Choose a region which has the following services available: EC2, EFS, VPS, CloudFormation, KMS, VPC, S3.
In this tutorial, we use "Oregon(us-west-2)" as example.
## Create AWS Account and IAM Account
## Distributed PaddlePaddle Training Core Concepts
### Distributed Training Job
A distributed training job is represented by a [Kubernetes job](https://kubernetes.io/docs/user-guide/jobs/#what-is-a-job).
Each Kuberentes job is described by a job config file, which specifies the information like the number of [pods](https://kubernetes.io/docs/user-guide/pods/#what-is-a-pod) in the job and environment variables.
In a distributed training job, we would:
1. prepare partitioned training data and configuration file on a distributed file system (in this tutorial we use Amazon Elastic File System), and
1. create and submit the Kubernetes job config to the Kubernetes cluster to start the training job.
### Parameter Servers and Trainers
There are two roles in a PaddlePaddle cluster: *parameter server (pserver)* and *trainer*. Each parameter server process maintains a shard of the global model. Each trainer has its local copy of the model, and uses its local data to update the model. During the training process, trainers send model updates to parameter servers, parameter servers are responsible for aggregating these updates, so that trainers can synchronize their local copy with the global model.
<center></center>
In order to communicate with pserver, trainer needs to know the ip address of each pserver. In kubernetes it's better to use a service discovery mechanism (e.g., DNS hostname) rather than static ip address, since any pserver's pod may be killed and a new pod could be schduled onto another node of different ip address. However, now we are using static ip. This will be improved.
Parameter server and trainer are packaged into a same docker image. They will run once pod is scheduled by kubernetes job.
### Trainer ID
Each trainer process requires a trainer ID, a zero-based index value, passed in as a command-line parameter. The trainer process thus reads the data partition indexed by this ID.
### Training
The entry-point of a container is a shell script. It can see some environment variables pre-defined by Kubernetes. This includes one that gives the job's identity, which can be used in a remote call to the Kubernetes apiserver that lists all pods in the job.
We rank each pod by sorting them by their ips. The rank of each pod could be the "pod ID". Because we run one trainer and one parameter server in each pod, we can use this "pod ID" as the trainer ID. A detailed workflow of the entry-point script is as follows:
1. Query the api server to get pod information, and assign the `trainer_id` by sorting the ip.
1. Copy the training data from EFS persistent volume into container.
1. Parse the `paddle pserver` and `paddle trainer` startup parameters from environment variables, and then start up the processes.
1. Trainer with `train_id` 0 will automatically write results onto EFS volume.
## PaddlePaddle on AWS with Kubernetes
### Create AWS Account and IAM Account
Under each AWS account, we can create multiple [IAM](http://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html) users. This allows us to grant some privileges to each IAM user and to create/operate AWS clusters as an IAM user.
...
...
@@ -30,11 +75,6 @@ Please be aware that this tutorial needs the following privileges for the user i
- AWSKeyManagementServicePowerUser
## PaddlePaddle on AWS
Here we will show you step by step on how to run PaddlePaddle training on AWS cluster.
### Download kube-aws and kubectl
#### kube-aws
...
...
@@ -109,7 +149,6 @@ And then configure your AWS account information:
```
aws configure
```
...
...
@@ -119,7 +158,7 @@ Fill in the required fields:
```
AWS Access Key ID: YOUR_ACCESS_KEY_ID
AWS Secrete Access Key: YOUR_SECRETE_ACCESS_KEY
Default region name: us-west-1
Default region name: us-west-2
Default output format: json
```
...
...
@@ -137,25 +176,28 @@ aws ec2 describe-instances
The keypair that will authenticate SSH access to your EC2 instances. The public half of this key pair will be configured on each CoreOS node.
Follow [EC2 Keypair docs](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html) to create a EC2 key pair
Follow [EC2 Keypair User Guide](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html) to create a EC2 key pair
After creating a key pair, you will use the key pair name to configure the cluster.
Key pairs are only available to EC2 instances in the same region. We are using us-west-1 in our tutorial, so make sure to creat key pairs in that region (N. California).
Key pairs are only available to EC2 instances in the same region. We are using us-west-2 in our tutorial, so make sure to creat key pairs in that region (Oregon).
