PaddlePaddle is a deep learning platform open-sourced by Baidu. With PaddlePaddle, you can easily train a classic neural network within a couple lines of configuration, or you can build sophisticated models that provide state-of-the-art performance on difficult learning tasks like sentiment analysis, machine translation, image caption and so on.
Problem Background
------------------
Now, to give you a hint of what using PaddlePaddle looks like, let's start with a fundamental learning problem - `simple linear regression <https://en.wikipedia.org/wiki/Simple_linear_regression>`_: you have observed a set of two-dimensional data points of ``X`` and ``Y``, where ``X`` is an explanatory variable and ``Y`` is corresponding dependent variable, and you want to recover the underlying correlation between ``X`` and ``Y``. Linear regression can be used in many practical scenarios. For example, ``X`` can be a variable about house size, and ``Y`` a variable about house price. You can build a model that captures relationship between them by observing real estate markets.
Prepare the Data
-----------------
Suppose the true relationship can be characterized as ``Y = 2X + 0.3``, let's see how to recover this pattern only from observed data. Here is a piece of python code that feeds synthetic data to PaddlePaddle. The code is pretty self-explanatory, the only extra thing you need to add for PaddlePaddle is a definition of input data types.
To recover this relationship between ``X`` and ``Y``, we use a neural network with one layer of linear activation units and a square error cost layer. Don't worry if you are not familiar with these terminologies, it's just saying that we are starting from a random line ``Y' = wX + b`` , then we gradually adapt ``w`` and ``b`` to minimize the difference between ``Y'`` and ``Y``. Here is what it looks like in PaddlePaddle:
.. code-block:: python
# trainer_config.py
from paddle.trainer_config_helpers import *
# 1. read data. Suppose you saved above python code as dataprovider.py
Some of the most fundamental usages of PaddlePaddle are demonstrated:
- The first part shows how to feed data into PaddlePaddle. In general cases, PaddlePaddle reads raw data from a list of files, and then do some user-defined process to get real input. In this case, we only need to create a placeholder file since we are generating synthetic data on the fly.
- The second part describes learning algorithm. It defines in what ways adjustments are made to model parameters. PaddlePaddle provides a rich set of optimizers, but a simple momentum based optimizer will suffice here, and it processes 12 data points each time.
- Finally, the network configuration. It usually is as simple as "stacking" layers. Three kinds of layers are used in this configuration:
- **Data Layer**: a network always starts with one or more data layers. They provide input data to the rest of the network. In this problem, two data layers are used respectively for ``X`` and ``Y``.
- **FC Layer**: FC layer is short for Fully Connected Layer, which connects all the input units to current layer and does the actual computation specified as activation function. Computation layers like this are the fundamental building blocks of a deeper model.
- **Cost Layer**: in training phase, cost layers are usually the last layers of the network. They measure the performance of current model, and provide guidence to adjust parameters.
Now that everything is ready, you can train the network with a simple command line call:
This means that PaddlePaddle will train this network on the synthectic dataset for 30 passes, and save all the models under path ``./output``. You will see from the messages printed out during training phase that the model cost is decreasing as time goes by, which indicates we are getting a closer guess.
Evaluate the Model
-------------------
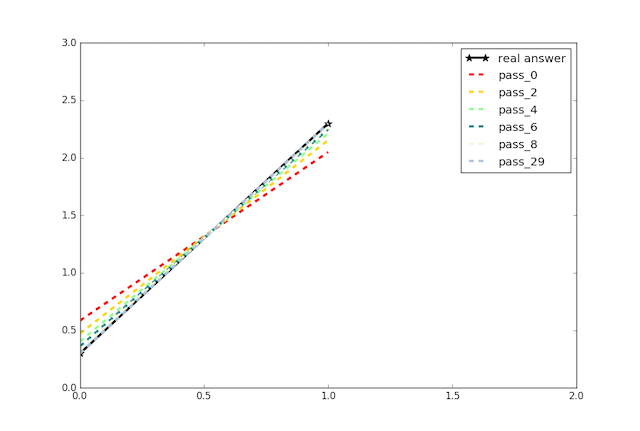
Usually, a different dataset that left out during training phase should be used to evalute the models. However, we are lucky enough to know the real answer: ``w=2, b=0.3``, thus a better option is to check out model parameters directly.
In PaddlePaddle, training is just to get a collection of model parameters, which are ``w`` and ``b`` in this case. Each parameter is saved in an individual file in the popular ``numpy`` array format. Here is the code that reads parameters from last pass.
