Spring Cloud

软件开发架构的演变过程
-
单体架构
把所有功能模块打到一个包里面然后再部署,采用了单体架构的项目被称为单体应用。
优点: 开发、测试、部署比较简单。
缺点: ①项目复杂度高、代码耦合度高、维护困难,修改一处可能影响多处功能;②可靠性差,可能因为某个功能模块的严重BUG导致整个系统不可用;③单体应用只能作为一个整体进行扩展,无法根据业务模块的需要进行伸缩,例如有的模块是计算密集型的需要强劲的CPU、有的模块是IO密集型的需要大内存,如果任何一个模块存在问题都要考虑部署几个完整实例集群,才能保证整个系统的性能可以支撑用户的使用。
-
分布式架构
将一个大系统按照不同的功能模块进行垂直拆分,拆分成一个一个的子系统,每个子系统都是独立的,系统之间通过网络交互来完成用户的业务处理,而且每个子系统可以分布式部署,这种架构称为分布式架构。
优点: 大系统拆为一个个小系统,使每个小系统功能相对简单,开发、测试周期相应缩短。子系统可根据需要灵活扩展。
缺点: 因系统之间相互独立,会有很多重复开发工作,影响开发效率。
-
SOA架构
在分布式架构的思想基础上,将重复功能抽取出来作为一个个服务,子系统再去通过ESB企业总线调用这些公共服务。
优点: 将基础服务进行了抽取,系统间相互调用,提高了代码的复用率和开发效率,可针对不同服务的特点进行按需伸缩。
缺点: 系统与服务之间耦合性高。
-
微服务架构
微服务的核心思想就是分而治之,也就是说将传统的单体应用,根据业务拆分成一个个的服务,彻底的去耦合,每一个微服务只提供单个业务功能的服务,比如说订单微服务只实现订单相关业务、会员微服务只实现会员相关业务,服务之间相互协作来完成用户的业务处理,每个微服务都运行在自己的进程里并且拥有独立的数据库。
优点: 首先服务拆分力度更细,提高复用率,提高开发效率。微服务间松耦合,开发部署都是独立的。可根据服务按需伸缩。
缺点: 增加开发复杂度、增大了通信成本;服务治理成本变高,不利于系统维护,测试、调试困难。
集群、分布式、微服务
集群:多台服务器集中在一起,每台服务器都实现相同的功能,做相同的事情。
但是每台服务器并不是缺一不可,存在的作用是缓解并发压力和单点故障转移问题。我们可以用一些廉价的符合工业标准的硬件构造高扩展、高性能、低成本、高可用的系统。
集群主要具有的特性:伸缩性(Scalability)、高可用性(High availability)、负载均衡(Load balancing)、高性能(High Performance)。
分布式:分布式服务是指多台服务器集中在一起,服务是分散部署在不同的机器上的。
每台服务器都实现总体中的不同业务,做不同的事情。一个服务可能负责几个功能,是一种面向 SOA(Service-Oriented Architecture) 的架构。各分开部署的部分彼此通过各种通信协议交互,并且每台服务器缺一不可,如果某台服务器故障,则会导致部分功能丢失不可用,或导致整体无法运行。
分布式主要作用是大幅提高效率,缓解服务器访问和存储压力。区别分布式的方式时一个业务拆分成多个子业务部署在不同的服务器上。
微服务:微服务是很小的服务,小到一个服务只对应单一功能。
只关注一个任务并能很好的完成该任务,可单独部署运行。各服务之间松耦合,服务间可以通过RPC调用。每个微服务可由独立小团队进行开发、测试、部署、上线,负责它的整个生命周期。
区别?
集群和分布式:①部署多台服务器的业务是否相同,集群模式不同的服务器部署同一套服务对外提供访问,实现服务的负载均衡,分布式其中的每一个节点都可以做集群,而集群不一定就是分布式。②提升效率的方式不同,分布式是缩短单个任务的执行时间来提升效率的,集群是通过提高单位时间内执行的任务数来提升效率的。
注:集群模式需要做好 Session 共享,确保在不同服务器切换的过程中不会因为没有获取到 Session 而引起服务终止。 分布式需要做好事务管理。
分布式和微服务:架构很相似,只是部署方式不一样。
微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。 系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。微服务的应用不一定是分散在多个服务器上,它也可以是同一个服务器。
微服务相比分布式服务来说,它的粒度更小,服务之间耦合度更低。由于每个微服务都由独立的小团队负责,因此它敏捷性更高。分布式服务最后都会向微服务架构演化,这是一种趋势。不过服务微服务化后带来的挑战也是显而易见的,例如服务粒度小,数量大,后期运维难度会增大。
分布式属于微服务。微服务将模块拆分成一个独立的服务单元通过接口来实现数据的交互。生产环境下的微服务肯定是分布式部署的,分布式部署的应用不一定是微服务架构的。
总结
集群:复制部署,能力一致,目的是实现:伸缩性、高可用、负载均衡和高性能; 微服务:分散能力,将大型复杂的软件拆分为多个微服务组成(不一定分散在多个服务器,可以是同一个服务器); 分布式:分散部署,是一种面向 SOA 的架构,服务分散部署在不同的机器上,实现不同业务,做不同的事情。
一、Eureka服务注册与发现
微服务架构中充当注册中心的角色,方便管理各种微服务。它分为 Eureka Server 和 Eureka Client 。每个微服务都有 Eureka Server 专门负责将该服务的信息注册到 Eureka Server 。而 Eureka Server 服务端维护了注册表,保存了各个服务所在机器和端口号,服务之间进行调用的时候消费者从 Eureka Server 拉取要调用的服务的IP、端口号相关信息到本地缓存起来,之后发送请求调用相应服务接口。
1. Eureka的心跳机制
Eureka Clinet 每隔 30秒 会向 Eureka Server 发送一次心跳,如果 Eureka Server 在90秒后还未收到某服务发来的心跳60秒 后对在这个时间段内死亡的服务集中注销,如果立即注销肯定会对 Eureka 造成极大负担,另外刚才说的这些时间参数都是可以认为配置的。
@ConfigurationProperties("eureka.instance")
public class EurekaInstanceConfigBean
implements CloudEurekaInstanceConfig, EnvironmentAware {
/**
* 指示eureka客户端需要向eureka服务器发送心跳的频率(以秒为单位),以表明它仍然处于活动状态。如
* 果在leaseExpirationDurationInSeconds中指定的时间段内未接收到心跳,eureka服务器将通过禁止
* 此实例的流量从其视图中删除该实例。请注意,如果该实例实现HealthCheckCallback,然后决定使其自身不可用,则它仍然无法获取流量。
*/
private int leaseRenewalIntervalInSeconds = 30;
}@ConfigurationProperties(EurekaServerConfigBean.PREFIX)
public class EurekaServerConfigBean implements EurekaServerConfig {
// 清理无效节点的间隔时间(单位毫秒)
private long evictionIntervalTimerInMs = 60 * 1000;
}2. Eureka的自我保护机制
Eureka 自我保护机制讲的是 15分钟 内一直都是超过 85% 的节点都没有正常的心跳,那么 Eureka Server 就认为客户端与注册中心出现了网络故障,就会自动进入自我保护模式。进入自我保护模式之后 Eureka Server 就不会再接收心跳,也不会删除任何服务。当网络故障恢复后,Eureka Server 也会自动退出自我保护模式。这就是 Eureka 的自我保护机制。

核心原理:实际收到的心跳数 < 最小心跳数 就会触发自我保护机制
- 期望心跳数: 与服务实例多少有关,
10个实例,30秒发一次(也就是续约),那么每分钟心跳数就是 10 * 2 = 20 (心跳)。 - 最小心跳数:期望心跳数 * 0.85
public abstract class AbstractInstanceRegistry implements InstanceRegistry {
// 服务端: 预期发送心跳续租的实例数 expectedClientRenewalIntervalSeconds = 30时 每节点1分钟发两次
protected volatile int numberOfRenewsPerMinThreshold;
// 服务端: 统计预期收到心跳续租的客户端实例数 期望心跳数
protected volatile int expectedNumberOfClientsSendingRenews;
}eureka Server 在启动时,会对以上变量进行初始化。它会从其他节点同步一下注册表,然后注册到自己本地注册表中,会返回一个同步数量 count ,后面注册表的这两个变量会根据 count 计算出来。
public class EurekaBootStrap implements ServletContextListener {
protected void initEurekaServerContext() throws Exception {
// Copy registry from neighboring eureka node
int registryCount = ((PeerAwareInstanceRegistry)registry).syncUp(); // 同步并返回注册表的节点数量
((PeerAwareInstanceRegistry)registry).openForTraffic(applicationInfoManager, registryCount);
}
}@Singleton
public class PeerAwareInstanceRegistryImpl extends AbstractInstanceRegistry implements PeerAwareInstanceRegistry {
@Override
public void openForTraffic(ApplicationInfoManager applicationInfoManager, int count) {
// Renewals happen every 30 seconds and for a minute it should be a factor of 2.