Your browser will download a `key-name.pem` file which is the key to access the EC2 instances. We will use it later.
#### KMS key
Amazon KMS keys are used to encrypt and decrypt cluster TLS assets. If you already have a KMS Key that you would like to use, you can skip creating a new key and provide the Arn string for your existing key.
You can create a KMS key in the AWS console, or with the aws command line tool:
You can create a KMS key with the aws command line tool:
And then you need to add several inline policies in your user permission.
And then let's add several inline policies in your IAM user permission.
Go to IAM user page, click on `Add inline policy` button, and then select `Custom Policy`
Go to [IAM Console](https://console.aws.amazon.com/iam/home?region=us-west-2#/home). Click on button `Users`, click user that we just created, and then click on `Add inline policy` button, and select `Custom Policy`.
paste into following inline policies:
Paste into following inline policies:
```
{
(Caution: node_0, node_1, node_2 directories represents PaddlePaddle node and train_id, not the Kubernetes node){
"Version": "2012-10-17",
"Statement": [
{
...
...
@@ -201,7 +243,7 @@ paste into following inline policies:
@@ -221,20 +263,23 @@ Please note, stack name must satisfy regular expression pattern: [a-zA-Z][-a-zA-
When the cluster is created, the controller will expose the TLS-secured API on a DNS name.
The A record of that DNS name needs to be point to the cluster ip address.
DNS name should have a CNAME points to cluster DNS name or an A record points to the cluster IP address.
We will need to use DNS name later in tutorial. If you don't already own one, you can choose any DNS name (e.g., `paddle`) and modify `/etc/hosts` to associate cluster ip with that DNS name. We will find the ip to map to `paddle` in later steps. Also in this case, will have to add name service (route53) in aws cluster in later step.
=======
We will need to use DNS name later in tutorial.
#### S3 bucket
You need to create an S3 bucket before startup the Kubernetes cluster.
There are some bugs in aws cli in creating S3 bucket, so let's use the [Web console](https://console.aws.amazon.com/s3/home?region=us-west-1).
There are some bugs in aws cli in creating S3 bucket, so let's use the [S3 Console](https://console.aws.amazon.com/s3/home?region=us-west-2).
Click on `Create Bucket`, fill in a unique BUCKET_NAME, and make sure region is us-west-1 (Northern California).
Click on `Create Bucket`, fill in a unique BUCKET_NAME, and make sure region is us-west-2 (Oregon).
#### Initialize an asset directory
#### Initialize Assets
Create a directory on your local machine to hold the generated assets:
...
...
@@ -249,10 +294,10 @@ Initialize the cluster CloudFormation stack with the KMS Arn, key pair name, and
`MY_CLUSTER_NAME`: the one you picked in [KMS key](#kms-key)
...
...
@@ -263,14 +308,15 @@ kube-aws init \
`--kms-key-arn`: the "Arn" in [KMS key](#kms-key)
Here `us-west-1a` is used for parameter `--availability-zone`, but supported availability zone varies among AWS accounts.
Here `us-west-2a` is used for parameter `--availability-zone`, but supported availability zone varies among AWS accounts.
Please check if `us-west-1a` is supported by `aws ec2 --region us-west-1 describe-availability-zones`, if not switch to other supported availability zone. (e.g., `us-west-1a`, or `us-west-1b`)
Please check if `us-west-2a` is supported by `aws ec2 --region us-west-2 describe-availability-zones`, if not switch to other supported availability zone. (e.g., `us-west-2a`, or `us-west-2b`)
Note: please don't use `us-west-1c`. Subnets can currently only be created in the following availability zones: us-west-1b, us-west-1a.
There will now be a cluster.yaml file in the asset directory. This is the main configuration file for your cluster.
By default `kube-aws` will only create one worker node. Let's edit `cluster.yaml` and change `workerCount` from 1 to 3.
#### Render contents of the asset directory
...
...
@@ -285,41 +331,14 @@ The next command generates the default set of cluster assets in your asset direc
```
kube-aws render stack
```
Here's what the directory structure looks like:
```
$ tree
.
