Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
BaiXuePrincess
Paddle
提交
60e0df0e
P
Paddle
项目概览
BaiXuePrincess
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
60e0df0e
编写于
2月 28, 2017
作者:
Y
yi.wu
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
refine k8s distributed training doc
上级
c444708a
变更
3
显示空白变更内容
内联
并排
Showing
3 changed file
with
182 addition
and
136 deletion
+182
-136
doc/howto/usage/k8s/k8s_basis.md
doc/howto/usage/k8s/k8s_basis.md
+77
-0
doc/howto/usage/k8s/k8s_distributed_cn.md
doc/howto/usage/k8s/k8s_distributed_cn.md
+105
-136
doc/howto/usage/k8s/src/k8s-paddle-arch.png
doc/howto/usage/k8s/src/k8s-paddle-arch.png
+0
-0
未找到文件。
doc/howto/usage/k8s/k8s_basis.md
0 → 100644
浏览文件 @
60e0df0e
# Kubernetes 简介
[
*Kubernetes*
](
http://kubernetes.io/
)
是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用。Kubernetes可以在物理机或虚拟机上运行,且支持部署到
[
AWS
](
http://kubernetes.io/docs/getting-started-guides/aws
)
,
[
Azure
](
http://kubernetes.io/docs/getting-started-guides/azure/
)
,
[
GCE
](
http://kubernetes.io/docs/getting-started-guides/gce
)
等多种公有云环境。介绍分布式训练之前,需要对
[
Kubernetes
](
http://kubernetes.io/
)
有一个基本的认识,下面先简要介绍一下本文用到的几个Kubernetes概念。
-
[
*Node*
](
http://kubernetes.io/docs/admin/node/
)
表示一个Kubernetes集群中的一个工作节点,这个节点可以是物理机或者虚拟机,Kubernetes集群就是由node节点与master节点组成的。
-
[
*Pod*
](
http://kubernetes.io/docs/user-guide/pods/
)
是一组(一个或多个)容器,pod是Kubernetes的最小调度单元,一个pod中的所有容器会被调度到同一个node上。Pod中的容器共享NET,PID,IPC,UTS等Linux namespace。由于容器之间共享NET namespace,所以它们使用同一个IP地址,可以通过
*localhost*
互相通信。不同pod之间可以通过IP地址访问。
-
[
*Job*
](
http://kubernetes.io/docs/user-guide/jobs/
)
描述Kubernetes上运行的作业,一次作业称为一个job,通常每个job包括一个或者多个pods,job启动后会创建这些pod并开始执行一个程序,等待这个程序执行成功并返回0则成功退出,如果执行失败,也可以配置不同的重试机制。
-
[
*Volume*
](