// 预期收到心跳续租的实例数赋值
this.expectedNumberOfClientsSendingRenews = count;
// 更新预期每分钟收到心跳续租请求数
updateRenewsPerMinThreshold();
}
}public abstract class AbstractInstanceRegistry implements InstanceRegistry {
// 最小心跳数(该分钟阈值) = 预期发送心跳续租的实例数 * (60.0 / 30) * 0.85
protected void updateRenewsPerMinThreshold() {
this.numberOfRenewsPerMinThreshold = (int) (this.expectedNumberOfClientsSendingRenews
* (60.0 / serverConfig.getExpectedClientRenewalIntervalSeconds())
* serverConfig.getRenewalPercentThreshold());
}
}@ConfigurationProperties(EurekaServerConfigBean.PREFIX)
public class EurekaServerConfigBean implements EurekaServerConfig {
private double renewalPercentThreshold = 0.85;
}
3. 具体怎么使用 Eureka 搭建注册中心
首先需要在 pom 文件中引入 Eureka Server 依赖,之后在启动类上加入 @EnableEurekaServer 注解证明该项目的作用是作为注册中心使用,并在对应的 application.properties 中指明 Eureka 注册中心地址,方便服务提供者和消费者对其进行访问, 为了保证注册中心高可用我们还搭建了集群,防止因单台 Eureka 导致的单点故障问题。
4. 服务怎么注册到 Eureka Server 中
首先在需要注册到 Eureka Server 的服务的 pom 中引入 Eureka Client 的依赖,然后再配置文件中配置服务名、Eureka Server的地址,最后在启动类上添加 @EnableEurekaClient 注解就行了。
5.怎么搭建 Eureka Server 集群
每台 Eureka Server 都要注册到其他几台 Eureka Server 中,他们之间会自动进行数据同步。服务在注册的时候要填写所有的 Eureka Server 的地址,当然只写其中一个 Eureka Server 也行,但是这样做有风险,万一写的这台 Eureka Server 整好挂了那服务注册就失败了,为了稳妥起见,最好把所有 Eureka Server 的地址都写上。
6. 为什么要使用注册中心
如果没有注册中心,消费者通过 ip 地址访问服务提供者,如果服务越来越多,调用也会越来越复杂,一旦服务提供者的 ip 发生变动,则所有用到的地方都需要进行改变,维护困难。若宕机,所有消费者也都会受到影响。通过注册中心可以让服务提供者注册进去,并且可以进行负载均衡从而达到提高并发的目的。消费者调用服务提供者的时候从注册中心获取地址列表缓存至本地,从中选择一个地址进行调用,后续的维护也会比较方便。
二、Zookeeper服务注册与发现
1. Zookeeper 是什么
Zookeeper 是一个开源的分布式协调服务/工具。它是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
Zookeeper 从设计模式角度来理解,是一个基于 观察者模式 设计的分布式服务管理框架,它 负责存储和管理大家都关心的数据, 然后接受观察者的注册, 一旦这些数据的状态发生变化,Zookeeper 就负责通知已经在 Zookeeper 上注册的那些观察者做出反应。
注:可以这样理解...Zookeeper = 文件系统 + 通知机制
2. Zookeeper 有哪些应用场景
A. 数据发布与订阅
将数据发布到Zookeeper节点上,供订阅者动态获取数据,实现配置的集中式管理和动态更新。例如全局配置信息、地址列表就非常适用 发布订阅常见场景配置中心,发布到zk一个或一系列节点上,供订阅者进行数据订阅,达到动态获取数据的目的。 配置信息特点:①数据量小的KV;②数据在运行时会动态变化;③集群机器共享,配置一致。 Zk 采用推拉结合的方式,推:服务端会推给注册了监控节点的客户端Watch事件;拉:客户端获得通知主动拉取服务端最新数据。

B. 命名服务
作为分布式命名服务,命名服务是指通过名字获取资源或服务的地址,利用 Zookeeper 创建一个全局路径,这个路径就可以作为一个名字,指向集群中的节点、提供服务的地址、或者一个远程的对象等等。
B1. 在分布式环境下,经常要对 应用/服务 进行统一命名,便于识别不同服务。 类似于域名和IP之间的对应关系,IP不容易记住而域名容易记住。通过名称获取资源或服务地址,提供者等信息。
B2. 按照层次结构组织 服务/应用 名称。 可将服务名称以及地址信息写到 Zookeeper ,客户端通过Zookeeper获取可用服务列表。

C. 集群管理
所谓集群管理就是:是否有机器退出和加入、选举master。 集群管理主要指集群监控和集群控制两个方面。前者侧重于集群运行时的状态的收集,后者则是对集群进行操作与控制。开发和运维中,面对集群,经常有如下需求: ①希望知道集群中究竟有多少机器在工作;②对集群中的每台机器的运行时状态进行数据收集;③对集群中机器进行上下线的操作。

D. 分布式协调和通知
- 分布式环境中,经常存在一个服务需要知道它所管理的子服务的状态。
- NameNode需知道各个Datanode的状态。
- JobTracker需知道各个TaskTracker的状态。
- 心跳检测机制可通过
ZooKeeper来实现。 - 信息推送可由
ZooKeeper来实现,ZooKeeper相当于一个发布/订阅系统。
E. 分布式锁
处于不同节点上不同的服务,它们可能需要顺序的访问一些资源,这里需要一把分布式锁 (写锁、读锁、时序锁)。
写锁:在zk上创建的一个临时的无编号的节点。由于是无序编号,在创建时不会自动编号,导致只
能客户端有一个客户端得到锁,然后进行写入。
读锁:在zk上创建一个临时的有编号的节点,这样即使下次有客户端加入是同时创建相同的节点
时,他也会自动编号,也可以获得锁对象,然后对其进行读取。
时序锁:在zk上创建的一个临时的有编号的节点根据编号的大小控制锁。
F. 分布式队列
分布式队列分为两种
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 一个job由多个task组成,只有所有任务完成后,job才运行完成。
- 可为job创建一个/job目录,然后在该目录下,为每个完成的task创建一个临时的Znode,一旦临时节点数目达到task总数,则表明job运行完成。
- 队列按照
FIFO方式进行入队和出队操作,例如实现生产者和消费者模型。
3. Zookeeper 的工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个 Server 之间的同步。实现这个机制的协议叫做 Zab协议 。Zab协议 有两种模式( 恢复模式[选主],广播模式[同步] )。Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。Zookeeper 是通过 Zab协议 来保证分布式事务的最终一致性。Zab协议 要求每个 Leader 都要经历三个阶段:发现、同步、广播。
当服务启动或在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 Server 完成了和 Leader 的状态同步以后,恢复模式就结束了。状态同步保证了 Leader 和 Server 具有相同的系统状态。为了保证事务的顺序一致性,Zookeeper 采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加 上了 zxid 。实现中 zxid 是一个64位的数字,它高32位是epoch用来标识 Leader 关系是否改变,每次一个 Leader 被选出来,它都会有一 个新的 epoch ,标识当前属于那个 Leader 的统治时期。低32位用于递增计数。
epoch :可以理解为皇帝的年号,当新的皇帝 Leader 产生后,将有一个新的 epoch 年号。
每个Server在工作工程中都有 4种 状态。Looking : 当前 Server 不知道 Leader 是谁,正在搜寻;Leading : 当前 Server 即为选举出来的 Leader;Following : Leader 已经选举出来,当前 Server 与之同步;Observing : 观察者状态,表明当前服务器的角色是 Observer
4. Zookeepe 的通知机制