├── cluster.yaml
├── credentials
│ ├── admin-key.pem
│ ├── admin.pem
│ ├── apiserver-key.pem
│ ├── apiserver.pem
│ ├── ca-key.pem
│ ├── ca.pem
│ ├── worker-key.pem
│ └── worker.pem
│ ├── etcd-key.pem
│ └── etcd.pem
│ ├── etcd-client-key.pem
│ └── etcd-client.pem
├── kubeconfig
├── stack-template.json
└── userdata
├── cloud-config-controller
└── cloud-config-worker
```
These assets (templates and credentials) are used to create, update and interact with your Kubernetes cluster.
Assets (templates and credentials) that are used to create, update and interact with your Kubernetes cluster will be created under your current folder.
### Kubernetes Cluster Start Up
#### Create the instances defined in the CloudFormation template
Now let's create your cluster (choose any PREFIX for the command below):
Now let's create your cluster (choose any `PREFIX` for the command below):
```
kube-aws up --s3-uri s3://BUCKET_NAME/PREFIX
...
...
@@ -335,20 +354,24 @@ You can invoke `kube-aws status` to get the cluster API endpoint after cluster c
```
$ kube-aws status
Cluster Name: paddle-cluster
Controller DNS Name: paddle-cl-ElbAPISe-EEOI3EZPR86C-531251350.us-west-1.elb.amazonaws.com
Controller DNS Name: paddle-cl-ElbAPISe-EEOI3EZPR86C-531251350.us-west-2.elb.amazonaws.com
```
If you own a DNS name, set the A record to any of the above ip. __Or__ you can set up CNAME point to `Controller DNS Name` (`paddle-cl-ElbAPISe-EEOI3EZPR86C-531251350.us-west-2.elb.amazonaws.com`)
##### Find IP address
Use command `dig` to check the load balancer hostname to get the ip address.
Training data is usually served on a distributed filesystem, we use Elastic File System (EFS) on AWS. Ceph might be a better solution, but it requires high version of Linux kernel that might not be stable enough at this moment. We haven't automated the EFS setup at this moment, so please do the following steps:
Training data is usually served on a distributed filesystem, we use Elastic File System (EFS) on AWS.
1. Make sure you added AmazonElasticFileSystemFullAccess policy in your group.
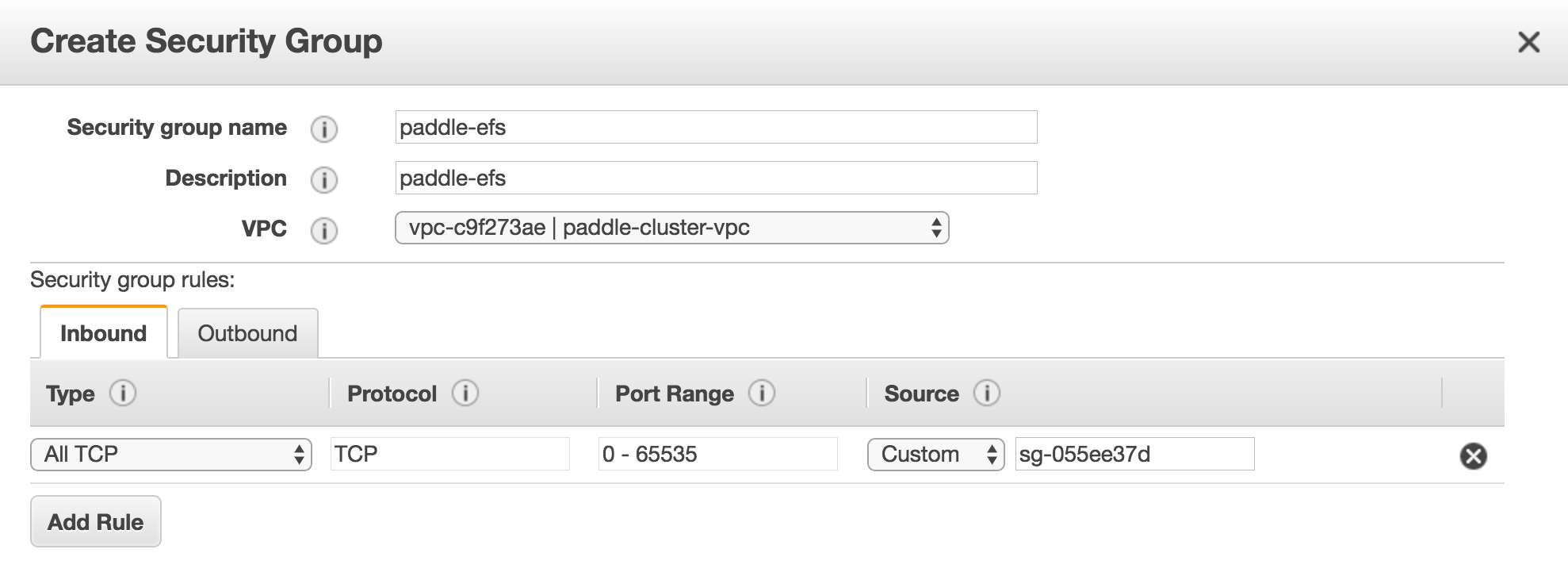
1. Create security group for EFS in [security group console](https://us-west-2.console.aws.amazon.com/ec2/v2/home?region=us-west-2#SecurityGroups:sort=groupId)
1. Look up security group id for `paddle-cluster-sg-worker` (`sg-055ee37d` in the image below)
2. Add security group `paddle-efs` with `ALL TCP` inbound rule and custom source as group id of `paddle-cluster-sg-worker`. And VPC of `paddle-cluster-vpc`. Make sure availability zone is same as the one you used in [Initialize Assets](#initialize-assets).