http://kubernetes.io/docs/user-guide/volumes/
)
存储卷,是pod内的容器都可以访问的共享目录,也是容器与node之间共享文件的方式,因为容器内的文件都是暂时存在的,当容器因为各种原因被销毁时,其内部的文件也会随之消失。通过volume,就可以将这些文件持久化存储。Kubernetes支持多种volume,例如hostPath(宿主机目录),gcePersistentDisk,awsElasticBlockStore等。
-
[
*Namespaces*
](
https://kubernetes.io/docs/user-guide/namespaces/
)
命名空间,在kubernetes中创建的所有资源对象(例如上文的pod,job)等都属于一个命名空间,在同一个命名空间中,资源对象的名字是唯一的,不同空间的资源名可以重复,命名空间主要为了对象进行逻辑上的分组便于管理。本文只使用了默认命名空间。
-
[
*PersistentVolume*
](
)
-
[
*PersistentVolumeClaim*
](
)
# 部署Kubernetes集群
Kubernetes提供了多种集群部署的方案,本文档内不重复介绍。这里给出集中常见的部署方法:
-
[
*minikube*
](
https://kubernetes.io/docs/getting-started-guides/minikube/
)
: 快速在本地启动一个单机的kubernetes服务器,便于本地验证和测试。
-
[
*kubeadm*
](
http://kubernetes.io/docs/getting-started-guides/kubeadm/
)
: 在不同操作系统,不同主机(Bare-Metal, AWS, GCE)条件下,快速部署集群。
-
[
*AWS EC2*
](
https://kubernetes.io/docs/getting-started-guides/aws/
)
: 在aws上快速部署集群。
-
[
*Bare-Metal*
](
https://kubernetes.io/docs/getting-started-guides/centos/centos_manual_config/
)
: 在物理机上手动部署。
可以参考
[
这个表格
](
https://kubernetes.io/docs/getting-started-guides/#table-of-solutions
)
选择适合您的场景的合适方案。
# 选择存储方案
容器不会保留在运行时生成的数据,job或者应用程序在容器中运行时生成的数据会在容器销毁时消失。为了完成分布式机器学习训练任务,需要有一个外部的存储服务来保存训练所需数据和训练输出。
常见的可选存储服务包括:
-
[
*NFS*
](
https://github.com/kubernetes/kubernetes/tree/master/examples/volumes/nfs
)
: 可以将磁盘上某个目录共享给网络中其他机器访问。部署和配置比较简单,可以用于小量数据的验证。不提供分布式存储,高可用,冗余等功能。NFS的部署方法可以参考
[
这里
](
http://www.tecmint.com/how-to-setup-nfs-server-in-linux/
)
。
-
[
*GlusterFS*
](
http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Quickstart/
)
: 网络分布式文件系统,可以在Kubernetes中按照
[
这个
](
https://github.com/kubernetes/kubernetes/tree/master/examples/volumes/glusterfs
)
例子使用。
-
[
*Ceph*
](
http://docs.ceph.com/docs/master/
)
: 分布式文件系统,支持rbd,POSIX API接口(ceph fs)和对象存储API,参考