Although starts from a random guess, you can see that value of ``w`` changes quickly towards 2 and ``b`` changes quickly towards 0.3. In the end, the predicted line is almost identical with real answer.
There, you have recovered the underlying pattern between ``X`` and ``Y`` only from observed data.
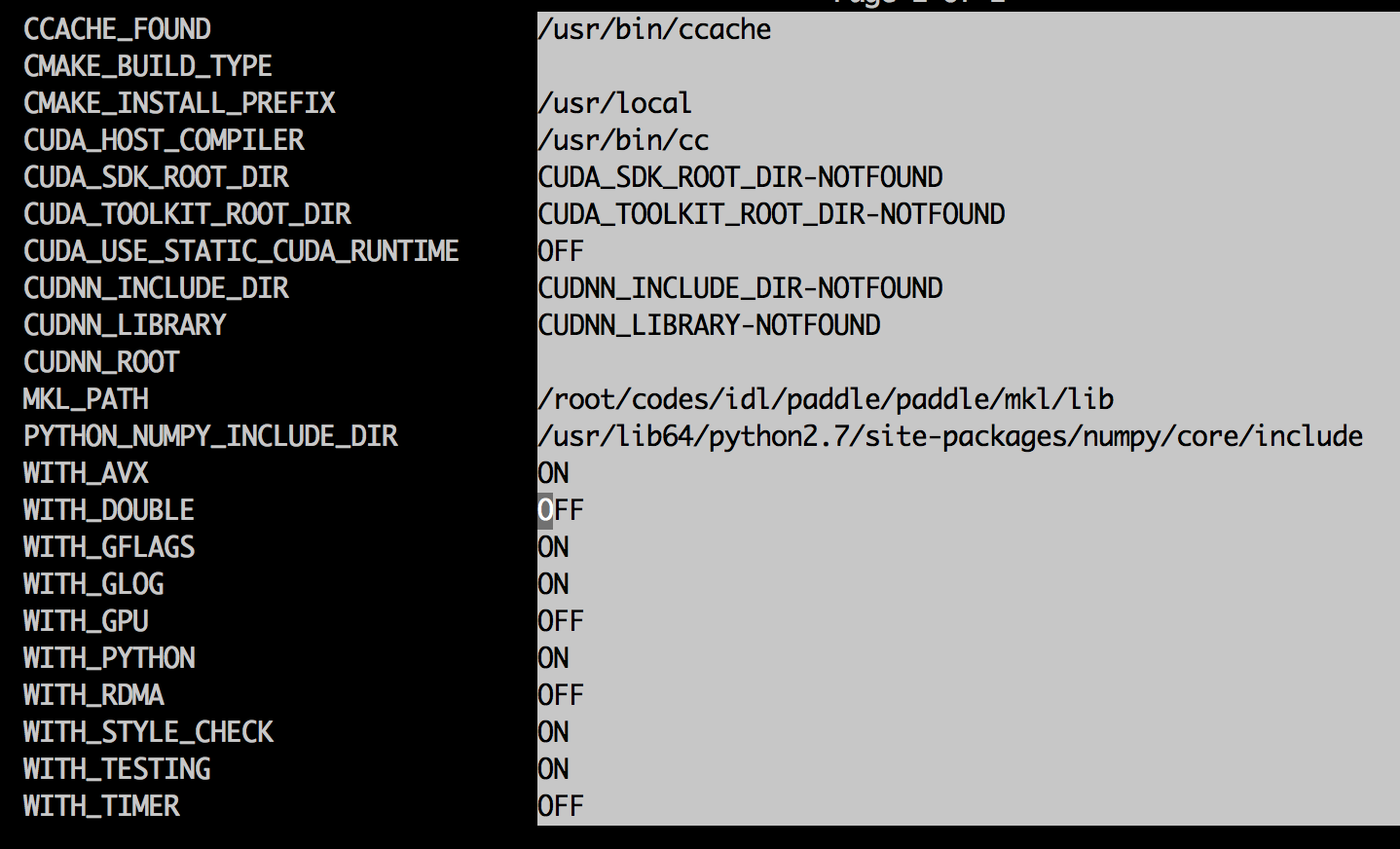
**NOTE: These options only take effect when running cmake for the first time, you need to clean the cmake cache or clean the build directory (** :code:`rm -rf` **) if you want to change it.**
PaddlePaddle目前唯一官方支持的运行的方式是Docker容器。因为Docker能在所有主要操作系统(包括Linux,Mac OS X和Windows)上运行。 请注意,您需要更改 `Dockers设置 <https://github.com/PaddlePaddle/Paddle/issues/627>`_ 才能充分利用Mac OS X和Windows上的硬件资源。
Docker is simple as long as we understand a few basic concepts:
After you've read above tutorials you may proceed the following steps.