<center></center>
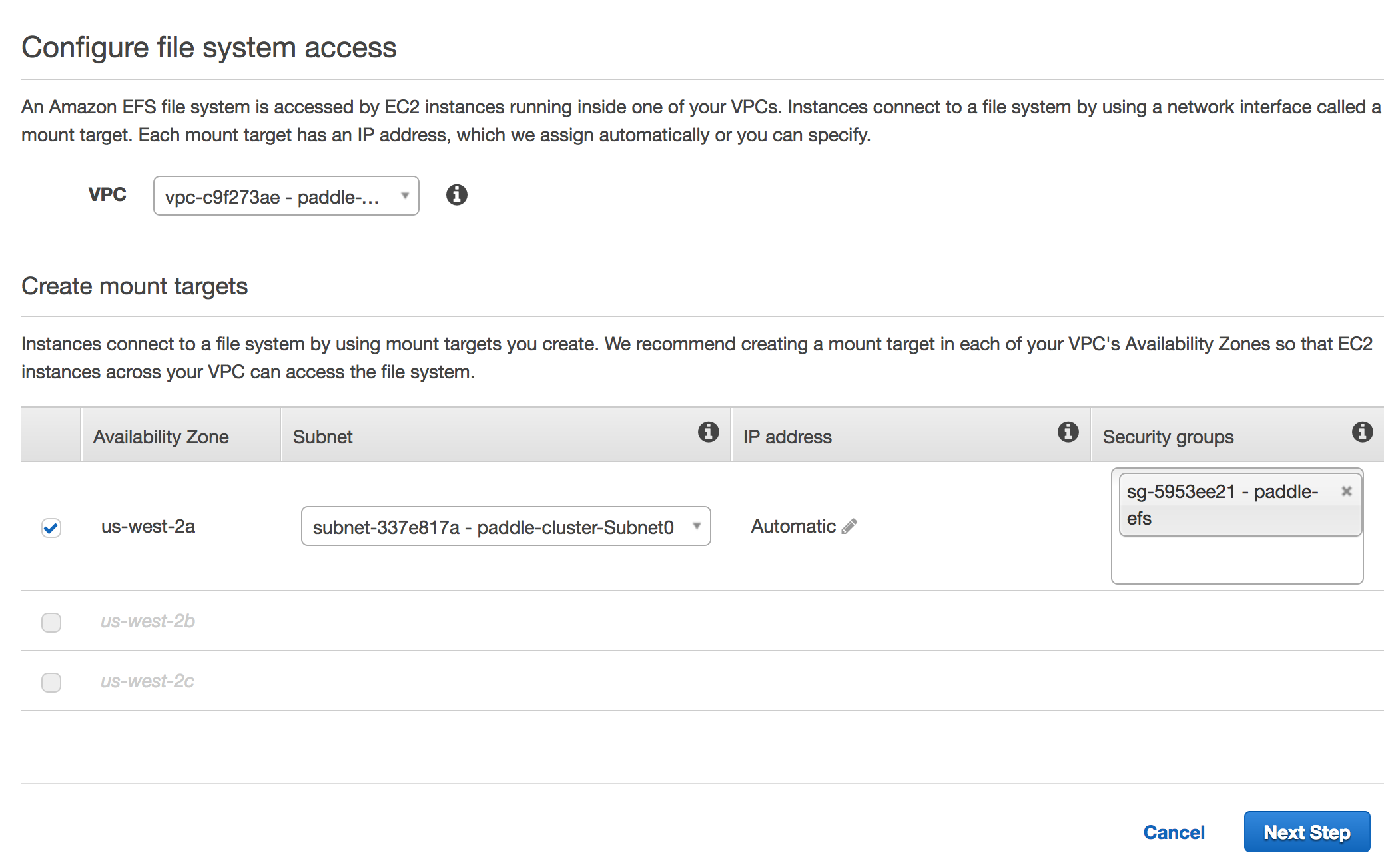
1. Create the Elastic File System in AWS console, and attach the new VPC with it.
2. Create the Elastic File System in [EFS console](https://us-west-2.console.aws.amazon.com/efs/home?region=us-west-2#/wizard/1) with `paddle-cluster-vpc` VPC. Make sure subnet is `paddle-cluster-Subnet0` andd security group is `paddle-efs`.
<center></center>
1. Modify the Kubernetes security group under ec2/Security Groups, add additional inbound policy "All TCP TCP 0 - 65535 0.0.0.0/0" for Kubernetes default VPC security group.
<center></center>
1. Follow the EC2 mount instruction to mount the disk onto all the Kubernetes nodes, we recommend to mount EFS disk onto ~/efs.
<center></center>
We will place user config and divided training data onto EFS. Training task will cache related files by copying them from EFS into container. It will also write the training results back onto EFS. We will show you how to place the data later in this article.
### Core Concepts of PaddlePaddle Training on AWS
Now we've already setup a 3 nodes distributed Kubernetes cluster, and on each node we've attached the EFS volume. In this training demo, we will create three Kubernetes pods and schedule them on three nodes. Each pod contains a PaddlePaddle container. When container gets created, it will start parameter server (pserver) and trainer process, load the training data from EFS volume and start the distributed training task.
#### Distributed Training Job
A distributed training job is represented by a [kubernetes job](https://kubernetes.io/docs/user-guide/jobs/#what-is-a-job).
Each Kuberentes job is described by a job config file, which specifies the information like the number of pods in the job and environment variables.
In a distributed training job, we would:
1. upload the partitioned training data and configuration file onto EFS volume, and
1. create and submit the Kubernetes job config to the Kubernetes cluster to start the training job.