[
这里
](
https://kubernetes.io/docs/user-guide/volumes/#rbd
)
。
-
[
*MooseFS*
](
https://moosefs.com/documentation.html
)
: 一个分布式的存储系统。需要先挂载到服务器Node上再通过kubernetes hostPath Volume挂载到容器中。
# 配置kubectl
## 安装kubectl
```
# OS X
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl
# Linux
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
# Windows
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/windows/amd64/kubectl.exe
```
## 配置kubectl访问你的kubernetes集群
编辑
`~/.kube/config`
这个配置文件,修改
`Master-IP`
的地址。如果使用SSL认证,则需要配置
`certificate-authority`
和
`users`
中的用户证书。如果是使用非SSL方式访问(比如通过8080都安口),也可以去掉这些证书的配置。
```
apiVersion: v1
clusters:
- cluster:
certificate-authority: /path/to/ca.crt
server: https://[Master-IP]:443
name: minikube
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: /path/to/apiserver.crt
client-key: /Users/wuyi/.minikube/apiserver.key
```
doc/howto/usage/k8s/k8s_distributed_cn.md
浏览文件 @
60e0df0e
#
Kubernetes
分布式训练
#
使用Paddle在Kubernetes集群上完成
分布式训练
前一篇文章介绍了如何在Kubernetes集群上启动一个单机PaddlePaddle训练作业 (Job)。在这篇文章里,我们介绍如何在Kubernetes集群上进行分布式PaddlePaddle训练作业。关于PaddlePaddle的分布式训练,文章
[
Cluster Training
](
https://github.com/baidu/Paddle/blob/develop/doc/cluster/opensource/cluster_train.md
)
介绍了一种通过SSH远程分发任务,进行分布式训练的方法,与此不同的是,本文将介绍在Kubernetes容器管理平台上快速构建PaddlePaddle容器集群,进行分布式训练的方案。
## Kubernetes 基本概念
[
*Kubernetes*
](
http://kubernetes.io/
)
是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用。Kubernetes可以在物理机或虚拟机上运行,且支持部署到
[
AWS
](
http://kubernetes.io/docs/getting-started-guides/aws
)
,
[
Azure
](
http://kubernetes.io/docs/getting-started-guides/azure/
)
,
[
GCE
](
http://kubernetes.io/docs/getting-started-guides/gce
)
等多种公有云环境。介绍分布式训练之前,需要对
[
Kubernetes
](
http://kubernetes.io/
)
有一个基本的认识,下面先简要介绍一下本文用到的几个Kubernetes概念。