- *image*: A Docker image is a pack of software. It could contain one or more programs and all their dependencies. For example, the PaddlePaddle's Docker image includes pre-built PaddlePaddle and Python and many Python packages. We can run a Docker image directly, other than installing all these software. We can type
.. _docker_pull:
.. code-block:: bash
Pull PaddlePaddle Docker Image
------------------------------
docker images
to list all images in the system. We can also run
Run the following command to download the latest Docker images:
.. code-block:: bash
.. code-block:: bash
docker pull paddlepaddle/paddle:0.10.0
docker pull paddlepaddle/paddle
to download a Docker image, paddlepaddle/paddle in this example,
from Dockerhub.com.
- *container*: considering a Docker image a program, a container is a
For users in China, we provide a faster mirror:
"process" that runs the image. Indeed, a container is exactly an
operating system process, but with a virtualized filesystem, network
port space, and other virtualized environment. We can type
.. code-block:: bash
.. code-block:: bash
docker run paddlepaddle/paddle:0.10.0
docker pull docker.paddlepaddle.org/paddle
to start a container to run a Docker image, paddlepaddle/paddle in this example.
Download GPU version images:
- By default docker container have an isolated file system namespace,
we can not see the files in the host file system. By using *volume*,
mounted files in host will be visible inside docker container.
Following command will mount current dirctory into /data inside
docker container, run docker container from debian image with
We package PaddlePaddle's compile environment into a Docker image,
called the develop image, it contains all compiling tools that
PaddlePaddle needs. We package compiled PaddlePaddle program into a
Docker image as well, called the production image, it contains all
runtime environment that running PaddlePaddle needs. For each version
of PaddlePaddle, we release both of them. Production image includes
CPU-only version and a CUDA GPU version and their no-AVX versions.
We put the docker images on `dockerhub.com
<https://hub.docker.com/r/paddlepaddle/paddle/tags/>`_. You can find the
latest versions under "tags" tab at dockerhub.com.
** NOTE: If you are in China, you can use our Docker image registry mirror to speed up the download process. To use it, please replace all paddlepaddle/paddle in the commands to docker.paddlepaddle.org/paddle.**
1. development image :code:`paddlepaddle/paddle:<version>-dev`
Choose between different BLAS version:
This image has packed related develop tools and runtime
environment. Users and developers can use this image instead of
their own local computer to accomplish development, build,
releasing, document writing etc. While different version of paddle
may depends on different version of libraries and tools, if you
want to setup a local environment, you must pay attention to the
versions. The development image contains:
- gcc/clang
- nvcc
- Python
- sphinx
- woboq
- sshd
Many developers use servers with GPUs, they can use ssh to login to
the server and run :code:`docker exec` to enter the docker
container and start their work. Also they can start a development
docker image with SSHD service, so they can login to the container
and start work.
2. Production images, this image might have multiple variants:
docker run -it -v $PWD:/work paddlepaddle/paddle /work/train.py
The above command will compile PaddlePaddle and create a Dockerfile for building production image. All the generated files are in the build directory. "WITH_GPU" controls if the generated production image supports GPU. "WITH_AVX" controls if the generated production image supports AVX. "WITH_TEST" controls if the unit test will be generated.
In the above command, :code:`-it` means run the container interactively;
:code:`-v $PWD:/work` means mount the current directory ($PWD will expand
to current absolute path in Linux) under :code:`/work` in the container.
:code:`paddlepaddle/paddle` to specify image to use; finnally
:code:`/work/train.py` is the command to run inside docker.
The second step is to run:
Also, you can go into the container shell, run or debug your code
interactively:
.. code-block:: bash
.. code-block:: bash
docker run -it -v $PWD:/work paddlepaddle/paddle /bin/bash
**NOTE: We did not install vim in the default docker image to reduce the image size, you can run** :code:`apt-get install -y vim` **to install it if you need to edit python files.**
The above command will generate the production image by copying the compiled PaddlePaddle program into the image.
{kind=link}
{kind=link}
{kind=link}