#### Parameter Servers and Trainers
There are two roles in a PaddlePaddle cluster: `parameter server` and `trainer`. Each parameter server process maintains a shard of the global model. Each trainer has its local copy of the model, and uses its local data to update the model. During the training process, trainers send model updates to parameter servers, parameter servers are responsible for aggregating these updates, so that trainers can synchronize their local copy with the global model.
<center></center>
In order to communicate with pserver, trainer needs to know the ip address of each pserver. In kubernetes it's better to use a service discovery mechanism (e.g., DNS hostname) rather than static ip address, since any pserver's pod may be killed and a new pod could be schduled onto another node of different ip address. We will improve paddlepaddle's service discovery ability. For now we will use static ip.
Parameter server and trainer are packaged into a same docker image. They will run once pod is scheduled by kubernetes job.
#### Trainer ID
Each trainer process requires a trainer ID, a zero-based index value, passed in as a command-line parameter. The trainer process thus reads the data partition indexed by this ID.
#### Training
The entry-point of a container is a Python script. As it runs in a pod, it can see some environment variables pre-defined by Kubernetes. This includes one that gives the job's identity, which can be used in a remote call to the Kubernetes apiserver that lists all pods in the job.
We rank each pod by sorting them by their ips. The rank of each pod could be the "pod ID". Because we run one trainer and one parameter server in each pod, we can use this "pod ID" as the trainer ID. A detailed workflow of the entry-point script is as follows:
1. Query the api server to get pod information, and assign the `trainer_id` by sorting the ip.
1. Copy the training data from EFS sharing volume into container.
1. Parse the `paddle pserver` and `paddle trainer` startup parameters from environment variables, and then start up the processes.