-
[
*Node*
](
http://kubernetes.io/docs/admin/node/
)
表示一个Kubernetes集群中的一个工作节点,这个节点可以是物理机或者虚拟机,Kubernetes集群就是由node节点与master节点组成的。
-
[
*Pod*
](
http://kubernetes.io/docs/user-guide/pods/
)
是一组(一个或多个)容器,pod是Kubernetes的最小调度单元,一个pod中的所有容器会被调度到同一个node上。Pod中的容器共享NET,PID,IPC,UTS等Linux namespace。由于容器之间共享NET namespace,所以它们使用同一个IP地址,可以通过
*localhost*
互相通信。不同pod之间可以通过IP地址访问。
-
[
*Job*
](
http://kubernetes.io/docs/user-guide/jobs/
)
是Kubernetes上运行的作业,一次作业称为一个job,通常每个job包括一个或者多个pods。
-
[
*Volume*
](
http://kubernetes.io/docs/user-guide/volumes/
)
存储卷,是pod内的容器都可以访问的共享目录,也是容器与node之间共享文件的方式,因为容器内的文件都是暂时存在的,当容器因为各种原因被销毁时,其内部的文件也会随之消失。通过volume,就可以将这些文件持久化存储。Kubernetes支持多种volume,例如hostPath(宿主机目录),gcePersistentDisk,awsElasticBlockStore等。
-
[
*Namespaces*
](
http://kubernetes.io/docs/user-guide/volumes/
)
命名空间,在kubernetes中创建的所有资源对象(例如上文的pod,job)等都属于一个命名空间,在同一个命名空间中,资源对象的名字是唯一的,不同空间的资源名可以重复,命名空间主要为了对象进行逻辑上的分组便于管理。本文只使用了默认命名空间。
有关Kubernetes相关概念以及如何搭建和配置Kubernetes集群,可以参考
[
k8s_basis
](
./k8s_basis.md
)
。
## 整体方案
### 部署Kubernetes集群
首先,我们需要拥有一个Kubernetes集群,在这个集群中所有node与pod都可以互相通信。关于Kubernetes集群搭建,可以参考
[
官方文档
](
http://kubernetes.io/docs/getting-started-guides/kubeadm/
)
,在以后的文章中我们也会介绍AWS上搭建的方案。本文假设大家能找到几台物理机,并且可以按照官方文档在上面部署Kubernetes。在本文的环境中,Kubernetes集群中所有node都挂载了一个
[
MFS
](
http://moosefs.org/
)
(Moose filesystem,一种分布式文件系统)共享目录,我们通过这个目录来存放训练文件与最终输出的模型。关于MFS的安装部署,可以参考
[
MooseFS documentation
](
https://moosefs.com/documentation.html
)
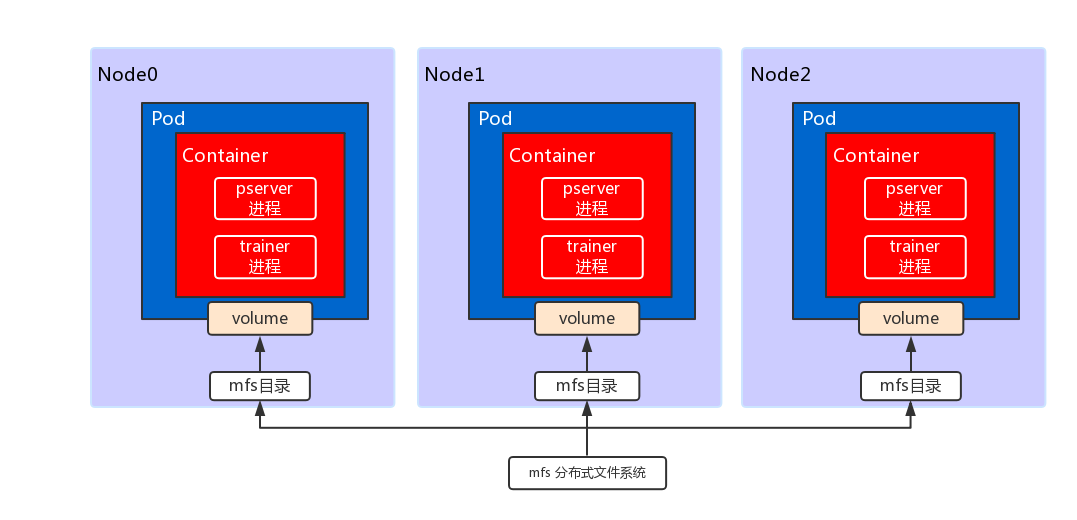
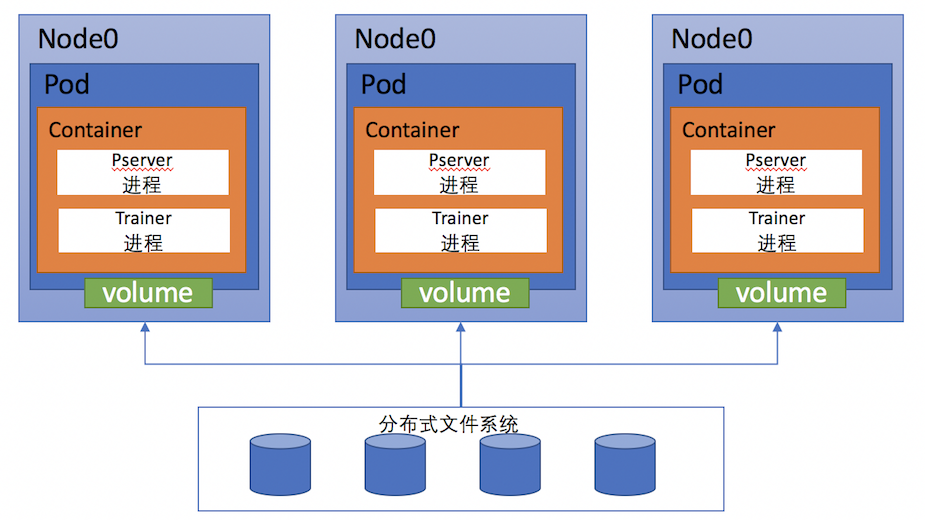
。在训练之前,用户将配置与训练数据切分好放在MFS目录中,训练时,程序从此目录拷贝文件到容器内进行训练,将结果保存到此目录里。整体的结构图如下:
在训练之前,用户将配置与训练数据切分好放在MFS目录中,训练时,程序从此目录拷贝文件到容器内进行训练,将结果保存到此目录里。整体的结构图如下:

上图描述了一个3节点的分布式训练场景,Kubernetes集群的每个node上都挂载了一个MFS目录,这个目录可以通过volume的形式挂载到容器中。Kubernetes为这次训练创建了3个pod并且调度到了3个node上运行,每个pod包含一个PaddlePaddle容器。在容器创建后,会启动pserver与trainer进程,读取volume中的数据进行这次分布式训练。
### 使用 Job
我们使用Kubernetes中的job这个概念来代表一次分布式训练。Job表示一次性作业,在作业完成后,Kubernetes会销毁job产生的容器并且释放相关资源。
在Kubernetes中,可以通过编写一个YAML文件,来描述这个job,在这个文件中,主要包含了一些配置信息,例如PaddlePaddle的节点个数,
`paddle pserver`
开放的端口个数与端口号,使用的网卡设备等,这些信息通过环境变量的形式传递给容器内的程序使用。
上图描述了一个3节点的分布式训练场景,在每个Pod上都通过volume方式挂载分布式文件系统的一个目录用于保存训练数据和输出结果。Kubernetes为这次训练创建了3个pod并且调度到了3个node上运行,每个pod包含一个PaddlePaddle容器。在容器创建后,会启动pserver与trainer进程,读取volume中的数据进行这次分布式训练。
在一次分布式训练中,用户确定好本次训练需要的PaddlePaddle节点个数,将切分好的训练数据与配置文件上传到MFS共享目录中。然后编写这次训练的job YAML文件,提交给Kubernetes集群创建并开始作业。
根据前文的描述,要在已有的Kubernetes集群上进行PaddlePaddle的分布式训练,按照下面步骤即可:
### 创建PaddlePaddle节点
当Kubernetes master收到请求,解析完YAML文件后,会创建出多个pod(个数为PaddlePaddle节点数),Kubernetes会把这些pod调度到集群的node上运行。一个pod就代表一个PaddlePaddle节点,当pod被成功分配到一台物理/虚拟机上后,Kubernetes会启动pod内的容器,这个容器会根据YAML文件中的环境变量,启动
`paddle pserver`
与
`paddle train`
进程。
### 启动训练
在容器启动后,会通过脚本来启动这次分布式训练,我们知道
`paddle train`
进程启动时需要知道其他节点的IP地址以及本节点的trainer_id,由于PaddlePaddle本身不提供类似服务发现的功能,所以在本文的启动脚本中,每个节点会根据job name向Kubernetes apiserver查询这个job对应的所有pod信息(Kubernetes默认会在每个容器的环境变量中写入apiserver的地址)。
根据这些pod信息,就可以通过某种方式,为每个pod分配一个唯一的trainer_id。本文把所有pod的IP地址进行排序,将顺序作为每个PaddlePaddle节点的trainer_id。启动脚本的工作流程大致如下:
1.
查询Kubernetes apiserver获取pod信息,根据IP分配trainer_id
1.
从MFS共享目录中拷贝训练文件到容器内
1.
根据环境变量,解析出
`paddle pserver`
与
`paddle train`
的启动参数,启动进程
1.
训练时,PaddlePaddle会自动将结果保存在trainer_id为0的节点上,将输出路径设置为MFS目录,保存输出的文件
## 搭建过程
根据前文的描述,要在已有的Kubernetes集群上进行PaddlePaddle的分布式训练,主要分为以下几个步骤:
1.
制作PaddlePaddle镜像
1.
将训练文件与切分好的数据上传到共享存储
1.
编写本次训练的YAML文件,创建一个Kubernetes job
1.
训练结束后查看输出结果
1.
[
制作PaddlePaddle镜像
](
#制作镜像
)
1.
[
将训练文件与切分好的数据上传到共享存储
](
#上传训练文件
)
1.
[
编写本次训练的YAML文件,创建一个Kubernetes job
](
#创建Job
)
1.