Zookeeper 允许客户端向服务端的某个 znode 注册一个 Watcher 监听,当服务端的一些指定事件,触发了这个 Watcher ,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据 Watcher 通知状态和事件类型做出业务上的改变。大致分为三个步骤:
客户端注册 Watcher: ①调用 getData、getChildren、exist 三个 API ,传入Watcher 对象;标记请求 request ,封装 Watcher 到 WatchRegistration;③封装成 Packet 对象,发服务端发送request;④收到服务端响应后,将 Watcher 注册到 ZKWatcherManager 中进行管理;⑤请求返回,完成注册。
服务端处理 Watcher:①服务端接收 Watcher 并存储。②Watcher 触发;③调用 process 方法来触发 Watcher。
客户端回调 Watcher:①客户端 SendThread 线程接收事件通知,交由 EventThread 线程回调Watcher;②客户端的 Watcher 机制同样是一次性的,一旦被触发后,该 Watcher 就失效了。
📚 client 端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些 client 会收到 zk 的通知,然后 client 可以根据znode 变化来做出业务上的改变等。
5. Zookeeper 对节点的Watch监听通知是永久的吗
不是,是一次性的。无论是服务端还是客户端,一旦一个 Watcher 被触发,Zookeeper 都会将其从相应的存储中移除。这样的设计有效的减轻了服务端的压力,不然对于更新非常频繁的节点,服务端不断的向客户端发送事件通知无论对于网络还是服务端的压力都非常大。
6. Zookeeper 集群中的角色
在一个集群中,最少需要 3 台。或者保证 2N + 1 台,即奇数。为什么保证奇数?主要是为了举算法。

7. Zookeeper 集群中选举 Leader 的流程
流程:开始投票 → 节点状态变成Looking → 每个节点选自己 → 收到票进行PK → sid大的获胜 → 更新选票 → 再次投票 → 统计选票,选票过半数选举结果 → 节点状态更新为自己的角色状态。
当 Leader 崩溃或者失去了大多数的 Follower , 这时 Zookeeper 就进入恢复模式,恢复模式需要重新选举出一个新的 Leader ,让所有的 Server 都恢复到 Looking 状态。Zookeeper 有两种选举算法:基于basic paxos 实现和基于 fast paxos 实现。默认为 fast paxos 实现。
8. Zookeeper 是如何保证事务的顺序一致性呢
Zookeeper 采用了递增事务 id 来识别,所有的 proposal (提议) 都被在提出的时候加上了 zxid。zxid 实际上是一个 64 为数字。高 32 位是 epoch 用来标识 Leader 是否发生了改变,如果有新的 Leader 产生出来,epoch 会自增。低 32 位用来递增计数。当新产生 proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 Server 发出事务执行请求,如果超过半数的机器都能成功执行,那么就开始执行。
9. Zookeeper 集群中各个服务器之间是怎样通信的
Leader 服务器会和每一个 Follower/Observer 服务器建立 TCP连接,同时为每个 Follower/Observer 都创建一个叫 LearnerHandler 的实体。LearnerHandler 主要负责 Leader 和 Follower/Observer 之间的网络通讯,包括数据同步,请求转发和proposal 提议的投票等。Leader 服务器保存了所有 Follower/Observer 的 LearnerHandler。
10. Zookeeper 分布式锁是怎么实现的
有客户端C1、C2...N个客户端争抢一个 Zookeeper 分布式锁,大致如下
- 大家一上来都是直接创建一个锁节点下的一个接一个的临时有序节点
- 如果自己不是第一个节点,就对自己的上一个节点加节点监听器
- 只要上一个节点释放锁,自己就排到前面去了,相当于是一个排队机制,而且用的是临时顺序节点
另外一个用意就是,如果某个客户端创建临时顺序节点之后,不小心自己宕机了也没关系,Zookeeper 感知到那个客户端宕机,会自动删除对应的临时顺序节点,相当于自动释放锁,或者是自动取消自己的排队。
本地锁,可以用 JDK 实现,但是分布式锁就必须要用到分布式的组件。比如 ZooKeeper、Redis。
11. Zookeeper 的系统架构

-
ZooKeeper分为服务器端(Server) 和客户端(Client),客户端可以连接到整个ZooKeeper服务的任意服务器上(除非LeaderServes参数被显式设置,Leader不允许接受客户端连接)。 - 客户端使用并维护一个
TCP 连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP 连接中断,客户端将自动尝试连接到另外的ZooKeeper服务器。客户端第一次连接到ZooKeeper服务时,接受这个连接的ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。 - 上图中每一个
Server代表一个安装Zookeeper服务的机器,即是整个提供Zookeeper服务的集群 (或者是由伪集群组成); - 组成
ZooKeeper服务的服务器必须彼此了解。它们维护一个内存中的状态图像,以及持久存储中的事务日志和快照, 只要大多数服务器可用,ZooKeeper服务就可用; -
ZooKeeper启动时,将从实例中选举一个Leader,Leader负责处理数据更新等操作,一个更新操作成功的标志是当且仅当大多数Server在内存中成功修改数据。每个Server在内存中存储了一份数据。 -
Zookeeper是可以集群复制的,集群间通过Zab协议(Zookeeper Atomic Broadcast)来保持数据的一致性; -
Zab协议包含两个阶段:Leader election阶段和Atomic Brodcast阶段。- 集群中将选举出一个
Leader,其他的机器则称为follower,所有的写操作都被传送给Leader,并通过brodcast将所有的更新告诉给follower。 - 当
Leader崩溃或者Leader失去大多数的follower时,需要重新选举出一个新的Leader,让所有的服务器都恢复到一个正确的状态。 - 当
Leader被选举出来,且大多数服务器完成了 和Leader的状态同步后,Leadder election的过程就结束了,就将会进入到Atomic brodcast的过程。 -
Atomic Brodcast同步Leader和follower之间的信息,保证Leader和follower具有形同的系统状态。
- 集群中将选举出一个
12. Zookeeper 节点 ZNode 和相关属性
ZNode节点有两种类型 :①持久的 (persistent): 客户端和服务器端断开连接后,创建的节点不删除 (默认);②短暂的(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除。
ZNode有四种形式 : ①持久化目录节点 (PERSISTENT) : 客户端与 Zookeeper 断开连接后,该节点依旧存在;②持久化顺序编号目录节点 (PERSISTENT_SEQUENTIAL) : 客户端与 Zookeeper 断开连接后,该节点依旧存在,只是 Zookeeper 给该节点名称进行顺序编号;③临时目录节点 (EPHEMERAL) : 客户端与 Zookeeper 断开连接后,该节点被删除;④临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL) : 客户端与 Zookeeper 断开连接后,该节点被删除,只是 Zookeeper 给该节点名称进行顺序编号。
「注意
📢 」:创建ZNode时设置顺序标识,ZNode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。
节点的属性
一个 ZNode 节点不仅可以存储数据,还有一些其他特别的属性。接下来我们创建一个 /test 节点分析一下它各个属性的含义
[zk: localhost:2181(CONNECTED) 6] get /test
456
cZxid = 0x59ac
ctime = Mon Mar 30 15:20:08 CST 2020
mZxid = 0x59ad
mtime = Mon Mar 30 15:22:25 CST 2020
pZxid = 0x59ac
cversion = 0
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0属性说明
| 节点属性 | 注解 |
|---|---|