1. Trainer with `train_id` 0 will automatically write results onto EFS volume.
### Start PaddlePaddle Training Demo on AWS
Now we'll start a PaddlePaddle training demo on AWS, steps are as follows:
1. Build PaddlePaddle Docker image.
1. Divide the training data file and upload it onto the EFS sharing volume.
1. Create the training job config file, and start up the job.
1. Check the result after training.
#### Build PaddlePaddle Docker Image
PaddlePaddle docker image need to provide the runtime environment for `pserver` and `trainer`, so the container use this image should have two main function:
1. Copy the training data into container.
1. Generate the startup parameter for `pserver` and `trainer` process, and startup the training.
#### Configure Kubernetes Volume that Points to EFS
First we need to create a [PersistentVolume](https://kubernetes.io/docs/user-guide/persistent-volumes/) to provision EFS volumn.
We need to create a new image since official `paddledev/paddle:cpu-latest` only have PaddlePaddle binary, but lack of the above functionalities.
Dockerfile for creating the new image is as follows:
Save following snippet as `pv.yaml`
```
FROM paddledev/paddle:cpu-latest
MAINTAINER zjsxzong89@gmail.com
COPY start.sh /root/
COPY start_paddle.py /root/
CMD ["bash"," -c","/root/start.sh"]
apiVersion: v1
kind: PersistentVolume
metadata:
name: efsvol
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteMany
nfs:
server: EFS_DNS_NAME
path: "/"
```
At this point, we will copy our `start.sh` and `start_paddle.py` file into container, and then exec `start_paddle.py` script to start up the training, all the steps like assigning trainer_id, getting other nodes' ip are implemented in `start_paddle.py`.
`start_paddle.py` will start parsing the parameters.
`EFS_DNS_NAME`: DNS name as shown in description of `paddle-efs` that we created. Looks similar to `fs-2cbf7385.efs.us-west-2.amazonaws.com`
Run following command to create a persistent volumn:
And then using function `getPodList()` to query all the pod information from the job name through Kubernetes api server. When all the pods are in the running status, using `getIdMap(podlist)` to get the trainer_id.
Next let's create a [PersistentVolumeClaim](https://kubernetes.io/docs/user-guide/persistent-volumes/) to claim the persistent volume.
Save following snippet as `pvc.yaml`.
```
podlist = getPodList()
# need to wait until all pods are running
while not isPodAllRunning(podlist):
time.sleep(10)
podlist = getPodList()
idMap = getIdMap(podlist)
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: efsvol
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
```
In function `getIdMap(podlist)`, we use podlist to get the ip address for each pod and sort them, use the index as the trainer_id.
Run following command to create a persistent volumn claim:
After getting `idMap`, we use function `startPaddle(idMap, train_args_dict)` to generate `paddle pserver` and `paddle train` start up parameters and then start up the processes.
In function `startPaddle`, the most important work is to generate `paddle pserver` and `paddle train` start up parameters. For example, `paddle train` parameter parsing, we will get parameters like `PADDLE_NIC`, `PADDLE_PORT`, `PADDLE_PORTS_NUM`, and get the `trainer_id` from `idMap`.
Here we will use PaddlePaddle's official recommendation demo as the content for this training, we put the training data file into a directory named by job name, which located in EFS sharing volume, the tree structure for the directory looks like:
Job may take 7 min to finish, use following command to check job status. Do not proceed until `SUCCESSFUL` for `paddle-data` job is `1`
```
efs
└── paddle-cluster-job
├── data
│ ├── 0
│ │
│ ├── 1
│ │
│ └── 2
├── output
└── recommendation
$ kubectl --kubeconfig=kubeconfig get jobs
NAME DESIRED SUCCESSFUL AGE
paddle-data 1 1 6m
```
The `paddle-cluster-job` directory is the job name for this training, this training includes 3 PaddlePaddle node, we store the partitioned data under `paddle-cluster-job/data` directory, directory 0, 1, 2 each represent 3 nodes' trainer_id. the training data in in recommendation directory, the training results and logs will be in the output directory.
#### Create Kubernetes Job
Kubernetes use yaml file to describe job details, and then use command line tool to create the job in Kubernetes cluster.