[
训练结束后查看输出结果
](
#查看输出
)
下面就根据这几个步骤分别介绍。
### 制作镜像
PaddlePaddle镜像需要提供
`paddle pserver`
与
`paddle train`
进程的运行环境,用这个镜像创建的容器需要有以下两个功能:
-
拷贝训练文件到容器内
-
生成
`paddle pserver`
与
`paddle train`
进程的启动参数,并且启动训练
因为官方镜像
`paddledev/paddle:cpu-latest`
内已经包含PaddlePaddle的执行程序但是还没上述功能,所以我们可以在这个基础上,添加启动脚本,制作新镜像来完成以上的工作。镜像的
*Dockerfile*
如下:
```
Dockerfile
FROM
paddledev/paddle:cpu-latest
MAINTAINER
zjsxzong89@gmail.com
COPY
start.sh /root/
COPY
start_paddle.py /root/
CMD
["bash"," -c","/root/start.sh"]
```
[
start.sh
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/usage/cluster/k8s/start.sh
)
文件拷贝训练文件到容器内,然后执行
[
start_paddle.py
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/usage/cluster/k8s/start_paddle.py
)
脚本启动训练,前文提到的获取其他节点IP地址,分配
`trainer_id`
等都在
`start_paddle.py`
脚本中完成。
`start_paddle.py`
脚本开始时,会先进行参数的初始化与解析。
```
python
parser
=
argparse
.
ArgumentParser
(
prog
=
"start_paddle.py"
,
description
=
'simple tool for k8s'
)
args
,
train_args_list
=
parser
.
parse_known_args
()
train_args
=
refine_unknown_args
(
train_args_list
)
train_args_dict
=
dict
(
zip
(
train_args
[:
-
1
:
2
],
train_args
[
1
::
2
]))
podlist
=
getPodList
()
```
然后通过函数
`getPodList()`
访问Kubernetes的接口来查询此job对应的所有pod信息。当所有pod都处于running状态(容器运行都运行)时,再通过函数
`getIdMap(podlist)`
获取trainer_id。
```
python
podlist
=
getPodList
()
# need to wait until all pods are running
while
not
isPodAllRunning
(
podlist
):
time
.
sleep
(
10
)
podlist
=
getPodList
()
idMap
=
getIdMap
(
podlist
)
```
在函数
`getIdMap(podlist)`
内部,我们通过读取
`podlist`
中每个pod的IP地址,将IP排序生成的序号作为trainer_id。
```
python
def
getIdMap
(
podlist
):
'''
generate tainer_id by ip
'''
ips
=
[]
for
pod
in
podlist
[
"items"
]:
ips
.
append
(
pod
[
"status"
][
"podIP"
])
ips
.
sort
()
idMap
=
{}
for
i
in
range
(
len
(
ips
)):
idMap
[
ips
[
i
]]
=
i
return
idMap
```
在得到
`idMap`
后,通过函数
`startPaddle(idMap, train_args_dict)`
构造
`paddle pserver`
与
`paddle train`
的启动参数并执行进程。
在函数
`startPaddle`
中,最主要的工作就是解析出
`paddle pserver`
与
`paddle train`
的启动参数。例如
`paddle train`
参数的解析,解析环境变量得到
`PADDLE_NIC`
,
`PADDLE_PORT`
,
`PADDLE_PORTS_NUM`
等参数,然后通过自身的IP地址在
`idMap`
中获取
`trainerId`
。
```
python
program
=
'paddle train'
args
=
" --nics="
+
PADDLE_NIC
args
+=
" --port="
+
str
(
PADDLE_PORT
)
args
+=
" --ports_num="
+
str
(
PADDLE_PORTS_NUM
)
args
+=
" --comment="
+
"paddle_process_by_paddle"
ip_string
=
""
for
ip
in
idMap
.
keys
():
ip_string
+=
(
ip
+
","
)
ip_string
=
ip_string
.
rstrip
(
","
)
args
+=
" --pservers="
+
ip_string
args_ext
=
""
for
key
,
value
in
train_args_dict
.
items
():
args_ext
+=
(
' --'
+
key
+
'='
+
value
)
localIP
=
socket
.
gethostbyname
(
socket
.
gethostname
())
trainerId
=
idMap
[
localIP
]
args
+=
" "
+
args_ext
+
" --trainer_id="
+
\
str
(
trainerId
)
+
" --save_dir="
+
JOB_PATH_OUTPUT
```
使用
`docker build`
构建镜像:
因为官方镜像
`paddledev/paddle:cpu-latest`
内已经包含PaddlePaddle的执行程序但是还没上述功能,所以我们可以在这个基础上,添加启动脚本,制作新镜像来完成以上的工作。参考镜像的
[
*Dockerfile*
](
(https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/usage/cluster/k8s/src/k8s_train/Dockerfile
)
。
```
bash
docker build
-t
your_repo/paddle:mypaddle .