| cZxid | 该数据节点被创建时的事务id |
| mZxid | 该数据节点被修改时最新的事物id |
| pZxid | 当前节点的父级节点事务id |
| ctime | 该数据节点创建时间 |
| mtime | 该数据节点最后修改时间 |
| dataVersion | 当前节点版本号(每修改一次值+1递增〉 |
| cversion | 子节点版本号(子节点修改次数,每修改一次值+1递增〉 |
| aclVersion | 当前节点 acl 版本号(节点被修改 acl 权限,每修改一次值+1递增〉 |
| ephemeralOwner | 临时节点标示,当前节点如果是临时节点,则存储的创建者的会话id ( sessionld〉,如果不是,那么值=0 |
| dataLength | 当前节点所存储的数据长度 |
| numChildren | 当前节点下子节点的个数 |
13. 为什么 Zookeeper 集群的数目一般为奇数个
首先需要明确 Zookeeper 的选举规则: Leader 选举要求可用节点数量 > 节点数量/2
比如 : 标记一个写是否成功是要在超过一半节点发送写请求成功时才认为有效。同样 Zookeeper 选举领导者节点也要在超过一半节点同意时才生效。最后 Zookeeper 是否正常是要根据是否超过一半以上节点都正常才算正常。这是基于CAP的一致性原理。
Zookeeper 有个特性,集群中只要有一半以上节点正常工作,那么集群对外就是可用的。也就是说两个节点有一个挂了就不能用了,因为 1 没过半,所以 2 个 zk 节点的死亡容忍度为 0;同理要是 3 个 zk 节点组成的集群,挂了一个还剩 2 个正常的,过半了,所以 3 个 zk 节点的集群死亡容忍度为 1。
Zookeeper 的选举策略也是需要过半数以上节点同意才能当选 Leader ,如果是偶数节点可能出现平票情况。
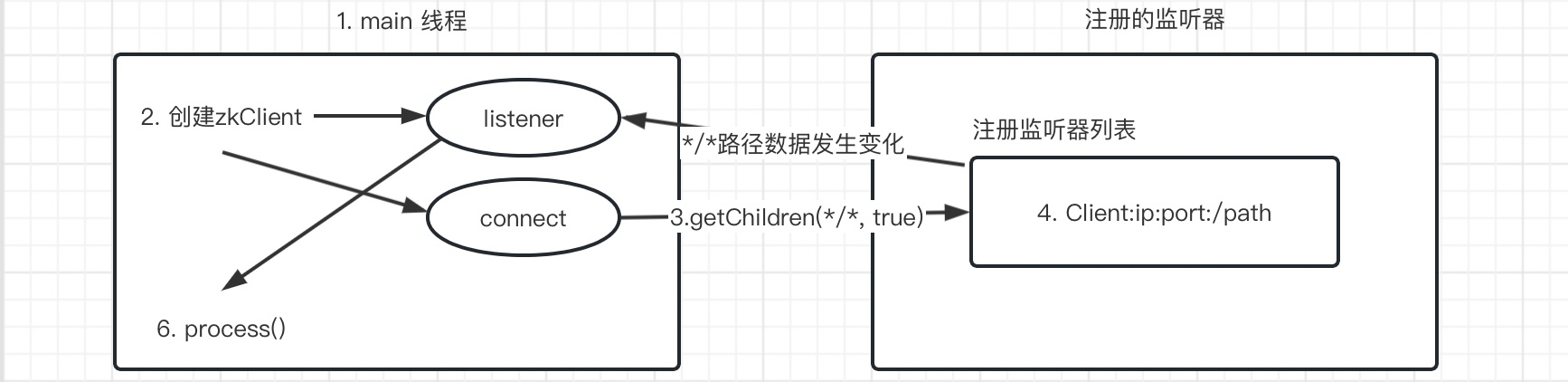
14. Zookeeper 监听器的原理
- 创建一个
main线程。 - 在
main线程创建两个线程,一个负责网络通信 (connect),一个负责监听 (listener)。 - 通过
connect线程将注册的监听事件发送给Zookeeper。 - 将
注册的监听器事件添加到Zookeeper的注册监听器列表中。 -
Zookeeper监听到有数据或路径发生变动,把这条消息发送给listener线程。 -
Listener线程内部调用process方法。
15. Zookeeper 的CAP问题上做的取舍
一致性 (C) : Zookeeper 是强一致性系统,为了保证较强的可用性,"一半以上成功" 的数据同步方式可能会导致部分节点的数据不一致。所以 Zookeeper 还提供了 sync() 操作来做所有节点的数据同步,这就将关于 C 和 A 的问题交给了用户,因为使用 sync() 势必会延长同步时间,可用性会有一些损失。
可用性 (A) : Zookeeper 数据存储在内存中,且个节点都可以发起读请求,具有好的相应性能。Zookeeper 保证数据总是可用的,没有锁。并且有一大半的节点所拥有的数据是最新的。
分区容错性 (P) : Follower节点 过多会导致增大数据同步的延时 (需半数以上的 flollower节点 写完提交)。同时选举过程的收敛速度会变慢,可用性降低。Zookeeper 通过引入 Observer节点 缓解了这个问题,通过增加 Observer节点 后集群可接受 client请求 的节点多了,而且 Observer节点 不参与投票,可以提高可用性和扩展性,但是节点多数据同步总归是个问题,所以一致性会有所降低。
16. Zookeeper 的脑裂
简单点来说,脑裂(Split-Brain) 就是比如当你的 cluster 里面有两个节点,它们都知道在 cluster 里需要选举出一个 master 。那么当它们两个之间的通信完全没有问题的时候,就会达成共识,选举其中一个作为 master ;但是如果它们之间的通信出了问题,那么两个结点都会觉得现在没有 master ,所以每个都把自己选举成 master ,于是 cluster 里面就会有两个 master 。对于 Zookeeper 来说有个很重要的问题,就是到底是根据一个什么样的情况来判断一个节点死亡 down 掉了?在分布式系统中这些都是有监控者来判断的,但是监控者也很难判定其他的节点的状态,唯一一个可靠的途径就是心跳,Zookeeper 也是使用心跳来判断客户端是否仍然活着。使用 ZooKeeper 来做 Leader HA 基本都是同样的方式:每个节点都尝试注册一个象征 Leader的临时节点 ,其他没有注册成功的则成为 follower ,并且通过 Watch机制 监控着 Leader 所创建的临时节点,Zookeeper 通过内部心跳机制来确定 Leader 的状态,一旦Leader 出现意外 Zookeeper 能很快获悉并且通知其他的 follower ,其他 follower 在之后作出相关反应,这样就完成了一个切换,这种模式也是比较通用的模式,基本大部分都是这样实现的。但是这里面有个很严重的问题,如果注意不到会导致短暂的时间内系统出现脑裂,因为心跳出现超时可能是 Leader 挂了,但是也可能是 Zookeeper 节点之间网络出现了问题,导致 Leader假死 的情况,Leader 其实并未死掉,但是与 ZooKeeper 之间的网络出现问题导致 Zookeeper 认为其挂掉了然后通知其他节点进行切换,这样 follower 中就有一个成为了 Leader ,但是原本的 Leader 并未死掉,这时候 client 也获得 Leader 切换的消息,但是仍然会有一些延时, Zookeeper 需要通讯需要一个一个通知,这时候整个系统就很混乱可能有一部分 client 已经通知到了连接到新的 Leader 上去了,有的 client 仍然连接在老的 Leader 上,如果同时有两个 client 需要对 Leader 的同一个数据更新,并且刚好这两个 client 此刻分别连接在新老的 Leader 上,就会出现很严重问题。
🏠 假死:由于心跳超时(网络原因导致的)认为 Leader 死了,但其实 Leader 还存活着。 脑裂:由于假死会发起新的 Leader 选举,选举出一个新的 Leader,但旧的 Leader 网络又通了,导致出现了两个 Leader,有的客户端连接到老的 Leader,而有的客户端则连接到新的 Leader。
17. Zookeeper 脑裂的导致原因
主要原因是 Zookeeper 集群和 Zookeeper Client 判断超时并不能做到完全同步,也就是说可能一前一后,如果是集群先于 Client 发现,那就会出现上面的情况。同时,在发现并切换后通知各个客户端也有先后快慢。一般出现这种情况的几率很小,需要 Leader 节点与 Zookeeper 集群网络断开,但是与其他集群角色之间的网络没有问题,还要满足上面那些情况,但是一旦出现就会引起很严重的后果,数据不一致。
18. Zookeeper 是如何解决脑裂问题的
要解决 Split-Brain脑裂 的问题,一般有下面几种种方法:
-
Quorums (法定人数) 方式 : 比如 3 个节点的集群,Quorums = 2, 也就是说集群可以容忍 1 个节点失效,这时候还能选举出 1 个
Leader,集群还可用。比如 4 个节点的集群,它的Quorums = 3,Quorums要超过 3 ,相当于集群的容忍度还是 1,如果 2 个节点失效,那么整个集群还是无效的。这是Zookeeper防止 "脑裂" 默认采用的方法。 - Redundant communications (冗余通信)方式 : 集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
-
Fencing (共享资源) 方式 : 比如能看到共享资源就表示在集群中,能够获得共享资源的锁的就是
Leader,看不到共享资源的,就不在集群中。要想避免Zookeeper脑裂情况其实也很简单,follower节点切换的时候不再 检查到老的Leader节点出现问题后马上切换,而是在休眠一段足够的时间,确保老的Leader已经获知变更并且做了相关的shutdown清理工作了然后再注册成为master就能避免这类问题了,这个休眠时间一般定义为与Zookeeper定义的超时时间就够了,但是这段时间内系统可能是不可用的,但是相对于数据不一致的后果来说还是值得的。
/**
1. ZooKeeper 默认采用了Quorums这种方式来防止"脑裂"现象。即只有集群中超过半数节点投票才能选举出 Leader。这样的方式可以确保 Leader的唯一性,要么选出唯一的一个 Leader,要么选举失败。在 Zookeeper中Quorums作用如下:集群中最少的节点数用来选举 Leader 保证集群可用。通知客户端数据已经安全保存前集群中最少数量的节点数已经保存了该数据。一旦这些节点保存了该数据,客户端将被通知已经安全保存了,可以继续其他任务。而集群中剩余的节点将会最终也保存了该数据。