In yaml file, we describe the Docker image we use for this training, the node number we need to startup, the volume mounting information and all the necessary parameters we need for `paddle pserver` and `paddle train` processes.
Data preparation is done by docker image `paddledev/paddle-tutorial:k8s_data`, see [here](src/k8s_data/README.md) for how to build this docker image and source code.
The yaml file content is as follows:
#### Start Training
Now we are ready to start paddle training job. Save following snippet as `paddle-cluster-job.yaml`
```
apiVersion: batch/v1
kind: Job
...
...
@@ -601,12 +539,12 @@ spec:
name: paddle-cluster-job
spec:
volumes:
- name: jobpath
hostPath:
path: /home/admin/efs
- name: efs
persistentVolumeClaim:
claimName: efsvol
containers:
- name: trainer
image: drinkcode/paddle:k8s-job
image: paddledev/paddle-tutorial:k8s_train
command: ["bin/bash", "-c", "/root/start.sh"]
env:
- name: JOB_NAME
...
...
@@ -616,7 +554,7 @@ spec:
- name: JOB_NAMESPACE
value: default
- name: TRAIN_CONFIG_DIR
value: recommendation
value: quick_start
- name: CONF_PADDLE_NIC
value: eth0
- name: CONF_PADDLE_PORT
...
...
@@ -627,106 +565,124 @@ spec:
value: "2"
- name: CONF_PADDLE_GRADIENT_NUM
value: "3"
- name: TRAINER_COUNT
value: "3"
volumeMounts:
- name: jobpath
mountPath: /home/jobpath
- mountPath: "/home/jobpath"
name: efs
ports:
- name: jobport
hostPort: 30001
containerPort: 30001
- name: jobport0
hostPort: 7164
containerPort: 7164
- name: jobport1
hostPort: 7165
containerPort: 7165
- name: jobport2
hostPort: 7166
containerPort: 7166
- name: jobport3
hostPort: 7167
containerPort: 7167
restartPolicy: Never
```
In yaml file, the metadata's name is the job's name. `parallelism, completions` means this job will simultaneously start up 3 PaddlePaddle nodes, and this job will be finished when there are 3 finished pods. For the data store volume, we declare the path jobpath, it mount the /home/admin/efs on host machine into the container with path /home/jobpath. So in container, the /home/jobpath actually stores the data onto EFS sharing volume.
`env` field represents container's environment variables, we pass the PaddlePaddle parameters into containers by using the `env` field.
`parallelism: 3, completions: 3` means this job will simultaneously start 3 PaddlePaddle pods, and this job will be finished when there are 3 finished pods.
`JOB_PATH` represents the sharing volume path, `JOB_NAME` represents job name, `TRAIN_CONFIG_DIR` represents the training data file directory, we can these three parameters to get the file path for this training.
`env` field represents container's environment variables, we specify PaddlePaddle parameters by environment variables.
`CONF_PADDLE_NIC` represents `paddle pserver` process's `--nics` parameters, the NIC name.
`ports` indicates that TCP port 7164 - 7167 are exposed for communication between `pserver` ans trainer. port starts continously from `CONF_PADDLE_PORT` (7164) to `CONF_PADDLE_PORT + CONF_PADDLE_PORTS_NUM + CONF_PADDLE_PORTS_NUM_SPARSE - 1` (7167). We use multiple ports for dense and sparse paramter updates to improve latency.
`CONF_PADDLE_GRADIENT_NUM` represents the training node number, `--num_gradient_servers` parameter.
Inspect individual pods
After we create the yaml file, we can use Kubernetes command line tool to create the job onto the cluster.
```
$ kubectl --kubeconfig=kubeconfig get pods
NAME READY STATUS RESTARTS AGE
paddle-cluster-job-cm469 1/1 Running 0 9m
paddle-cluster-job-fnt03 1/1 Running 0 9m
paddle-cluster-job-jx4xr 1/1 Running 0 9m
```
Inspect individual console output
```
kubectl create -f job.yaml
kubectl --kubeconfig=kubeconfig log -f POD_NAME
```
After we execute the above command, Kubernetes will create 3 pods and then pull the PaddlePaddle image, then start up the containers for training.
`POD_NAME`: name of any pod (e.g., `paddle-cluster-job-cm469`).