$
cd
doc/howto/usage/k8s/src/k8s_train
$
docker build
-t
[
YOUR_REPO]/paddle:mypaddle .
```
然后将构建成功的镜像上传到镜像仓库。
```
bash
docker push
your_repo
/paddle:mypaddle
docker push
[
YOUR_REPO]
/paddle:mypaddle
```
注意上述命令中
`
your_repo`
表示读者所使用的Docker镜像仓库地址,读者需要替换成自己使用的仓库地址。下文使用
`your_repo
/paddle:mypaddle`
这个地址来表示此步骤所构建出的镜像。
注意上述命令中
`
[YOUR_REPO]`
表示读者所使用的Docker镜像仓库地址,读者需要替换成自己使用的仓库地址。下文使用
`[YOUR_REPO]
/paddle:mypaddle`
这个地址来表示此步骤所构建出的镜像。
### 上传训练文件
本文使用PaddlePaddle官方的
[
recommendation demo
](
http://www.paddlepaddle.org/doc/demo/index.html#recommendation
)
作为这次训练的内容,我们将训练文件与数据放在一个job name命名的目录中,上传到
MFS共享存储。完成后MFS上
的文件内容大致如下:
本文使用PaddlePaddle官方的
[
recommendation demo
](
http://www.paddlepaddle.org/doc/demo/index.html#recommendation
)
作为这次训练的内容,我们将训练文件与数据放在一个job name命名的目录中,上传到
volume所在的共享存储(使用不同分布式存储会有不同的挂载方式,需要要先挂载这个目录,然后拷贝数据)。完成后volume中
的文件内容大致如下:
```
bash
[
root@paddle-kubernetes-node0 mfs]# tree
-d
...
...
@@ -205,7 +87,7 @@ spec:
path
:
/home/work/mfs
containers
:
-
name
:
trainer
image
:
your_repo
/paddle:mypaddle
image
:
[
YOUR_REPO
]
/paddle:mypaddle
command
:
[
"
bin/bash"
,
"
-c"
,
"
/root/start.sh"
]
env
:
-
name
:
JOB_NAME
...
...
@@ -310,3 +192,90 @@ I1116 09:10:18.019492 50 ParameterClient2.cpp:122] pserver 3 192.168.223.143:
I1116 09:10:18.019716 50 ParameterClient2.cpp:122] pserver 4 192.168.129.71:7164
I1116 09:10:18.019836 50 ParameterClient2.cpp:122] pserver 5 192.168.129.71:7165
```
## 一些细节的补充
### 使用环境变量
使用容器方式运行训练任务的Kubernetes Job,通常会使用环境变量配置Job的配置信息
`start_paddle.py`
提供了一个启动脚本,将环境变量转换成paddle的命令行参数:
```
API = "/api/v1/namespaces/"
JOBSELECTOR = "labelSelector=job-name="
JOB_PATH = os.getenv("JOB_PATH") + "/" + os.getenv("JOB_NAME")
JOB_PATH_OUTPUT = JOB_PATH + "/output"
JOBNAME = os.getenv("JOB_NAME")
NAMESPACE = os.getenv("JOB_NAMESPACE")
PADDLE_NIC = os.getenv("CONF_PADDLE_NIC")
PADDLE_PORT = os.getenv("CONF_PADDLE_PORT")
PADDLE_PORTS_NUM = os.getenv("CONF_PADDLE_PORTS_NUM")
PADDLE_PORTS_NUM_SPARSE = os.getenv("CONF_PADDLE_PORTS_NUM_SPARSE")
PADDLE_SERVER_NUM = os.getenv("CONF_PADDLE_GRADIENT_NUM")
```
### Pod间通信
`start_paddle.py`
脚本开始时,会先进行参数的初始化与解析。
```
python
parser
=
argparse
.