假设某个 Leader 假死,其余的 followers 选举出了一个新的 Leader。这时,旧的 Leader 复活并且仍然认为自己是 Leader,这个时候它向其他 followers 发出写请求也是会被拒绝的。因为每当新 Leader产生时,会生成一个epoch标号(标识当前属于那个leader的统治时期),这个epoch是递增的,followers 如果确认了新的 Leader 存在,知道其 epoch,就会拒绝 epoch 小于现任 Leader epoch 的所有请求。那有没有 follower 不知道新的 Leader 存在呢,有可能,但肯定不是大多数,否则新 Leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧 Leader 即使各种认为自己是 Leader,依然没有什么作用。
2. 添加冗余的心跳线,例如双线条线,尽量减少 "裂脑" 发生机会。
3. 启用磁盘锁。正在服务一方锁住共享磁盘,"裂脑" 发生时,让对方完全 "抢不走" 共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动 "解锁",另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在 HA 中设计了 "智能" 锁。即正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
4. 设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2 个节点都各自ping一下 参考IP,不通则表明断点就出在本端,不仅"心跳"、还兼对外 "服务" 的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
*/
19. Zookeeper 选举中投票信息的五元组
-
Leader :被选举的
Leader的 SID - Zxid :被选举的 Leader 的事务 ID
- Sid :当前服务器的 SID
- electionEpoch :当前投票的轮次
- peerEpoch :当前服务器的 Epoch
Epoch > Zxid > Sid。Epoch、Zxid 都可能一致,但是 Sid 一定不一样,这样两张选票一定会 PK 出结果。
20. Zookeeper 的持久化机制
SnapShot 快照,记录内存中的全量数据,TxnLog 增量事务日志,记录每一条增删改记录(查不是事务日志,不会引起数据变化)
为什么是两种方式,一个不可用吗?
快照的缺点,文件太大,而且快照文件不会是最新的数据。 增量事务日志的缺点,运行时间了,日志太多了,加载太慢。二者结合最好。快照模式:将 ZooKeeper 内存中以 DataTree 数据结构存储的数据定期存储到磁盘中。由于快照文件是定期对数据的全量备份,所以快照文件中数据通常不是最新的。

21. Zookeeper 的 Zxid 和 Epoch 是什么,有什么作用
Zxid : 也就是 事务 id ,为了保证事务的顺序一致性,ZooKeeper 采用了递增的事务 Zxid 来标识事务。proposal 都会加上了 Zxid 。Zxid 是一个 64 位的数字,它高 32 位是 Epoch 用来标识朝代变化,比如每次选举 Epoch 都会加改变。低 32 位用于递增计数。
Epoch : 可以理解为当前集群所处的年代或者周期,每个 Leader 就像皇帝,都有自己的年号,所以每次改朝换代,Leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 Leader 崩溃恢复之后,也没有人听它的了,因为 Follower 只听从当前年代的 Leader 的命令。
22. Zookeeper负载均衡 和 Nginx负载均衡 有什么区别
Zookeeper : ①不存在单点问题,zab 机制 保证单点故障可重新选举一个 Leader ;②只负责服务的注册与发现,不负责转发,减少一次数据交换(消费方与服务方直接通信);③需要自己实现相应的负载均衡算法。
Nginx : ①存在单点问题,单点负载高数据量大,需要通过 KeepAlived 辅助实现高可用;②每次负载,都充当一次中间人转发角色,本身是个反向代理服务器;③自带负载均衡算法。
23. Zookeeper 的序列化
- 内存数据,保存到硬盘需要序列化。
- 内存数据,通过网络传输到其他节点,需要序列化。
ZK 使用的序列化协议是 Jute,Jute 提供了 Record 接口。接口提供了两个方法
-
serialize 序列化方法
-
deserialize 反序列化方法
24. Zookeeper 的 ACL 权限控制机制
UGO(User/Group/Others) 目前在 Linux/Unix 文件系统中使用,也是使用最广泛的权限控制方式。是一种粗粒度的文件系统权限控制模式。
ACL(Access Control List) 访问控制列表包括三个方面
-
权限模式(Scheme)
- IP:从 IP 地址粒度进行权限控制
- Digest:最常用,用类似于 username:password 的权限标识来进行权限配置,便于区分不同应用来进行权限控制
- World:最开放的权限控制方式,是一种特殊的 digest 模式,只有一个权限标识 "world:anyone"
- Super:超级用户
-
授权对象
授权对象指的是权限赋予的用户或一个指定实体,例如 IP 地址或是机器灯。
-
权限Permission
- CREATE:数据节点创建权限,允许授权对象在该 Znode 下创建子节点
- DELETE:子节点删除权限,允许授权对象删除该数据节点的子节点
- READ:数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表等
- WRITE:数据节点更新权限,允许授权对象对该数据节点进行更新操作
- ADMIN:数据节点管理权限,允许授权对象对该数据节点进行 ACL 相关设置操作
25. Zookeeper 有哪几种部署模式
- 单机部署 :一台机器上运行
- 集群部署 :多台集群运行
- 伪集群部署 : 一台机器启动多个 Zookeeper 实例运行
26. 描述一下 ZAB协议
ZAB 协议 是 ZooKeeper 自己定义的协议,全名 ZooKeeper 原子广播协议 。
它有两种模式:恢复模式(选主) 和 广播模式(同步)。
整个 ZooKeeper 集群没有 Leader 节点的时候,属于崩溃的情况。比如集群启动刚刚启动,这时节点们互相不认识。比如运作 Leader 节点宕机了,又或者网络问题,其他节点 Ping 不通 Leader 节了。这时就需要 ZAB 中的节点崩溃协议,所有节点进入选举模式,选举出新的 Leader。整个选举过程就是通过广播来实现的。选举成功后,一切都需要以 Leader 的数据为准,那么就需要进行数据同步了。
27. ZAB 和 Paxos 算法的异同
相同点 : ①两者都存在一个类似于 Leader 进程的角色,由其负责协调多个 Follower 进程的运行;② Leader 进程都会等待超过半数的 Follower 做出正确的反馈后,才会将一个提案进行提交;③ ZAB 协议 中,每个 Proposal 中都包含一个 epoch 值来代表当前的 Leader 周期,Paxos 中名字为 Ballot 。
不同点 : ZAB 用来构建高可用的分布式数据主备系统 (Zookeeper),Paxos 是用来构建分布式一致性状态机系统。
28. Zookeeper 集群支持动态添加机器嘛
其实就是水平扩容了,Zookeeper 在这方面不太好。
全部重启 :关闭所有 Zookeeper 服务,修改配置之后启动。不影响之前客户端的会话。
逐个重启 :在过半存活即可用的原则下,一台机器重启不影响整个集群对外提供服务。这是比较常用的方式。
Zookeeper 3.5 版本开始支持动态扩容
三、Consul服务注册与发现
Consul是一套开源的分布式服务发现和配置管理系统,由HashiCorp公司用Go语言开发。
提供了微服务系统中的服务治理、配置中心、控制总线等功能。这些功能中的每一个都可以根据需要单独使用,也可以一起使用以构建全方位的服务网络,总之Consul提供了一种完整的服务网格解决方案。
1. Consul 的四大核心特性
- 服务发现 :可以方便的实现服务注册,通过 DNS 或者 HTTP 应用程序可以很容易地找到他所依赖的服务。
- Key / value 存储 :使用 Key / Value 进行数据存储。
- 多数据中心 :Consul 支持开箱即用的多数据中心。这意味着用户不需要担心建立额外的抽象层让业务扩展多个区域。
- 健康检查 :可以对指定服务进行健康检查。检查例如 Response Status 是否为 200,避免将流量转发到不健康的服务。
四、Ribbon负载均衡服务调用
SpringCloud Ribbon 是基于 Netflix Ribbon 实现的一套 客户端 负载均衡的工具 。
主要功能是提供客户端的软件负载均衡算法和服务调用。
1. Ribbon的负载均衡策略
-
RoundRobinRule : 轮询。通过
