rules, such as a programm
There are two ways to execute a Fluid program. When a program is executed, it creates a protobuf message [`ProgramDesc`](https://github.com/PaddlePaddle/Paddle/blob/a91efdde6910ce92a78e3aa7157412c4c88d9ee8/paddle/framework/framework.proto#L145) that describes the process and is conceptually like an [abstract syntax tree](https://en.wikipedia.org/wiki/Abstract_syntax_tree).
There is a C++ class [`Executor`](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/framework/executor.h), which runs a `ProgramDesc`, similar to how an interpreter runs a Python program.
There is a C++ class [`Executor`](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/framework/executor.h), which runs a `ProgramDesc`, similar to how an interpreter runs a Python program.
Fluid is moving towards the direction of a compiler, which is explain in [fluid_compiler.md](fluid_compiler.md).
{kind=link}
{kind=link}
{kind=link}
{kind=link}