Run `kubectl --kubeconfig=kubeconfig describe job paddle-cluster-job` to check training job status. It will complete in around 20 minutes.
The details for start `pserver` and `trainer` are hidden inside docker image `paddledev/paddle-tutorial:k8s_train`, see [here](src/k8s_train/README.md) for how to build the docker image and source code.
#### Check Training Results
#### Inspect Training Output
During the training, we can see the logs and models on EFS sharing volume, the output directory contains the training results. (Caution: node_0, node_1, node_2 directories represents PaddlePaddle node and train_id, not the Kubernetes node)
Training output (model snapshot and logs) will be saved in EFS. We can ssh into worker EC2 instance, mount EFS and check training output.
1. ssh Into Worker EC2 instance
```
[root@paddle-kubernetes-node0 output]# tree -d
.
├── node_0
│ ├── server.log
│ └── train.log
├── node_1
│ ├── server.log
│ └── train.log
├── node_2
......
├── pass-00002
│ ├── done
│ ├── ___embedding_0__.w0
│ ├── ___embedding_1__.w0
......
chmod 400 key-name.pem
ssh -i key-name.pem core@INSTANCE_IP
```
We can always check the container training status through logs, for example:
`INSTANCE_IP`: public IP address of EC2 kubernetes worker node. Go to [EC2 console](https://us-west-2.console.aws.amazon.com/ec2/v2/home?region=us-west-2#Instances:sort=instanceId) and check `public IP` of any `paddle-cluster-kube-aws-worker` instance.
sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 EFS_DNS_NAME:/ efs
```
It'll take around 8 hours to finish this PaddlePaddle recommendation training demo on three 2 core 8 GB EC2 machine (m3.large).
`EFS_DNS_NAME`: DNS name as shown in description of `paddle-efs` that we created. Look similar to `fs-2cbf7385.efs.us-west-2.amazonaws.com`.
Now folder `efs` will have structure similar to:
```
-- paddle-cluster-job
|-- ...
|-- output
| |-- node_0
| | |-- server.log
| | `-- train.log
| |-- node_1
| | |-- server.log
| | `-- train.log
| |-- node_2
| | |-- server.log
| | `-- train.log
| |-- pass-00000
| | |-- ___fc_layer_0__.w0
| | |-- ___fc_layer_0__.wbias
| | |-- done
| | |-- path.txt
| | `-- trainer_config.lr.py
| |-- pass-00001...
```
`server.log` contains log for `pserver`. `train.log` contains log for `trainer`. Model description and snapshot is stored in `pass-0000*`.
### Kubernetes Cluster Tear Down
#### Delete EFS
Go to [EFS Console](https://us-west-2.console.aws.amazon.com/efs/home?region=us-west-2) and delete the EFS volumn that we created.
#### Delete security group
Go to [Security Group Console](https://us-west-2.console.aws.amazon.com/ec2/v2/home?region=us-west-2#SecurityGroups:sort=groupId) and delete security group `paddle-efs`.
If you want to tear down the whole Kubernetes cluster, make sure to *delete* the EFS volume first (otherwise, you will get stucked on following steps), and then use the following command:
#### Delete S3 Bucket
Go to [S3 Console](https://console.aws.amazon.com/s3/home?region=us-west-2#) and delete the S3 bucket that we created.
#### Destroy Cluster
```
kube-aws destroy
```
It's an async call, it might take 5 min to tear down the whole cluster.
If you created any Kubernetes Services of type LoadBalancer, you must delete these first, as the CloudFormation cannot be fully destroyed if any externally-managed resources still exist.
The command will return immediately, but it might take 5 min to tear down the whole cluster.
You can go to [CludFormation Console](https://us-west-2.console.aws.amazon.com/cloudformation/home?region=us-west-2#/stacks?filter=active) to check destroy process.
To build PaddlePaddle data preparation image in tutorial [Distributed PaddlePaddle Training on AWS with Kubernetes](../../k8s_aws_en.md), run following commands:
To build PaddlePaddle training image in tutorial [Distributed PaddlePaddle Training on AWS with Kubernetes](../../k8s_aws_en.md), run following command:
{kind=link}
{kind=link}

{kind=link}
{kind=link}

{kind=link}