int next = (current + 1) % modulo (所有服务器数)实现。 -
RandomRule : 随机。通过
ThreadLocalRandom.current().nextInt(serverCount)实现,保证随机性 和 线程隔离性。 -
BestAvailableRule : 最小并发请求。通过
getActiveRequestsCount()函数选择一个最小并发请求的 server。 - AvailabilityFilteringRule : 过滤掉一直连接失败被标记为 circuit tripped 的后端 server,然后选择并发最小的实例。
-
WeightedResponseTimeRule : 响应时间权重。
- 实现原理:机器 A(wt = 10) | B(wt=20) | C(wt=30) | D(wt=40) 权重[1,10] [11,30] [31, 60] [61, 100]。随机数[1, 100]选择机器。
- 实现依赖:权重根据计算 动态响应时间 得到。① 通过
DynamicServerWeightTask以定时任务的方式计算响应时间,调度的时间为 30 秒;② 首先计算所有服务器的平均响应时间之和,记为totalResponseTime;③ 计算单个服务器权重,weight = totalResponseTime - 服务器平均响应时间,计算完后,更新权重列表。 - 调用过程:① 判断权重列表是否初始化,若没有暂时使用轮询策略;② 生成随机数并判断落在哪个权重区间,返回对应的服务器即可;③ 其他的例如判断服务器可用性等于随机、轮询一致。
- RetryRule : 先按照 RoundRobinRule 的策略获取服务,如果获取服务失败则在指定时间内进行重试,获取可用服务。
- ZoneAvoidanceRule : 默认规则,复合判断Server所在区域的性能和Server的可用性选择服务器。
2. 客户端负载均衡 和 服务端负载均衡的区别
服务端负载均衡 分两种,硬件负载均衡例如 F5、Array 等,另一种是软件负载均衡例如 LVS、Nginx 等。客户端发送请求被服务端负载均衡拦截,根据负载均衡算法分发到具体的服务器上处理请求。客户端负载均衡 指的是分布式系统中在客户端的 Ribbon 通过负载均衡算法请求远程服务。
服务端负载均衡: 客户端 → 负载均衡服务器 → 服务端
客户端负载均衡:客户端 → 服务端
综上,服务端负载均衡是通过一台负载均衡服务器来达到效果的,而客户端负载均衡通过自己就能够达到负载均衡 (先从注册中心拉取服务列表),并不需要其他服务器。
3. 如何修改负载均衡算法,如何手写负载均衡器
修改负载均衡算法:写个 MyRule 的配置类,配置一个Bean,返回IRule类型的对象 (RandomRule)。配置到启动类的 @RibbonClient 注解的 configuration 属性上就行了。
手写负载均衡器 : 去掉配置给 RestTemplate 加的 @LoadBalanced 注解;新建 LoadBalancer 接口;新建组件 MyLB 实现 LoadBalancer 接口里的 ServiceInstance instances(List<ServiceInstance> serviceInstances), 通过原子整型自增数 和 服务实例数 取模得到实例组下标,取出返回。自增这块用到了 CAS 和 自旋锁;最后通过 DiscoveryClient 对象获取 指定 服务的所有实例,调用 loadBalancer 的 instances 方法获取服务实例,通过 serviceInstance.getUri() 拿到 url 拼接访问路径即可实现轮询的负载均衡。
五、OpenFeign服务接口调用
Feign 是一个声明式 WebService 客户端。使用 Feign 能让编写 WebService 客户端更加简单。
它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可插拔式的编码器和解码器。SpringCloud 对 Feign 进行了封装,使其支持了 SpringMVC 标准注解和 HttpMessageConverters。Feign 可以与 Eureka 和 Ribbon 组合使用以支持负载均衡。
1. SpringCloud Feign 与 OpenFeign区别
- Feign 是 Spring Cloud 组件中一个轻量级 RESTful 的 HTTP 服务客户端。Feign 内置了 Ribbon,用来做客户端的负载均衡,去调用服务注册中心中的服务。Feign的使用方式是:使用 Feign 的注解定义接口,调用接口,就可以调用服务注册中心的服务。
- OpenFeign 是 Spring Cloud 在 Feign 的基础上支持了 SpringMVC 注解,如 @RequestMapping 等。OpenFeign 的 @FeignClient 可以解析 SpringMVC 的 @RequestMapping 注解下的接口,并通过动态代理方式产生实现类。
👶 🏻 说明:Spring Cloud F 及以上版本 Spring Boot 2.0 以上基本都是用 OpenFeign。OpenFeign 从框架结构上看就是 2019年 Feign 停更后出现版本,也可以说大多数新项目都用 OpenFeign,2018年以前的项目在使用 Feign。
六、Hystrix断路器
Hystrix 是一个用于处理分布式系统的延迟和容错的开源库。在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
1. Hystrix功能
Hystrix 实现了 开关降级、超时降级、熔断降级、接近实时的监控等功能。
2. Hystrix 整体流程
- 入口 : 通过 HystrixCommand 和 HystrixCollapser 注解修饰的方法,会被 HystrixCommandAspect 进行 aop 处理
- 缓存 : 如RequestCache打开,则判断缓存是否命中
- 熔断 : 判断是否有被开关降级、熔断降级,若被降级,则走降级逻辑;若未被降级,则走正常逻辑
- 隔离 : 根据配置走线程池隔离或信号量隔离,任务满则走降级逻辑
- 执行 : 执行任务,若任务执行失败或异常,则进入降级逻辑
- 超时 : 通过定时器延时任务检测业务调用执行是否超时,若超时则取消业务执行的线程,进入降级逻辑;若未超时,则正常返回
- 降级 : 若进入降级逻辑,根据 getFallback() 方法,返回降级处理的数据,若未实现该方法,则返回异常
- 统计 : 业务调用执行结果成功、失败、超时等均会进入统计模块,通过健康统计结果来决定熔断器打开或关闭
3. RequestCache 是什么
缓存在高并发的环境下使用,能够有效地减少服务器的压力,使用Hystrix返回结果缓存,后续请求可以直接调用缓存数据,该缓存就是RequestCache。
Hystrix 提供了 RequestCache 的参数 requestCache.enabled 设置是否缓存请求 默认值true
4. Hystrix 开关降级如何实现
Hystrix 提供了开关降级的参数。① circuitBreaker.forceOpen : 熔断器强制打开,该状态下它将拒绝所有请求。默认值FALSE。② circuitBreaker.forceClosed :熔断器强制关闭,在此状态下,无论错误百分比如何,它都将允许请求。默认值FALSE。
5. Hystrix 超时降级如何实现
Hystrix 提供了超时降级的参数。① execution.isolationthread.timeoutInMilliseconds : 超时时间,默认值为1000;② execution.timeout.enabled : 是否启用超时时间,默认值为true;③ execution.isolation.thread.interruptOnTimeout : 超时后是否允许 interrupt,默认为 true;④ execution.isolation.thread.interruptOnCancel : cancel 后是否 interrupt,默认为 false。
6. Hystrix 熔断降级如何实现
Hystrix提供了熔断降级的参数。① circuitBreaker.requestVolumeThreshold : 触发熔断判断的请求次数阈值,默认值为20,是一段时间内至少有20个请求才进行熔断降级计算。比如一段时间有19个请求全部失败,错误率是100%,但熔断器不会打开,因为总请求数不满足20;② circuitBreaker.sleepWindowInMilliseconds : 半开状态试探睡眠时间,默认值5000ms,如熔断器开启5000ms后,会尝试翻过去一部分流量进行试探,确定依赖服务是否恢复;③ circuitBreaker.errorThresholdPersentage : 错误率,默认值50%,例如一段时间(10s)内有100个请求,其中有54个超时或者有异常,则错误率是54%,大于默认值50%,这种情况下触发熔断器开关。