ArgumentParser
(
prog
=
"start_paddle.py"
,
description
=
'simple tool for k8s'
)
args
,
train_args_list
=
parser
.
parse_known_args
()
train_args
=
refine_unknown_args
(
train_args_list
)
train_args_dict
=
dict
(
zip
(
train_args
[:
-
1
:
2
],
train_args
[
1
::
2
]))
podlist
=
getPodList
()
```
然后通过函数
`getPodList()`
访问Kubernetes的接口来查询此job对应的所有pod信息。当所有pod都处于running状态(容器运行都运行)时,再通过函数
`getIdMap(podlist)`
获取trainer_id。
```
python
podlist
=
getPodList
()
# need to wait until all pods are running
while
not
isPodAllRunning
(
podlist
):
time
.
sleep
(
10
)
podlist
=
getPodList
()
idMap
=
getIdMap
(
podlist
)
```
*
*注意*
:
`getPodList()`
会获取当前namespace下的所有pod,如果已经有pod运行,可能会导致出错。这种集群节点管理方式会在将来使用
[
statfulsets
](
https://kubernetes.io/docs/concepts/abstractions/controllers/statefulsets/
)
代替。
在函数
`getIdMap(podlist)`
内部,我们通过读取
`podlist`
中每个pod的IP地址,将IP排序生成的序号作为trainer_id。
```
python
def
getIdMap
(
podlist
):
'''
generate tainer_id by ip
'''
ips
=
[]
for
pod
in
podlist
[
"items"
]:
ips
.
append
(
pod
[
"status"
][
"podIP"
])
ips
.
sort
()
idMap
=
{}
for
i
in
range
(
len
(
ips
)):
idMap
[
ips
[
i
]]
=
i
return
idMap
```
在得到
`idMap`
后,通过函数
`startPaddle(idMap, train_args_dict)`
构造
`paddle pserver`
与
`paddle train`
的启动参数并执行进程。
### 启动任务
在函数
`startPaddle`
中,最主要的工作就是解析出
`paddle pserver`
与
`paddle train`
的启动参数。例如
`paddle train`
参数的解析,解析环境变量得到
`PADDLE_NIC`
,
`PADDLE_PORT`
,
`PADDLE_PORTS_NUM`
等参数,然后通过自身的IP地址在
`idMap`
中获取
`trainerId`
。
```
python
program
=
'paddle train'
args
=
" --nics="
+
PADDLE_NIC
args
+=
" --port="
+
str
(
PADDLE_PORT
)
args
+=
" --ports_num="
+
str
(
PADDLE_PORTS_NUM
)
args
+=
" --comment="
+
"paddle_process_by_paddle"
ip_string
=
""
for
ip
in
idMap
.
keys
():
ip_string
+=
(
ip
+
","
)
ip_string
=
ip_string
.
rstrip
(
","
)
args
+=
" --pservers="
+
ip_string
args_ext
=
""
for
key
,
value
in
train_args_dict
.
items
():
args_ext
+=
(
' --'
+
key
+
'='
+
value
)
localIP
=
socket
.
gethostbyname
(
socket
.
gethostname
())
trainerId
=
idMap
[
localIP
]
args
+=
" "
+
args_ext
+
" --trainer_id="
+
\
str
(
trainerId
)
+
" --save_dir="
+
JOB_PATH_OUTPUT
```
doc/howto/usage/k8s/src/k8s-paddle-arch.png
查看替换文件 @
c444708a
浏览文件 @
60e0df0e
21.6 KB
|
W:
|
H:
518.1 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}