7. 线程池隔离 与 信号量隔离 的选型
线程池隔离 和 信号量隔离是用于限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。
THREAD(线程隔离) :使用该方式,HystrixCommand将会在单独的线程上执行,并发请求受线程池中线程数量的限制。
SEMAPHORE(信号量隔离) :使用该方式,HystrixCommand将会在调用线程上执行,开销相对较小,并发请求受信号量的个数的限制。
配置:hystrix.command.default.execution.isolation.strategy 隔离策略,默认是Thread, 可选Thread|Semaphore
七、Zuul路由网关
网关相当于一个网络服务架构的入口,所有网络请求必须通过网关转发到具体的服务。
统一管理微服务请求,权限控制、负载均衡、路由转发、监控、安全控制 黑名单 和 白名单 等。
1. 什么是 Spring Cloud Zuul (服务网关)
Zuul 是一种提供动态路由、监视、弹性、安全性等功能的边缘服务。
Zuul 是 Netflix 出品的一个基于 JVM 路由和服务端的负载均衡器。 API 网关的定义类似于设计模式中的门面模式,它相当于整个微服务架构中的门面,所有客户端的访问都通过它来进行路由及过滤。它实现了请求路由、负载均衡、校验过滤、服务容错、服务聚合等功能。 Zuul 的主要有 代理、路由 和 过滤 三大功能。
Zuul 的应用场景:对外暴露、权限校验、服务聚合、日志审计等。
2. 网关和过滤器的区别
网关是对所有服务的请求进行分析过滤,过滤器是对单个服务而言。
3. Zuul 和 Nginx 的区别
Zuul 是 Java语言 实现的,主要为 Java服务 提供网关服务,尤其在微服务架构中可以更加灵活的对网关进行操作。 Nginx是使用C语言实现,性能高于Zuul,但是实现自定义操作需要熟悉lua语言,对程序员要求较高,可以使用Nginx做Zuul集群。
4. 如何设计一套 API 接口
考虑到 API接口 的分类可以将 API接口 分为 开发API接口 和 内网API接口。内网API接口用于局域网,为内部服务器提供服务;开放API接口 用于对外部合作单位提供接口调用,需要遵循Oauth2.0权限认证协议。同时还需要考虑安全性、幂等性等问题。
5. ZuulFilter常用方法
- Run() :过滤器的具体业务逻辑
- shouldFilter() :判断过滤器是否有效
- filterOrder() :过滤器执行顺序
- filterType():过滤器拦截位置
6. 如何实现动态 Zuul 网关路由转发
通过 path 配置拦截请求,通过 ServiceId 到配置中心获取转发的服务列表,Zuul 内部使用 Ribbon 实现本地负载均衡和转发。
7. Zuul 网关如何搭建集群
使用 Nginx 的 upstream 设置 Zuul服务集群,通过 location 拦截请求并转发到 upstream,默认使用轮询机制对 Zuul集群 发送请求。
八、Gateway新一代网关
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring 5,Spring Boot 2和 Project Reactor等技术。 Spring Cloud Gateway是Spring Cloud官方推出的第二代网关框架,取代Zuul网关。网关作为流量的入口,在微服务系统中有着非常作用,网关常见的功能有路由转发、权限校验、限流控制等作用。
1. Gateway 和 Zuul 的区别
-
gateway :是Spring Cloud自己研制的微服务网关,是基于Spring5构建,能够实现响应式非阻塞式的Api,支持长连接。
-
zuul :是Netflix的,是基于Servlet实现的,阻塞式的api,不支持长连接。
2. Gateway 的组成
- 路由 : 网关的基本模块,有ID,目标URI,一组断言和一组过滤器组成
- 断言 :就是访问该服务的访问规则,可以用来匹配来自http请求的任何内容,例如headers或者参数
- 过滤器 :这个就是我们平时说的过滤器不同,用来过滤一些请求的,gateway有自己默认的过滤器,具体请参考官网,我们也可以自定义过滤器,但是要实现两个接口,Ordered和Globalfilter
3. Gateway的流程
- 客户端发送请求,会到达网关的 DispatcherHandler 处理,匹配到 RoutePredicateHandlerMapping。
- 根据 RoutePredicateHandlerMapping 匹配到具体的路由策略。
- FilteringWebHandler 获取的路由的 GatewayFilter 数组,创建 GatewayFilterChain 处理过滤请求。
- 执行我们的代理业务逻辑访问。
九、SpringCloud Config分布式配置中心
SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为 各个不同微服务应用 的所有环境提供了一个 中心化的外部配置 。
1. SpringCloud Config 可以实现实时刷新吗
springcloud config 实时刷新采用SpringCloud Bus消息总线。
十、SpringCloud Bus消息总线
Spring Cloud Bus 配合 Spring Cloud Config 使用可以实现配置的动态刷新。
Spring Cloud Bus 是用来将分布式系统的节点与轻量级消息系统链接起来的框架, 它整合了Java的事件处理机制和消息中间件的功能。
十一、SpringCloud Stream消息驱动
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。
十二、SpringCloud Sleuth分布式请求链路跟踪
Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案,在分布式系统中提供追踪解决方案并且兼容支持了zipkin。
十三、Apollo配置中心
配置中心
十四、SpringCloud Alibaba Nacos服务注册和配置中心
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。 Nacos: Dynamic Naming and Configuration Service Nacos 就是注册中心 + 配置中心的组合
1. Nacos中保护阈值的作用是什么
假如现在有一个服务,本来有10个实例,但是现在挂掉了8个,剩下2个正常实例,此时本来由10个实例处理的流量,就全部交给这个两个正常实例来处理了,此时这两个实例很有可能是处理不过来的,最终导致被压垮,为了应对这种情况,Nacos提供了保护阈值这个功能,我们可以给某个服务设置一个0-1的阈值,比如0.5,那就表示,一旦实例中只剩下一半的健康实例了,比如10个实例,只剩下5个健康实例了,那么消费者在进行服务发现时,则会把该服务的所有实例,也包括不健康的实例都拉取到本地,然后再从所有实例中进行负载均衡,选出一个实例进行调用,在这种情况下,选出来的即可能是一个健康的实例,也可能是挂掉的实例,但是通过这种方式,很好的保护的剩下的健康实例,至少保证了一部分请求能正常的访问,而不至于所有请求都不能正常访问,这就是Nacos中的保护阈值,同时,这个功能在Spring Cloud Tencent中叫全死全活。
2. Nacos中的负载均衡是怎么样的
Nacos的负载均衡指的是,在进行服务发现时进行负载均衡,正常情况下,在进行服务发现时,会根据服务名从Nacos中拉取所有的实例信息,但是Nacos中提供了一个功能,就是可以在拉取实例时,可以根据随机策略只拉取到所有实例中的某一个,这就是Nacos中的负载均衡,它跟Ribbon的负载均衡并不冲突,可以理解为Ribbon的负载均衡是发生在Nacos的负载均衡之后的。
3. Nacos的就近访问是什么意思
首先,在Nacos中,一个服务可以有多个实例,并且可以给实例设置cluster-name,就是可以再进一步的给所有实例划分集群,那如果现在某个服务A想要调用服务B,那么Naocs会看调用服务A的实例是属于哪个集群的,并且调用服务B时,那就会调用同样集群下的服务B实例,根据cluster-name来判断两个实例是不是同一个集群,这就是Nacos的就近访问。
4. 你是怎么理解CAP理论的
CAP理论是分布式领域中最为重要的理论,CAP理论可以理解为目前硬件条件下对于分布式架构的一种限制,就是对于一个分布式系统,只能保证AP或CP,而不能同时保证CAP,首先对于一个分布式系统,P,也就是分区容错性是一定要保证的,对于一个分布式系统,得保证在网络出现分区后,分布式系统仍然能工作,所以得保证P,只不过当出现网络分区后,整个分布式系统如果想要保证数据一致性,那么就要损耗系统可用性,或者如果想要保证系统的可用性,就不能保证系统的一致性,这里说的是强一致性,因为如果网络出现问题,分布式系统中的数据就无法进行及时的同步,如果要求强一致性,那么就只能等网络好了之后,数据同步好了之后,才能提供给用户使用,同理,如果要求网络出现后问题,系统要能使用,那就可能数据会不一致,所以对于一个分布式系统,目前来说只能保证CP或AP。
5. Nacos中保证的是CP还是AP
通常我们说,Nacos既能保证CP,也能保证AP,具体看如何配置,但其实只不过是Nacos中的注册中心能保证CP或AP,Nacos中的配置中心其实没什么CP或AP,因为配置中心的数据是存在一个Mysql中的,只有注册中心的数据需要进行集群节点之间的同步,从而涉及到是CP还是AP,如果注册的节点是临时节点,那么就是AP,如果是非临时节点,那么就是CP,默认是临时节点。
6. 如何理解Nacos命名空间
命名空间,也就是namespace,其实这个概念并不是Nacos中独有的,在Nacos中,不管是配置还是服务,都是属于某一个命名空间中的,默认情况下都是属于pulibc这个命名空间中的,我们可以在Nacos中新增命名空间,也就相当于开辟了另外一套存放服务和配置的地方,命名空间之间是独立的,完全不冲突的,所以我们可以利用Nacos中的命名空间来实现不同环境、不同租户之间的服务注册和配置。
7. 你觉得注册中心应该是CP还是AP
我觉得大部分情况下,注册中心应该是AP,如果注册中心是CP的,那么表示,当我们向注册中心注册实例或移除实例时,都要等待注册中心集群中的数据达到一致后,才算注册或移除成功,而这是比较耗时的,随着业务应用规模的增大,应用频繁的上下线,那么就会导致注册中心的压力比较大,会影响到服务发现的效率以及服务调用了,而如果注册中心是AP的,那么注册中心集群不管出现了什么情况,都是可以提供服务的,就算集群节点之间数据出现了不一致,对于业务应用而言,可能拉取到了一个已经下线了的服务节点,但是现在一般的微服务框架或组件都提供了服务容错和重试功能,也可以避免这个问题,而如果是AP,对于注册中心而言就不需要消耗太多的资源来实时的保证数据一致性了,保证最终一致性就可以了,这样注册中心的压力会小一点,另外像Zookeeper来作为注册中心,因为Zookeeper保证的就是CP,但是如果集群中如果大多数节点挂掉了,就算还剩下一些Zookeeper节点,这些节点也是不能提供服务的,所以这个也不太合适,所以综合来看,注册中心应该保证AP会更好,就像Euraka、Nacos他们默认保证的就是AP。
十五、SpringCloud Alibaba Sentinel实现熔断与限流
轻量级流量控制,熔断降级的Java库

1. 什么是Sentinel
Sentinel 顾名思义:卫兵;在Redis中叫做 哨兵 ,用于监控主从切换,但是在微服务中叫做 流量防卫兵 。
Sentinel 以流量为切入点,从 流量控制 、 熔断降级 、 系统负载 保护等多个维度保护服务的稳定性。
Sentinel 具有 丰富的应用场景、完备的实时监控、广泛的开源生态、完善的 SPI 扩展机制。
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
- 完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 分为两个部分:
核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
2. Sentinel 和 Hystrix 的区别
从线程模型上看Sentinel使用的是tomcat/jetty/other本身的线程池。Hystrix使用的是自己创建的线程池
| Items | Sentinel | Hystrix | remark |
|---|---|---|---|
| 隔离策略 | 信号量隔离(并发线程数限流)(模拟信号量) | 线程池隔离/信号量隔离 | Sentinel不创建线程依赖tomcat或jetty容器的线程池,存在的问题就是运行容器的线程数量限制了sentinel设置值的上限可能设置不准。比如tomcat线程池为10,sentinel设置100是没有意义的,同时隔离性不好hystrix使用自己创建的线程池,隔离性会更好 |
| 熔断降级策略 | 基于响应时间、异常比率、异常数 | 基于异常比率 | 快速失败的本质功能 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于 RxJava) | |
| 动态规则配置 | 支持多种数据源 | 支持多种数据源 | |
| 扩展性 | 多个扩展点 | 插件的形式 | |
| 基于注解的支持 | 支持 | 支持 | |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持(并发线程数或信号量大小) | 快速失败的本质功能 |
| 流量整形 | 支持预热模式、匀速器模式、预热排队模式 | 不支持(排队) | 支持排队好吧 |
| 系统自适应保护 | 支持(仅对linux生效) | 不支持 | 所谓的自适应就是设置一个服务器最大允许处理量的阈值。(有比没有强,但是要知道最大负载量是多少。) |
| 控制台 | 提供开箱即用的控制台,可配置规则、查看秒级监控、机器发现等 | 简单的监控查看接近实时数据 | 控制台是非常有竞争力的功能,因为能集中配置限制数据更方便,但是展示数据和实时性没有hystrix直观。 |
| 配置持久化 | ZooKeeper, Apollo, Nacos | Git/svn/本地文件 | Sentinel客户端采用直接链接持久化存储,应用客户端引用了更多的依赖,同样的存储链接可能有多个配置 |
| 动态配置 | 支持 | 支持 | hystrix可能需要手动触发,sentinel增加了额外的端口进行配置文件控制,应该也支持spring boot动态配置 |
| 黑白名单 | 支持 | 不支持 | 个人觉得这个功能用的不是很多 |
| springcloud集成 | 高 | 非常高 | Spring boot使用hystrix会更方便 |
| 整体优势 | 集中配置设置及监控+更细的控制规则 | 漂亮的界面+接近实时的统计结果 | 集中配置可能更有吸引力,但是配置值是多少以及让谁控制依然是很头疼的事情。运维控制可能不知道哪个应该优先哪个不优先,应该调整到多大。什么时候更适合使用sentinel?个人认为docker容器化部署之后sentinel可能更会发挥作用,但是会有另外的竞品出现做选型。 |
十六、SpringCloud Alibaba Seata处理分布式事务
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
Simple Extensible Autonomous Transaction Architecture,简单可扩展自治事务框架
1. 分布式事务产生背景
在传统的单体项目中,多个不同的业务逻辑使用的都是同一个数据源,使用的都是同一个事务管理器,所以不会存在事务问题。 在分布式或者微服务架构中,每个服务都有自己的数据源,使用不同事务管理器,如果A服务去调用B服务,B服务执行失败了,A服务的事务和B服务的事务都会回滚,这时候是不存在事务问题的,但是如果A服务在B服务执行成功之后出现异常,A服务的事务会回滚,但是B服务的事务不会回滚,此时就存在分布式事务问题。
在单体的项目中,有多个不同的数据源,每个数据源中都有自己独立的事务管理器,互不影响,那么这时候也会存在多数据源事务管理:解决方案jta+ atominc
2. 常见的分布式事务解决方案
MQ、LCN、Seata
3. Seata分布式事务框架实现原理
Seata有三个组成部分:
① 事务协调器TC : 协调者; ② 事务管理器TM : 发起方;③ 资源管理器RM : 参与方
- 发起方会向协调者申请一个全局事务id,并保存到 ThreadLocal 中 (为什么要保存到 ThreadLocal 中?弱引用,线程之间不会发生数据冲突)
- Seata数据源代理发起方和参与方的数据源,将前置镜像和后置镜像写入到undo_log表中,方便后期回滚使用
- 发起方获取全局事务id,通过改写Feign客户端请求头传入全局事务id。
- 参与方从请求头中获取全局事务id保存到ThreadLocal中,并把该分支注册到SeataServer中。
- 如果没有出现异常,发起方会通知协调者,协调者通知所有分支,通过全局事务id和本地事务id删除undo_log数据,如果出现异常,通过undo_log逆向生成sql语句并执行,然后删除undo_log语句。如果处理业务逻辑代码超时,也会回滚。
4. SpringBoot如何整合Seata
- 引入依赖
- bin下的file文件和registry文件放入到每个项目中,并修改,分组名称要保持一致
- yml配置seata
- 引入DataSourceProxy配置文件
5. Seata和LCN的区别
Seata和LCN的思想是一样的,只不过LCN中采用的是假关闭,不会提交或者回滚事务,而Seata中是直接插入数据。两者的区别就是当发起方突然宕机了,LCN会发生死锁,而Seata不会,但是Seata会引起脏读。
- LCN实现分布式事务三种方案(模式):LCN、TCC、TXC
- Seata实现分布式事务四种方案(模式):AT(几乎等于LCN)TCC、SA、GAXA
